Основы реляционной алгебры
Реляционная алгебра базируется на теории множеств и является основой логики работы баз данных.
Когда я только изучал устройство баз данных и SQL, предварительное ознакомление с реляционной алгеброй очень помогло дальнейшим знаниям правильно уложиться в голове, и я постараюсь что бы эта статья произвела подобный эффект.
Так что если вы собираетесь начать свое обучение в этой области или вам просто стало интересно, прошу под кат.
Реляционная база данных
Для начала введем понятие реляцинной базы данных, в которой будем выполнять все действия.
Реляционной базой данных называется совокупность отношений, содержащих всю информацию, которая должна хранится в базе. В данном определении нам интересен термин отношение, но пока оставим его без строго определения.
Лучше представим себе таблицу продуктов.
таблица PRODUCTS
| ID | NAME | COMPANY | PRICE |
| 123 | Печеньки | ООО ”Темная сторона” | 190 |
| 156 | Чай | ООО ”Темная сторона” | 60 |
| 235 | Ананасы | ОАО ”Фрукты” | 100 |
| 623 | Томаты | ООО ”Овощи” | 130 |
Таблица состоит из 4х строк, строка в таблице является кортежем в реляционной теории. Множество упорядоченных кортежей называется отношением.
Перед тем как дать определение отношения, введем еще один термин — домен. Домены применительно к таблице это столбцы.
Для ясности, теперь введем строгое определение отношения.
Ключи в отношениях
В отношении требованием является то, что все кортежи должны различаться. Для однозначной идентификации кортежа существует первичный ключ. Первичный ключ это атрибут или набор из минимального числа атрибутов, который однозначно идентифицирует конкретный кортеж и не содержит дополнительных атрибутов.
Подразумевается, что все атрибуты в первичном ключе должны быть необходимыми и достаточными для идентификации конкретного кортежа, и исключение любого из атрибутов в ключе сделает его недостаточным для идентификации.
Например, в такой таблице ключом будет сочетание атрибутов из первого и второго столбца.
| COMPANY | DRIVER |
| ООО ”Темная сторона” | Владимир |
| ООО ”Темная сторона” | Михаил |
| ОАО ”Фрукты” | Руслан |
| ООО ”Овощи” | Владимир |
Видно, что в организации может быть несколько водителей, и чтобы однозначно идентифицировать водителя необходимо и значение из столбца “Название организации” и из “Имя водителя”. Такой ключ называется составным.
В реляционной БД таблицы взаимосвязаны и соотносятся друг с другом как главные и подчиненные. Связь главной и подчиненнной таблицы осуществляется через первичный ключ (primary key) главной таблицы и внешний ключ ( foreign key ) подчиненной таблицы.
Внешний ключ это атрибут или набор атрибутов, который в главной таблице является первичным ключем.
Этой подготовительной теории будет достаточно для знакомства с основными операциями реляционной алгебры.
Операции реляционной алгебры
Для понимания важно запомнить, что результатом любой операции алгебры над отношениями является еще одно отношение, которое можно потом так же использовать в других операциях.
Создадим еще одну таблицу, которая нам пригодится в примерах.
| ID | SELLER |
| 123 | OOO “Дарт” |
| 156 | ОАО ”Ведро” |
| 235 | ЗАО “Овоще База” |
| 623 | ОАО ”Фирма” |
Условимся, что в этой таблице ID это внешний ключ, связанный с первичным ключом таблицы PRODUCTS.
Для начала рассмотрим самую простую операцию — имя отношения. Её результатом будет такое же отношение, то есть выполнив операцию PRODUCTS, мы получим копию отношения PRODUCTS.
Проекция
Проекция является операцией, при которой из отношения выделяются атрибуты только из указанных доменов, то есть из таблицы выбираются только нужные столбцы, при этом, если получится несколько одинаковых кортежей, то в результирующем отношении остается только по одному экземпляру подобного кортежа.
Для примера сделаем проекцию на таблице PRODUCTS выбрав из нее ID и PRICE.
Синтаксис операции:
π (ID, PRICE) PRODUCTS
В результате этой операции получим отношение:
| ID | PRICE |
| 123 | 190 |
| 156 | 60 |
| 235 | 100 |
| 623 | 130 |
Выборка
Выборка — это операция, которая выделяет множество строк в таблице, удовлетворяющих заданным условиям. Условием может быть любое логическое выражение.
Для примера сделаем выборку из таблицы с ценой больше 90.
Синтаксис операции:
σ (PRICE>90) PRODUCTS
| ID | NAME | COMPANY | PRICE |
| 123 | Печеньки | ООО ”Темная сторона” | 190 |
| 235 | Ананасы | ОАО ”Фрукты” | 100 |
| 623 | Томаты | ООО ”Овощи” | 130 |
В условии выборки мы можем использовать любое логическое выражение. Сделаем еще одну выборку с ценой больше 90 и ID товара меньше 300:
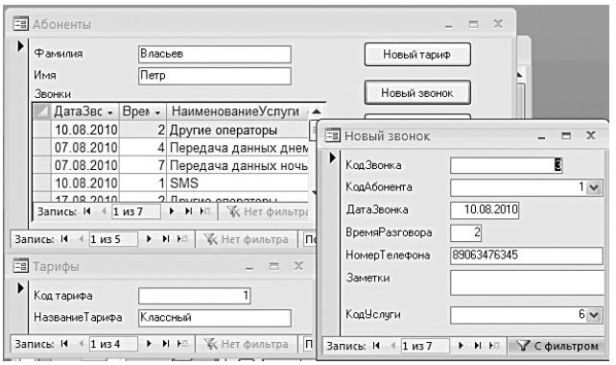
σ (PRICE>90 ^ ID π COMPANY σ (PRICE 123 Для примера использования этой операции представим себе необходимость выбрать продавцов с ценами меньше 90. Без произведения необходимо было бы сначала получить ID продуктов из первой таблицы, потом по этим ID из второй таблицы получить нужные имена SELLER, а с использованием произведения будет такой запрос: Формы предназначены для наглядного представления данных и существенно облегчают ввод и восприятие хранящейся в базе информации. Можно подготовить стандартную форму, использовать инструменты для детальной настройки формы произвольного вида, дополнить форму результатами вычислений. Формы являются основными средствами создания интерфейса пользователя – именно через формы можно управлять выполнением всего спектра задач приложения и автоматизировать действия пользователя. Для создания формы можно воспользоваться возможностями построения простых форм (табличная или форма «в столбец») или мастером форм либо разработать форму в режиме конструктора. Выбор способа создания формы зависит от квалификации пользователя и сложности разрабатываемой формы. Весьма плодотворным также оказывается комбинированный подход: сначала используется мастер формы, а затем полученная форма дорабатывается в режиме конструктора. Режим макета позволяет модифицировать структуру формы и одновременно видеть измененное представление данных. При любом способе создания формы для нее, прежде всего, определяется источник данных – таблица или запрос. Если форма основана на запросе, то он автоматически выполняется при открытии формы. К числу важных достоинств MS Access относится то, что работа с экранными формами универсальна и подобна работе с отчетами. Режим конструирования экранной формы аналогичен режиму конструктора отчета. Структура формы ориентирована на возможности представления табличных данных. Форма состоит из разделов, основные из которых – заголовок, примечание формы и область данных. Именно в области данных отображается информация, отличающая одну запись от другой, т. е. различные значения свойств объектов реального мира. Процесс проектирования формы в среде MS Access сводится к добавлению управляющих элементов и изменению их свойств. Можно добавить такие элементы управления, как надпись, поле, кнопка, флажок, переключатель, список, набор вкладок и др. (элементы управления показаны на рис.8.21). Помимо этого к форме можно подключать дополнительные элементы управления ActiveX, что значительно расширяет возможности представления данных. Каждый элемент управления обладает своим набором свойств, изменение которых приводит к изменению его вида и поведения, например, можно менять цвет, шрифт, изменять размеры элемента и т.п. Сама форма и ее разделы также рассматриваются как элементы управления и обладают настраиваемыми наборами свойств. Источником вычисляемого элемента, размещаемого в форме, является расчетная формула, построенная по правилам формирования выражений. Для упрощения записи выражений можно воспользоваться Построителем выражений. На рис.8.22 показана составная форма Абоненты, которая содержит командные кнопки для вызова двух других форм. Основная форма Абоненты построена на многотабличном запросе, и данные, высвечиваемые в этой форме, организованы в соответствии с главной таблицей Абоненты. Верхняя часть формы показывает информацию о некотором абоненте. Подчиненная форма Звонки отображает в табличном виде информацию о звонках выбранного абонента. Перемещение в форме Абоненты возможно по абонентам или по звонкам. При переходе к следующему абоненту изменяются строки формы Звонки, в которые выводится информация, относящаяся уже к другому абоненту. Нажатие на кнопку Новый звонок вызывает загрузку формы, которая высвечивает данные только по выбранному абоненту, на что указывает выполняемая в форме фильтрация (рис.8.22). Это достигается за счет того, что MS Access позволяет отображать в объекте базы, вновь загружаемом при помощи командной кнопки, или все отобранные в запросе записи, или записи, которые относятся к субъекту, выбранному в основной форме. По сути, из единой формы Абоненты реализовано управление данными, находящимися в системе взаимосвязанных таблиц. Структура формы Новый звонок соответствует структуре таблицы Звонки. Но можно построить форму, в которой поля таблицы будут расположены в любом порядке. Навигация по записям источника данных для всех видов форм подобна навигации в таблице, но имеет и дополнительные возможности: использование линеек прокрутки и пиктограмм навигации, переход по записям путем изменения номера текущей записи, которое находится в нижней части окна. Можно перемещаться по записям главной и подчиненной форм. Различные свойства полей и формы в целом помогают заблокировать внесение изменений во все или некоторые поля базового источника, реализуя таким образом ограничение доступа к данным. Для ввода новой записи форма должна быть открыта для модификации данных (обычный режим формы). В этом режиме новая запись всегда добавляется в конец высвеченных данных после установки на пустую запись. Переключение в режим ввода новых записей высвечивает бланк записи с пустыми или заполненными по умолчанию значениями полей данных. Режим открытия формы можно изменить при помощи специального свойства формы. В форме операции поиска и сортировки можно выполнять в основном теми же способами, что и в таблицах. Способы фильтрации в форме совпадают с аналогичными возможностями для таблиц. MS Access позволяет создавать формы в виде сводных таблиц или сводных диаграмм, которые строятся абсолютно аналогично построению этих объектов в MS Excel. Доступны те же типы диаграмм, что и в MS Excel. Диспетчер кнопочных форм можно вызвать нажатием одноименной кнопки Кнопочная форма состоит из страниц, каждая из которых имеет название и, в свою очередь, является формой. Одна страница кнопочной формы считается основной или главной: именно она высвечивается при открытии кнопочной формы. На каждой странице кнопочной формы располагаются кнопки и их обозначения. Для каждой кнопки определены некоторые действия, с нею связанные. Это может быть высвечивание следующей страницы кнопочной формы, отображение формы или отчета, выход из приложения и т.д. Для управления кнопочной формой в базе данных автоматически создается таблица Switchboard Items (рис.8.25), каждая строка которой описывает страницу формы или открываемые формы, отчеты и т.д. На Хабре и за его пределами часто обсуждают реляционную алгебру и SQL, но далеко не так часто акцентируют внимание на связи между этими формализмами. В данной статье мы отправимся к самым корням теории запросов: реляционному исчислению, реляционной алгебре и языку SQL. Мы разберем их на простых примерах, а также увидим, что бывает полезно переключаться между формализмами для анализа и написания запросов. Зачем это может быть нужно сегодня? Не только специалистам по анализу данных и администраторам баз данных приходится работать с данными, фактически мало кому не приходится что-то извлекать из (полу-)структурированных данных или трансформировать уже имеющиеся. Для того, чтобы иметь хорошее представление почему языки запросов устроены определенным образом и осознанно их использовать нужно разобраться с ядром, лежащим в основе. Об этом мы сегодня и поговорим. Большую часть статьи составляют примеры с вкраплениями теории. В конце разделов приведены ссылки на дополнительные материалы, а для заинтересовавшихся и небольшая подборка литературы и курсов в конце. Selection является по сути горизонтальным фильтром строк, т.е., можно представить, что мы идем по каждой строке и оставляем только те, что удовлетворяют условию Реляционная алгебра является расширением классического набора операторов над множествами (отношение — это множество упорядоченных кортежей; заметьте, что это совсем не равно упорядоченному множеству кортежей). Пусть у нас есть таблица StudentMark(Name, Mark, Subject, Date) – тогда кортеж (Вася, 5, Информатика, 05.10.2010) является упорядоченным – сначала строка Name на первой (ок, или нулевой) позиции, целое число на второй, строка на третьей и дата на четвертой. При этом сами упорядоченные кортежи (Name, Mark, Subject, Date) не упорядочены «внутри» отношения. (B\A; A — слева, B — справа) Мы будем работать со следующей схемой Далее рассмотрим несколько простых задач на реляционную алгебру. Задача первая. Вывести имена всех работников 5го департамента, которые работают более 10 часов в неделю над проектом Х. (Промежуточные результаты можно «сохранять» в новых отношениях, но это не обязательно.) Задача вторая. Вывести имена всех работников, которыми напрямую руководит Франклин Вонг (и найти небольшую ошибку в решении ниже) Задача третья потребует использования нового оператора — «агрегация». Рассмотрим его на примере: Для каждого проекта вывести название и общее число часов в неделю, которое все работники тратят на этот проект. Заметим, что запрос имеет вид a F b (A), где a, b — колонки, A — отношение, а – агрегационная функция (например, SUM, MIN, MAX, COUNT, etc). Читается следующим образом: для каждого значения в колонке а, посчитай b. То есть одному значению в колонке a может соотвестовать несколько строк, поместим значения колонки b из этого множества строк в функцию и создадим новый атрибут fun_b с соотвествующим значением. Данный запрос не выразим в «классической» реляционной алгебре (без оператора агрегации F). То есть, нельзя написать единственный запрос, который бы для любой базы данных, удовлетворяющей схеме, выдавал бы правильный ответ. Откуда в точности следует данные результат мы разберем позднее, сейчас можно лишь отметить, что запросы с агрегацией принадлежат более высокому классу вычислительной сложности. Мы рассмотрим и проанализируем более интересные примеры задач далее в статье. Там же небольшая подборка задач на реляционную алгебру с решениями доступна здесь В данной части мы поговорим о SQL (Structured Query Language) и покажем, как SQL соответствует реляционной алгебре на простых примерах. Рассмотрим самую первую задачу еще раз: Задача первая. Вывести имена всех работников 5го департамента, которые работают более 10 часов в неделю над проектом Х. Классическое решение выглядит следующим образом: Альтернативно можно написать вот так: Или совсем альтернативно: (далее решения не убраны под спойлеры) На втором решении мы видим отчетливую аналогию c реляционной алгеброй: Теперь используем равенство для join и увидим аналогию между SQL и реляционной алгеброй в первом решении Как бы это не было иронично, но SELECT в SQL — это project (π; проекция) в реляционной алгебре. Теперь рассмотрим задачу с агрегацией и сравним её с решением на реляционной алгебре: Более интересные задачи мы рассмотрим далее в статье (также небольшая подборка здесь), а сейчас рассмотрим еще один формализм запросов. Внимательный читатель сейчас мог бы воскликнуть: для чего козе баян? Нам тут что не хватает двух формализмов для написания запросов, к чему третий? Реляционное исчисление — это адаптация логики первого порядка (FOL: first order logic) для написания запросов. FOL является одним из самых хорошо изученных формализмов математики и даёт возможность использовать уже созданный теоретический аппарат и классические результаты для анализа и написания запросов. Многие результаты в сложности, (не)выразимости и формировании запросов пришли в базы данных из логики, именно благодаря реляционному исчислению, поэтому и стоит ознакомиться с данным формализмом. Для разбора и рассказа о реляционном исчислении нам потребуется логика первого порядка, освежить знания о которой можно тут. Пусть φ(Х) — формула первого порядка, а X — это свободные переменные, т.е., они не квантифицированы (∀ – квантор всеобщности, ∃ – квантор существования), тогда запрос в реляционном исчислении задает множество: Рассмотрим простые примеры, на которых и разберем формализм: Пусть R – отношение с тремя атрибутами a,b,c; тогда перепишем следующий запрос реляционной алгебры: Переводя на простой язык r — это кортеж в R (то есть строка с атрибутами, значения которых можно получить через точку по имени, i.e., r.a — атрибут а кортежа r (строки) в отношении R (таблице)). Как мы видим никаких кванторов здесь нет, так как r — на выходе запроса и должен быть свободным кортежем. Рассмотрим еще один простой пример: R(a,b,c) ∗ S(c,d,e), где * — это natural join, т.е. join по имени – в качестве условия объединения берут атрибуты с одинаковым именем. Если бы s.D и S.e не было среди выходных параметров, запрос бы имел следующий вид: Мы были бы обязаны поставить квантор существования, так как S содержится только в «теле» запроса. Составляя подобные запросы всегда следует быть внимательным с квантором всеобщности, если мы запишем следующее выражение (исключительно в качестве иллюстрации): То, данный запрос всегда будет возвращать пустое множество, так как для того, чтобы условия запроса было выполнено необходимо, чтобы каждый кортеж в мире длины три принадлежал S и имел в качестве значения последнего атрибута «банан». Обычно вместе с квантором всеобщности используют импликацию «=>», мы можем переписать запрос следующим образом: Если s принадлежит S и значения C совпадает с C в R, тогда последний атрибут должен иметь значение «банан». Здесь можно найти краткую подборку задач на реляционное исчисление с решениями. Говоря простым языком, теорема Кодда звучит так: все три формализма SQL, реляционная алгебра и реляционное исчисление равны. Вот тут много теории для заинтересовавшихся То есть любой запрос выраженный на одном языке может быть переформулирован на другом. Данный результат прежде всего удобен тем, что позволяет использовать наиболее удобный формализм для анализа запроса, а во вторых он связывает декларативные языки SQL и реляционное исчисление с императивной реляционной алгеброй. То есть, транслируя запрос из SQL в реляционную алгебру, мы уже получаем способ выполнения запроса (и его оптимизации). Запросы, которые состоят из select(σ)-project(π)-join(⋈) сегмента реляционной алгебры называют conjunctive queries (ок, я опустил переименование, считаем его неявно присутствующим). Если вы дочитали до этой строки попробуйте решить следующую задачу используя только эти три оператора (ну и отношения конечно же): Задача. Выведите имена всех работников, которые работают над каждым проектом. Подумайте какому сегменту SQL и реляционного исчисления относится данный класс реляционной алгебры. Существует несколько различных способов измерить вычислительную сложность выполнения запроса, между ними часто путаются поэтому выпишем определения и их названия: Пусть Q — запрос, D — база данных, и нужно вычислить Q(D) Важные факты: сложность SQL по данным (и всех остальных) принадлежит классу AC0 – это очень хороший класс сложности, т.е., запросы можно вычислять очень эффективно. С теоретической точки зрения можно взглянуть на вот эту картинку: AC0 лежит внутри NL (точнее даже внутри одного из «слоёв» NC внутри NL). Рассмотрим следующий интересный вопрос, связанный с вычислительной сложностью: пусть f – функция выполнимости формулы, то есть для каждого запроса она говорит, существует ли база данных такая, что Q(D) истинно. Из теоремы Кодда мы знаем, что реляционная алгебра и SQL эквиваленты реляционному исчислению. А значит, вычисление f – эквивалентно проблеме останова (SAT для логики первого порядка невычислим). Отсюда: не существуют алгоритма, который бы для произвольного SQL запроса мог определить его непротиворечивость. Для заинтересовавшихся также рекомендую: теорема Трахтенброта CQ являются одним из самых изученных классов запросов так как они составляют всю основную массу запросов к базам данных (я видел на одной презентации цифру в 90%, но не могу сейчас найти источник). Поэтому рассмотрим подробнее их сложность и докажем, что на самом деле их комбинированная сложность равна NP, т.е. задача является NP полной. (Про NP полному можно почитать вот тут и тут.) Для этого запишем произвольный CQ запрос в реляционном исчислении в виде: Где [.] – опциональность квантора. Почему такое представление всегда допустимо? Потому что project здесь всегда может быть выражен через X т.е. Чтобы показать, что задача принадлежит классу NP-полных, нужно сделать две вещи Первое условие выполняется тривиально: так как значения отношений конечны (т.е. множество всевозможных значений), то мы можем недетерминированно «угадать» функцию Покажем, что задача о раскраске графа сводится к задаче выполнимости CQ запроса. Пусть D состоит из одного отношения edge = <(red,green),(green,red), (blue, red), (green,blue) … >— всех возможных правильных раскрасок графа, таких что никакие две вершины не имеют одинакового цвета. Пусть исходный граф задан в виде множества ребер Тогда, запишем следующий запрос То есть каждой дуге в исходном графе в запросе будет соответствовать отношение edge с соответствующими аргументами. Если запрос вернул пустой кортеж, то значит, что существует такая функция Вопрос со звёздочкой: из сегмента select-project-join выкидываем project, как изменится вычислительная сложность? Определения сложности по данными и по запросу также проливают свет на один известный результат — в классическом SQL (без with) транзитивное замыкание невыразимо при фиксированном запросе т.е. нельзя написать один запрос такой, что для любой базы данных он вычислял бы замыкание предиката. То есть, если у нас есть граф сохраненный в виде отношения edge, то нельзя написать один фиксированный запрос, который бы для произвольного графа вычислял отношение достижимости. Хотя интуитивно кажется, что такой запрос явно должен лежать в классе СQ. Это можно заметить либо из вычислительной сложности «по данным», либо гораздо более конструктивно и интересно это следует из теоремы о компактности и теоремы Кодда (SQL = First Order Logic). Доказательство нетривиально и его можно пропустить без потери понимания дальнейшего материала. Теорема о компактности: бесконечное множество формул выполнимо (имеет модель — интерпретацию, в которой все формулы верны), тогда и только тогда когда любое конечное подмножество этого множества выполнимо. Гёдель: логика первого порядка компактна. Доказательство от противного, пусть T(a,b) — есть путь из а в б. P_n(a,b) — это путь из а в b длины n. Тогда P_n(a,b) — из а нет пути в b длины n. Возьмем следующее конечное множество P_k(a,b)> — оно выполнимо, так как возьмем путь длины k+1 и T(a,b) выполнено и все P_k тоже выполнены. Более того любое конечное множество такого вида выполнимо, а значит по теореме о компактности и их бесконечное объединение должно быть выполнимо. P_k — должно быть верно для ЛЮБОГО k, то есть не должно существовать пути никакой длины из а в b, а для выполнения T(a,b) такой путь должен существовать. Противоречие. Q.E.D. Если запрос не фиксирован, то задача становится тривиально разрешимой. Пусть у меня всего k ребер в базе данных, значит самый большой путь не более k, значит можно в явном виде записать запрос, как объединение путей длины 1, 2,… k и таким образом получить запрос вычисляющий достижимость в графе. Теперь вернемся к задаче предложенной ранее: Выведите имена всех работников, которые работают над каждым проектом. Почему эта задача не имеет решения в классе CQ мы можем понять, определив ключевые свойства самого запроса и класса CQ. Определение, запрос Q называется монотонным, тогда и только тогда когда, для любых двух баз данных Наблюдение: CQ — класс монотонно возрастающих запросов. Представим произвольный CQ запрос Q — он состоит из select-project-join. Покажем, что каждый из них является монотонным оператором: Пусть мы добавили еще одну запись в D select — фильтрует записи по вертикали, если новая запись удовлетворяет запросу, то множество ответов увеличивается, если нет остается прежним. project — не влияет на дополнительный кортеж join — если соответствующая запись имеется и во втором множестве, то ответное множество расширится, иначе останется прежним. Суперпозиция монотонных операторов монотонна => CQ — класс монотонных запросов. Вопрос: является ли исходная задача монотонной? На самом деле нет. Пусть у нас только один работник Петя, который работает над двумя проектами А и Б, и всего у нас 2 проекта А и Б, значит Петя должен быть в выдаче запроса. Пусть мы добавили третий проект C => теперь Пети нет в ответе и ответное множество пусто, а значит запрос не монотонен. Отсюда логически следует следующий вопрос: что нужно добавить к select-project-join, чтобы задача решалась? Это что-то должно быть немонотонным! Как конечно же читатель догадался — разница множеств. Его несимметричность как бы подсказывала нам и выделяла его с самого начала. Однако прежде, чем писать решение сделаем еще одно наблюдение: если контр-примера к утверждению не существуют, то это утверждение всегда верно. Формально: В задаче мы видим в явном виде квантор «для всех» и мы можем его эмулировать используя двойное отрицание, то есть перефразируем запрос следующим образом: вывести имена всех сотрудников для которых не существуют проекта, над которым они бы не работали Этот же запрос выглядит невероятно просто, если бы у нас был Также трансформация SQL в реляционную алгебру позволяет оптимизировать выполнение запроса. Рассмотрим простой пример: Задача Простое решение выглядит следующим образом: Которое можно переписать в реляционную алгебру следующим образом: Первая оптимизация — нужно использовать select как можно раньше, тогда Декартово произведение получит на вход отношения меньшего размера: Select c равенством константе сильное ограничение, поэтому его нужно вычислять и соединять как можно раньше: Сворачиваем Декартово произведение и select в join (который реализован эффективно с индексами и специализированными структурами данных) Опускаем project как можно ниже, чтобы только необходимая информация была передана наверх по дереву Мартин Грабер — SQL — довольно простые и детальные объяснения работы алгоритмов и синтаксиса SQL Хабра-статьи про P-NP — ознакомительный материал часть первая и вторая Мои слайды по теме (исключительно полезно из-за примеров решений задач в разных формализмах — местами смесь голландского и английского) Неплохие слайды по теории (нетривиальный теоретический материал)Печеньки ООО ”Темная сторона” 190 123 OOO “Дарт” 156 Чай ООО ”Темная сторона” 60 156 ОАО ”Ведро” 123 Печеньки ООО ”Темная сторона” 190 156 ОАО ”Ведро” 156 Чай ООО ”Темная сторона” 60 123 OOO “Дарт” Системы управления базами данных
Конструирование экранных форм для работы с данными

Создание пользовательского приложения
 , расположенной на вкладке Работа с базами данных. Этот инструмент помогает сконструировать кнопочные формы различных уровней, т.е. помогает создать приложение базы данных, с которым впоследствии может работать любой человек. Кроме того, разработчик приложения может указать системе, какую форму следует загрузить при открытии базы данных, и тем самым полностью скрыть интерфейс СУБД.
, расположенной на вкладке Работа с базами данных. Этот инструмент помогает сконструировать кнопочные формы различных уровней, т.е. помогает создать приложение базы данных, с которым впоследствии может работать любой человек. Кроме того, разработчик приложения может указать системе, какую форму следует загрузить при открытии базы данных, и тем самым полностью скрыть интерфейс СУБД.
Заметки о SQL и реляционной алгебре

Реляционная алгебра
Основные операторы
 — само отношение А (отношение здесь синонимично с таблицей и предикатом) является выражением реляционной алгебры, более того, так как это алгебра, любое выражение реляционной алгебры возвращает отношение (свойство замыкания операторов)
— само отношение А (отношение здесь синонимично с таблицей и предикатом) является выражением реляционной алгебры, более того, так как это алгебра, любое выражение реляционной алгебры возвращает отношение (свойство замыкания операторов)Selection (выборка; ограничение)
 — selection (выборка; ограничение), A — отношение (предикат, таблица),
— selection (выборка; ограничение), A — отношение (предикат, таблица),  – булева формула, по которой происходит отбор строк (кортежей, записей, etc). Простой пример для наглядности:
– булева формула, по которой происходит отбор строк (кортежей, записей, etc). Простой пример для наглядности: Projection (проекция)
 — projection (проекция) на атрибуты A, B, …. Возвращает таблицу, в которой остаются только колонки (атрибуты) A, B, …. Простой пример ниже. По сути является фильтром по атрибутам т.е. это в некотором смысле вертикальный фильтр.
— projection (проекция) на атрибуты A, B, …. Возвращает таблицу, в которой остаются только колонки (атрибуты) A, B, …. Простой пример ниже. По сути является фильтром по атрибутам т.е. это в некотором смысле вертикальный фильтр. Переименование
 — переименовывает колонку a в b в отношении A (атрибут, аргумент предиката, etc); два чая тому господину, который покажет, что алгебра строго более выразима с оператором переименования (нужно привести пример запроса, который не выразим без этого оператора, но выразим с
— переименовывает колонку a в b в отношении A (атрибут, аргумент предиката, etc); два чая тому господину, который покажет, что алгебра строго более выразима с оператором переименования (нужно привести пример запроса, который не выразим без этого оператора, но выразим с  )
)Декартово произведение
 — Декартово произведение двух отношений, большое отношение из всевозможных сочетаний строк в A и B.
— Декартово произведение двух отношений, большое отношение из всевозможных сочетаний строк в A и B. Операции над множествами
Объединение
 — объединение всех строк в A и B, ограничение — одинаковые аттрибуты
— объединение всех строк в A и B, ограничение — одинаковые аттрибуты Пересечение
 — пересечение строк, такое же ограничение
— пересечение строк, такое же ограничение Разница множеств
 — B минус A, все строки, что присутствуют в B, но не присутствуют в A, такое же ограничение
— B минус A, все строки, что присутствуют в B, но не присутствуют в A, такое же ограничение Вспомогательные операторы
 — join (соединение); join соединяет две записи таблиц A и B, при условии, что для этих двух записей выполнено условие φ.
— join (соединение); join соединяет две записи таблиц A и B, при условии, что для этих двух записей выполнено условие φ. Задачи для разогрева
(Схема взята из книги: Elmasri, Navathe – Fundamentals of Database systems; на всякий: крайне НЕ рекомендую книгу; см подборку в конце) Проводим аналогию между SQL и реляционной алгеброй
Реляционное исчисление
 в реляционном исчислении как:
в реляционном исчислении как:Равенство формализмов (теорема Кодда)
Conjunctive Queries (CQ)
Вычислительная сложность
Сложность Conjunctive Queries
 , join выражен через равенство переменных в
, join выражен через равенство переменных в  , а select через условия на в теле запроса.
, а select через условия на в теле запроса. такую, что делает истинными каждое отношение под кванторами существования.
такую, что делает истинными каждое отношение под кванторами существования. , которая отображает
, которая отображает  , причем никакие две вершины не будут иметь одинаковую расцветку (следует из определения D). Ч.Т.Д.
, причем никакие две вершины не будут иметь одинаковую расцветку (следует из определения D). Ч.Т.Д.Транзитивное замыкание
Кодд: SQL — логика первого порядкаСвойства и анализ запросов
 верно, что
верно, что  . То есть увеличение базы данных может только увеличить количество кортежей на выходе или останется прежним.
. То есть увеличение базы данных может только увеличить количество кортежей на выходе или останется прежним. — не существует х, такой что p(x) неверен.
— не существует х, такой что p(x) неверен.  (а он есть в реляционном исчислении):
(а он есть в реляционном исчислении):Пример использования RA для оптимизации запросов
Вывести все номера проектов, в которых бы работал сотрудник с фамилией Шмидт в качестве менеджера департамента, управляющего этим проектом. Литература, материалы и слайды



