Типы данных, паттернг матчинг и функции
Сегодня, как обещал, вкратце расскажу про пользовательские типы данных, определения функций и сопоставления с образцом.
Предисловие
gchi> :cd c:/some/haskell
ghci> :l file.hs
[1 of 1] Compiling Main ( file.hs, interpreted )
Ok, modules loaded: Main.
ghci>
Наверняка есть удобное IDE, автоматом делающее релоад при изменениях, но я пользуюсь просто редактором с подсветкой.
Типы данных
data List a = Null | Cons a ( List a )
которые элементарно реализуются
Определение функций и паттерн матчинг (сопоставление с образцом)
length Null = 0
length ( Cons _ xs ) = 1 + length xs
someFunc ( Cons 5 ( Cons _ ( Cons 3 ( Cons _ Null ) ) ) ) = True
someFunc _ = False
someFunc3 ( x : xs )
| isSomePredicate x = xs
| x == 0 = []
| otherwise = ( x : xs )
ghci> listHead Null
*** Exception: No match in record selector Main.listHead
ghci> head []
*** Exception: Prelude.head: empty list
listHead Null = error «listHead: empty list»
listHead ( Cons x _ ) = x
ghci> listHead Null
*** Exception: listHead: empty list
listMap f Null = Null
listMap f ( Cons x xs ) = Cons ( f x ) ( listMap f xs )
listFilter p Null = Null
listFilter p ( Cons x xs )
| p x = Cons x ( listFilter p xs )
| otherwise = listFilter p xs
Операторы определяются так же, как и функции, но если они используются в префиксной форме, то должны обрамляться скобками.
В данном примере записи корректны:
Null @++ right = right
( @++ ) left Null = left
( Cons l ls ) @++ right = Cons l ( ls @++ right )
toList Null = []
toList ( Cons x xs ) = x : ( toList xs )
fromList [] = Null
fromList ( x : xs ) = Cons x ( fromList xs )
В следующий раз я расскажу про классы типов и про некоторые стандартные из них.
Проблемы матчинга и как можно с ними бороться
Добрый день! Меня зовут Алексей Булавин, я представляю центр компетенций Сбертеха по Big Data. Представители бизнеса, владельцы продуктов и аналитики часто задают мне вопросы по одной и той же теме — матчинг. Что это такое? Зачем и как его делать? Особенно популярен вопрос «Почему он может не получиться?» В этой статье я постараюсь на них ответить.

Начнем с бытового примера. У меня есть маленький сын. Недавно он освоил мобильный телефон и теперь любит таскать его с собой, чтобы, как взрослый, непринужденно позвонить кому-нибудь когда вздумается и поговорить на какую-нибудь «очень важную» тему. Звонит он только маме, папе и бабушке. Больше всего достается бабушке: порой он по 10 раз в день звонит ей, чтобы рассказать, что с ним произошло 5 минут назад.
В детском саду у него есть друг Денис, и у Дениса тоже есть мобильный телефон. Встретившись, они как взрослые меряются телефонами, но никогда не звонят друг другу. Я как-то спросил сына:
— Почему бы тебе не позвонить и не поболтать с другом о том о сем, обсудить свои дела?
— Папа, мне это совсем не нужно, мы и так встречаемся в саду каждый день и, если что, поговорим там. Дела подождут.
Мне стало интересно, как же так? Выяснилось, что просто ни он, ни Денис не знают своего собственного номера телефона и не могут ими обменяться. Налицо отсутствие связи из-за отсутствия ключей.
Что же такое матчинг?
Новые средства взаимодействия в обществе порождают новые возможности, более тесно связывают людей, а системам указывают об их связанности. Матчинг — это один из типов связанности, который указывает на отношения субъекта с самим собой. Например, когда на разных досках объявлений продается одна и та же машина, а мы хотим связать и воспринимать эти объявления вместе, как единое целое.
Зачем нужен матчинг?
Информация сегодня представляет ценность, которую можно монетизировать. Соответственно, дополнительная информация дает дополнительную ценность, увеличение прибыли или сокращение издержек — с помощью разработки новых фич, качественного изменения существующих или вообще создания новых продуктов.
Как правило, наш продукт четко связан с теми или иными объектами, знания по которым мы хотим обогащать. Чем больше дополнительной информации из новых источников мы получаем, тем актуальней становится задача объединения информации из всех источников в единое информационное пространство, как будто это атрибуты одной системы.
Трудности матчинга
Добыть и связать данные — вроде бы стандартная техническая задача. Но из-за ряда проблем это бывает затруднительно или вовсе невозможно:

Получается, что связать объекты двух систем между собой по ключу бывает либо невозможно, либо процент и качество связанности оказываются ниже желаемого уровня. Можно попробовать собрать ключ как комбинацию нескольких информационных полей, составной ключ. Но здесь возникают новые трудности:
Кроме того, для информационных полей в составном ключе характерны трудности, которые мы упоминали ранее. Поля, входящие в составной ключ, тоже могут быть не уникальны, ошибочны, преднамеренно искажены и не постоянны.
Количество vs качество
Как же победить перечисленные выше трудности и добиться 100% матчинга? Начать стоит с вопроса: а действительно ли нужно достигать таких высоких уровней качества? Может, для решения бизнес-задачи вполне достаточно 70%?
Есть у нас составной ключ, состоящий из набора атрибутов. Каждый из них с некоторой вероятностью будет заполнен и с некоторой вероятностью подойдет для применения в качестве элемента ключа. Вероятность что весь составной ключ будет нормален — это произведение всех вероятностей по всем атрибутам ключа. Все это еще нужно умножить на вероятность того, что объект в принципе присутствует в двух системах. Тогда мы получим вероятность матчинга. А умножив ее на общее число сущностей, получим количественный прогноз по сопоставлению.
Чем меньше атрибутов в составном ключе, тем вероятность матчинга выше и при этом ближе к вероятности того, что объект есть в двух системах. Но количество сопоставлений при этом растет и чаще всего превышает прогноз. Это связано с тем, что с уменьшением числа атрибутов в составном ключе растет вероятность ошибочного сопоставления.
Проще говоря, с уменьшением количества атрибутов в составном ключе растет как число объектов сопоставленных правильно, так и число сопоставленных ошибочно. Как бы количество борется против качества. И в зависимости от бизнес-задачи можно выбрать стратегию матчинга, смещающую результат либо в сторону количества, либо в сторону качества.
Обогащение, фильтрация, нормализация
А можно ли увеличить качество и количество одновременно? Конечно можно. Для этого нужно потратить больше, а иногда и намного больше ресурсов на дополнительную обработку данных.
«Дырки» в данных можно заполнять, получая их из других полей источника. Город локации можно получить из кода телефонного номера, ИНН, кода региона. Пол можно получить из имени и фамилии или по анализу авторского текста. Алгоритмов обогащения достаточно много.
Далее данные следует пропускать через фильтры. Фильтры могут быть как стандартные, так и специфические, связанные с особенностями наполнения и трансформации данных конкретного источника. Например, к стандартным можно отнести фильтр, убирающий непечатные символы, дубли, задвоения символов, скобки, кавычки, пробелы.
К специфичным фильтрам можно отнести обнаружение и замену символов другой языковой раскладки, которые выглядят одинаково визуально в обоих языках — например, буква О в английской раскладке в имени Оля. Или обнаружение и замену символов другой языковой раскладки, которые звучат одинаково или почти одинаково в обоих языках (Света и Sвета).
К нормализации можно отнести перевод на другой язык, транслитерацию, приведение к шаблону заполнения (название, марка, телефон, адрес, пол), а также замену коротких названий на полные, замену сленга и уменьшительно-ласкательных форм.
Даже при одном составе ключа для разных источников данных зачастую следует использовать разные критерии. Это связано с тем, как конкретный источник заполняется данными. Чтобы правильно подобрать критерии, желательно собрать и проанализировать статистику по заполнению полей источника. На улучшение качества может повлиять применение коэффициента частотности по полю в источнике (например, для марки машины, фамилии), коэффициента «емкости» (например, для названия населенного пункта в зависимости от того, насколько большой этот населенный пункт по количеству жителей).
При одновременном комбинированном использовании разных ключей матчинга можно применить коэффициенты в качестве условия использования того или иного ключа. Таким же образом можно задействовать и иные критерии, например, заполненность того или иного поля. Комбинировать матчинги по разным ключам между одними и теми же источниками можно и без применения условий — результат бывает вполне приемлемый.
Другие матчинги
Есть и другие алгоритмы матчинга, которые иногда кардинально отличаются от перечисленных выше. Например, матчинг по слабому ключу в условиях связи с другим объектом, уже проматченным по сильному ключу, если емкость такой связи по определению маленькая.
Приведем пример. У любой машины или квартиры за всю ее историю, в среднем, имеется от 1 до 5 владельцев. Если в двух системах объект квартиры или машины проматчен по сильному ключу, то субъекта — владельца этой квартиры, явно с ней связанного — можно матчить по любому самому слабому параметру, например фамилии и имени.
Объекты любой социальной сети или подобной ей структуры данных с большим числом устойчивых связей можно матчить по слабым ключам, принадлежащим не самому объекту матчинга, а его окружению. Сами объекты матчинга могут иметь в дополнение собственный слабый ключ, а могут не иметь. Фактически алгоритмизируется утверждение древнегреческого поэта Еврипида: «Скажи мне, кто твои друзья, и я скажу тебе, кто ты».
Для двух источников с одной или несколькими фотографиями объектов, которые явным образом связаны с их идентификаторами в источниках, можно применить матчинг по фотографиям. На фото выделяются объекты или лица и сравниваются с такими же объектами или лицами в другом источнике. По сути, по такому принципу работают нейросетевые сервисы типа «Is your portrait in a museum?» от Google: они матчат лицо с загруженной вами фотографии с лицами средневековых людей на портретах музеев. Критерий для матчинга специально выбран мягким, чтобы получалось отдаленное, но достаточное сходство.
При наличии большого числа авторской текстовой информации в разных источниках можно попробовать алгоритмы text mining, чтобы связать авторов. Это что-то вроде анализа почерка, только анализируется не форма написания, а содержание текста.
Big data
Чтобы повышать качество матчинга, требуется применять различные алгоритмы, которые в свою очередь требуют много ресурсов. Чем больше алгоритмов, тем больше ресурсов требуется. А если данных много, они постоянно изменяются, а считать их нужно быстро и недорого?
Скорее всего, хранить, обрабатывать и матчить данные традиционными способами не получится. Стоит подумать о bigdata-инфраструктуре. Таких решений сейчас уже довольно много, от разных вендоров и на любой кошелек.
В Сбербанке, например, матчинг внутрикорпоративных данных реализован как компонент data lake на Hadoop, Spark и HBase. Это решение позволяет обрабатывать разнородные неструктурированные данные большого объема, запускать вычисления на большом кластере, где хранятся данные без накладных расходов. При этом используется опенсорсный софт и commodity-сервера, что делает решение достаточно дешевым и эффективным для такого класса задач. Про Big Data на Hadoop написано много. Мне, например, вполне нравится, как это сделано у DataArt.
Наш MatchBox
MatchBox — это система для автоматической нормализации и матчинга, которую мы используем в data lake Сбербанка. Она была недавно разработана в центре компетенций Big Data Сбертеха.
MatchBox в основном используется для построения и поддержания в актуальном состоянии единого семантического слоя данных и единого профиля клиента. Система дает возможность автоматически объединять информацию из большого числа источников в единую информационную суперсущность, встраиваться в процесс обновления информации источников. Это обогащает знания о текущих и потенциальных клиентах банка: их социально-демографических, психологических, поведенческих особенностях и потребительских предпочтениях.
MatchBox работает с данными любого качества, использует библиотеки с провалидированными алгоритмами нормализации и матчинга, имеет для этого конфигуратор пользовательских правил, работает в полностью автоматическом режиме по событию, расписанию или как сервис. MatchBox умеет масштабироваться, и количество регулярно обрабатываемых источников ограничивается только ресурсными квотами кластера.
Вот чего нам удалось добиться благодаря внедрению MatchBox:
Я надеюсь, что статья поможет ответить на вопросы, связанные с матчингом, продвинуться в понимании собственных проблем работы с данными и найти подходы к их решению.
Мэтчинг онлайн и оффлайн-покупателей
Один из главных последних трендов e-commerce — оффлайн-магазины, даже не очень большие, выходят в онлайн. Это один из факторов общего роста электронной коммерции за последние пять лет.
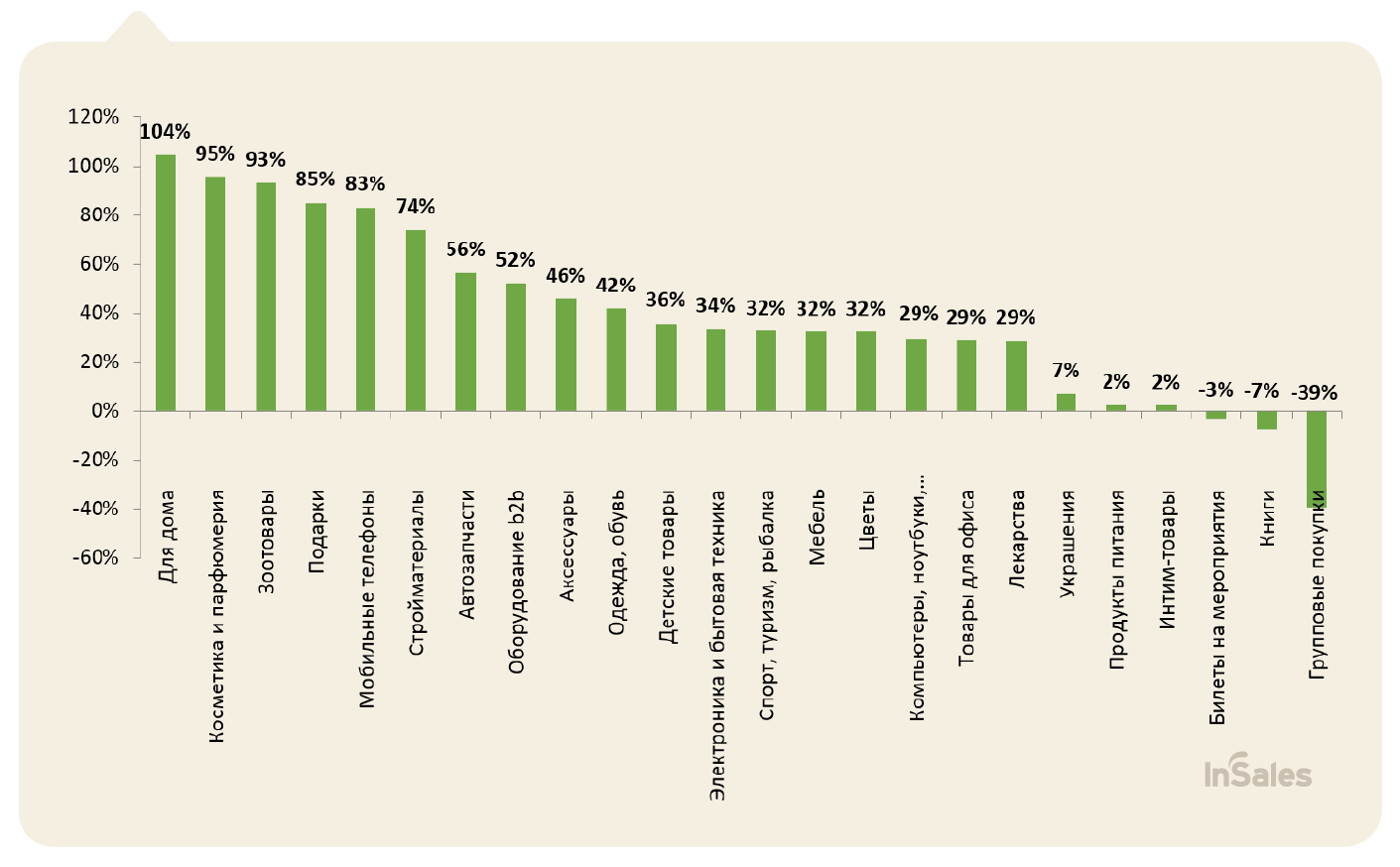
Когда оффлайновый магазин открывает представительство в сети — сразу же возникает потребность сопоставлять данные о покупателях в обычном и интернет-магазине. Поговорим об этом.
Что такое мэтчинг данных
Сопоставление данных (мэтчинг) — объединение наборов данных, полученных из разных источников, в единые профили покупателей.
| Онлайн-профиль | Мобильный профиль | Оффлайн-профиль |
| — Демографические данные. — Физиологические параметры. — ID пользователя. — Электронная почта. — Телефон. — История покупок. — История просмотров. — Статистика по email-рассылкам и т.д. | — Текущая геопозиция. — История геопозиций. — Текущий часовой пояс. — Бодрствует или спит пользователь и т.д. | — История покупок в оффлайне. — Данные о клиенте из заполненных анкет. — Какие точки продаж чаще посещает и т.д. |
Цель сопоставления — получить полную картину о поведении конкретного клиента, чтобы затем использовать этот набор данных в интересах магазина. Делать рассылки с наилучшим таргетингом, проводить более эффективные рекламные кампании, выдавать на сайте точные товарные рекомендации — об этом подробнее чуть позже.
Посетитель зашел на сайт и авторизовался под своей учетной записью. Полистал каталог, нашел нужный товар. Но заказ решил оформить по телефону: позвонил и заказал. Если данные не сопоставлять, то для магазина это будут два разных клиента. Если сопоставлять — один клиент (в данном случае вычислить, что это один и тот же человек, можно по номеру телефона).
Если у компании есть не только онлайн-магазин, но и физический отдел — нужно сопоставлять данные еще и с оффлайном. Например, чтобы бонусы с крупной покупки в оффлайне покупатель мог бы использовать в онлайн-магазине. И наоборот.
Что будет, если не сопоставлять данные
Если сопоставления не делать, страдает эффективность буквально всего маркетинга: баннерной рекламы, рассылок, товарных рекомендаций на сайте, программ лояльности.
Частично сопоставление есть у каждого магазина: например, обязательным пунктом анкеты при получении карты клиента является контактный е-мейл или телефон. Однако когда речь идет о десятках параметров из разных источников — без автоматизации объединить их в единый профиль не получится. И тем более — поддерживать актуальность каждого.
Кто автоматизирует сопоставление данных
Есть следующие варианты автоматизации:
Как применяется мэтчинг сегодня?
Пример: как применяется мэтчинг в email-рассылках
Покупатель заинтересовался двумя разными товарами, пусть это будет телевизор X и игровая приставка Y. Система отмечает заинтересованность покупателя. Спустя какое-то время клиент покупает приставку Y в оффлайн-магазине. Что происходит дальше:
Пример: как применяется мэтчинг в ретаргетинг-кампании
С одной стороны у покупателей есть трекинг-код (берется из cookie на сайте), с другой ID покупателя и товара, информация о дате покупке, сумме и другие данные из оффлайна (из программы лояльности). Математические алгоритмы «сравнивают» данные и те, которые с большой вероятностью принадлежат одному покупателю — сливаются в общий профиль. Это помогает сделать следующие улучшения в рекламной кампании:
Пример: товарные рекомендации
Рекомендательная система будет советовать товары не просто с учетом истории покупок и кликов в онлайне или поведения пользователя на других сайтах, но и с привлечением ценных данных из оффлайна. Механики примерно такие же:
Пример: возврат товаров
Есть такая особенность в ритейле: даже если покупатель сделал покупку в онлайн-магазине, то возврат товара он предпочтет сделать в оффлайн-точку. Если не заниматься мэтчингом, то получится, будто бы онлайн-пользователь купил товар и остался им доволен (ведь он не совершал возврата в интернет-магазин). А по факту всё будет не так.
Следовательно, без мэтчинга целостность данных нарушится и магазин будет настойчиво советовать купить дополнительные комплектующие к гаджету, который пользователь вернул в магазин. А узнав о факте возврата товара, магазин может не потерять клиента, постаравшись получить отзыв о причинах возврата и предложить другой нужный человеку товар с персональной скидкой.
Заключение
Сопоставлением данных критично важно заниматься тем магазинам, у которых много каналов продаж: оффлайн-магазин, сайт, мобильное приложение. Чем больше каналов — тем богаче данные, которые по-отдельности не так эффективны, как если их объединять в единые виртуальные профили.
Оптимальным решением для крупных ритейлеров будет работа со специализированным сервисом мэтчинга или интеграция нужных функций в CRM. Для малого и среднего бизнеса подойдет сервис рекомендаций, который сопоставляет и объединяет данные из разных источников, оффлайна и онлайна.
Любовь по телефону: мэтчинг для контакт-центра
Основатель DataFuel о том, зачем колл-центрам нужны технологии машинного обучения, как с помощью алгоритмов создать идеальные пары «клиент-сотрудник» и повысить эффективность операторов.
Технологии Human Matching и персонализации — не новость в маркетинге, однако колл-центры до сих пор используют устаревшие приемы коммуникации с клиентом. В большинстве случаев это выглядит так:
Обезличенное взаимодействие часто приводит к проблемам в коммуникации. Допустим, в колл-центр обращаются:
а) разъяренный мужчина, уверенный в своей правоте и не терпящий никаких возражений;
б) робкая девушка, потратившая несколько минут, чтобы решиться сделать звонок.
Оба клиента получают ответ «в соответствии с типом вопроса звонящего». Вопрос может быть один и тот же, но потребности и способы их удовлетворения — разные. С позиции психологии и поведенческого маркетинга проблема решается так:
а) Для клиента, которому важна скорость и точность, сработает формат «запрос — решение». Медлительный, расфокусированный ответ оператора вызовет, как минимум, раздражение, а то и вовсе грозит потерей клиента.
б) Для робкого и нерешительного человека — наоборот, лучшим вариантом будет чуткий, внимательный и спокойный оператор, готовый ответить на все вопросы.
В условиях случайного выбора вероятность счастливого совпадения клиента и подходящего ему оператора очень низкая. По обе стороны коммуникации — люди с разными целями и темпераментами. В итоге клиент испытывает неудовлетворенность, разочарование и, следовательно, обращается в другую компанию, а сотрудник — эмоционально выгорает, начинает тихо ненавидеть свою монотонную работу и непонятливых клиентов.
На результат коммуникации влияют человеческие факторы, а не обучение и переквалификация сотрудников. Важны:
А что, если определять психографические характеристики каждого участника, выявлять повторяющиеся паттерны и автоматизировать мэтчинг похожих друг на друга собеседников? Утопия или реальность современного AI бизнеса?
На мировом рынке эта технология уже существует и успешно применяется. Например, платформа Afiniti оптимизирует работу колл-центров с помощью машинного обучения и многоуровневого дейтинг-алгоритма.
Чтобы доказать эффективность внедрения своего сервиса и привлечь больше клиентов, Afiniti предлагает пост-оплату услуг. В результате компания получает процент от итоговой прибыли.
Технологии Afiniti универсальны и применимы для любой отрасли.
Компания Sky — один из крупнейших провайдеров спутникового телевидения в Великобритании. Уже на этапе первичного запуска платформы конверсия повысилась на 4%. Позже взаимодействие улучшилось с 12 000 клиентов на 18 сайтах Великобритании и сайтах подразделений в других странах: Ирландии, Италии, Германии.
Virgin Media — крупный игрок телевизионной индустрии (более 5 миллионов клиентов). В начале сотрудничества Afinity добилась роста по удержанию потребителей на выборке в 3 000 клиентов и стала долгосрочным партнером компании.
Caesars — международная компания гостиничного бизнеса. Интеграция с платформой Afinity принесла годовой прирост в 15 000 дополнительных бронирований.
Мы используем технологии Human Matching для российских колл-центров, опираясь на методологию BIG5 и собственную разработку spectrum:
Наш сервис протестировала компания Reg.ru. Перед нами стояли задачи по повышению конверсии в двух группах:
Мы разработали следующую стратегию для решения проблемы
На первичном этапе внедрения технологии мы провели аб-тестирование и получили следующие результаты:
Для персонализации сценариев в DataFuel мы используем более 250 параметров: время постинга, семантику постов, тип публикуемого контента и пр. На основе этих параметров мы делаем выводы о способе принятия решений и инновативности – способности воспринимать и анализировать новую информацию. Таким образом, формируется четыре группы психотипов: новаторы, консерваторы, прагматики и романтики.
Чтобы повысить продажи дополнительных услуг, оператору нужно понимать, какой клиент к нему обратился и применять базовые принципы общения с разными типами клиентов:
Если вы звоните Новатору, нужно учитывать, что человек с этим психотипом склонен к импульсивным поступкам и жаждет новых идей. Сообщайте ему об уникальности и трендовости продукта. Не стесняйтесь.
Консерватора, напротив, совсем не нужно загружать эмоционально окрашенной речью. Говорите с ним на простом языке и опирайтесь на надежность и удобство использования/взаимодействия с продуктом. Людям с этим психотипом важны стабильность и мнение большинства.
Разговаривая с Прагматиком, делайте акцент на фактах и цифрах. Почаще говорите о выгодах, которые собеседник получит от использования продукта. Но не увлекайтесь: лаконичность и ясность – ваши путеводные звездочки.
Романтики ценят комфорт и чувство безопасности. Говорите с ним мягко. Создавайте уютную атмосферу во время разговора, и не забывайте говорить о приятных эмоциях, которые ваш продукт может вызвать у клиента и его близких.
Эти базовые принципы на практике сложнее, и включают в себя больше детальных характеристик. Но при правильном подходе методология внедряется органично.
Операторы и клиенты в этой системе объединены психологической совместимостью.В сочетании с дополнительным образованием компания получает прирост конверсии и эффективность коммуникации для всех участников.
Вместе с компанией Reffection нам удалось измерить показатели конверсии на исходящих телемаркетинговых кампаниях. Мы проанализировали результаты около 30 000 звонков. В исследовании приняли участие 50 операторов. Мы нашли корреляцию показателей по шкалам BIG5 c конверсией.
Операторы прошли тест OCEAN с помощью партнерского сервиса HRcode, после чего в течение 2 месяцев совершали звонки по телемаркетинговым кампаниям нескольких типов. Операторы определяли потребность клиентов и передавали целевые заявки в отдел продаж.
Положительную корреляцию с конверсией продемонстрировали операторы с высокими баллами по экстраверсии и дружелюбности. У сотрудников, чьи показатели по шкале Нейротизм подтвердили эмоциональную неустойчивость, нестабильную самооценку и высокую степень тревоги, корреляция с конверсией отрицательная.
Конверсия десяти операторов с наиболее высокими показателями экстраверсии и низким нейротизмом была на 50% выше, чем конверсия других операторов с наименьшей экстраверсией и высоким нейротизмом.
Такой подход позволяет прогнозировать результативность оператора еще на этапе отбора: отсеивать кандидатов с заведомо низкими показателями эффективности, или ставить их на проекты, которые не требуют высоких коэффициентов конверсий в продажи. Полученные инсайты можно применять для подбора и онбординга сотрудников в контакт-центры.
Для более точного подтверждения методологии необходимо провести исследования большего масштаба: с выборкой более 200 операторов и не менее 200 000 звонков. Если хотите участвовать в таком исследовании и получить его результаты, то вы можете оставить заявку на нашем сайте.
Только максимально персонализированный подход может сделать сервис и продукт действительно конкурентоспособным, поэтому в перспективе рынок технологий для Human Matching будет только расти.
Приобрести клиента «на всю жизнь» возможно, если точно понимать и удовлетворять его потребности. Поэтому следующий этап, уже внедряемый на западном рынке — персонализация плана мотивации персонала. Когда мы уже хорошо знаем своего потребителя, стоит позаботиться о сотруднике: понять, что его мотивирует для эффективных продаж, и, исходя из этих знаний, укрепить его мотивацию и усилить клиентоориентированный подход.



