Анализ качественных признаков (Критерий χ2. Сравнение долей) (Лабораторная работа № 4)
Страницы работы


Содержание работы
Тема:Анализ качественных признаков
Критерий χ 2 – это непараметрический критерий, является аналогом дисперсионного анализа для качественных признаков.
Далее подсчитывают с точностью до двух знаков после запятой ожидаемые числа – количество объектов, которое попало бы в каждую клетку, если бы изучаемые факторы не влияли бы на исход. Ожидаемые значения обозначают буквой E (expected). Таблица ожидаемых чисел рассчитывается следующим образом (обратите внимание, что суммы по строкам и столбцам должны сохраниться):
По полученным таблицам рассчитывается значение критерия:
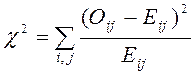 ,
,
где Оij – наблюдаемые значения в клетках таблицы, Еij – ожидаемые значения. Суммирование производится по всем клеткам таблицы.
Применение критерия χ 2 правомерно, если ожидаемые числа в любой из клеток больше либо равны 5.
Число степеней свободы ν=(r-1)(c-1).
В случае таблицы 2×2 в формулу вводят поправку Йейтса:
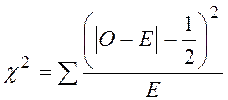 .
.
Пример. Изучение влияния дополнительного приема эстрогена на риск развития болезни Альцгеймера. В исследовании принимала участие группа из 1124 пожилых женщин, 156 из которых длительное время получали эстроген. Группа наблюдалась в течение пяти лет, регистрировались случаи болезни Альцгеймера. Результаты расчетов:
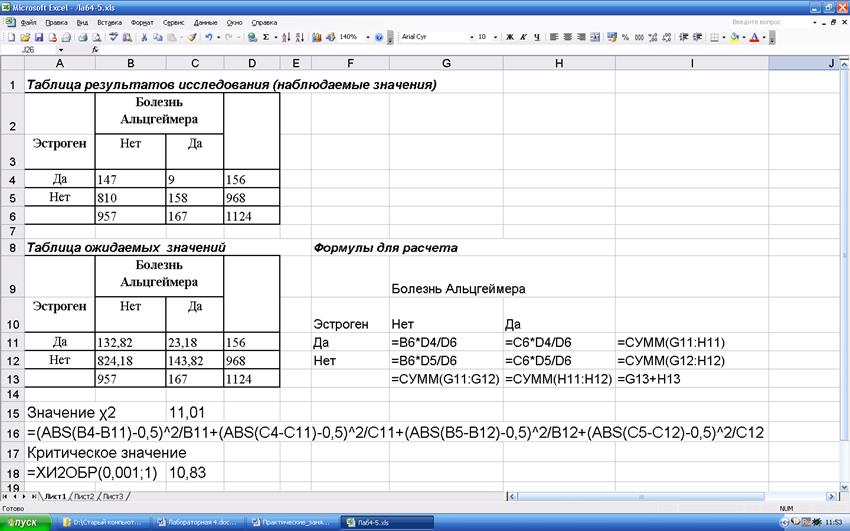
Рассчитанное значение больше критического, поэтому можем утверждать, что дополнительный прием эстрогена снижает риск развития болезни Альцгеймера (вероятность ошибки менее 0,1%).
Время от окончания предыдущей беременности
Планировалась ли беременность
Курение во время беременности
Низкий гемоглобин во время беременности
1.2. Проводилась оценка эффективности терапии для лечения синдрома хронической обеспокоенности. В исследовании принимало участие 150 человек, 60 из которых получали двухмесячную программу лечения. После двух месяцев проводилась оценка состояния (ухудшилось, улучшилось, не изменилось). Результаты в таблице:
Есть статистически значимые различия между группами? Что произойдет, если удвоить количество участников эксперимента при сохранении пропорций между группами? Рассчитайте.
Оценка и сравнение долей
Пусть имеется выборка из n объектов, при этом m из них обладает каким-то качественным признаком, которого нет у остальных n-m объектов. Тогда доля объектов, выборки, обладающих признаком, вычисляется как p=m/n. Показатель разброса значений – стандартное отклонение доли – вычисляется по формуле: 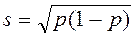 ; стандартная ошибка доли:
; стандартная ошибка доли: 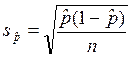 .
.
Критерий z для проверки нулевой гипотезы о равенстве долей в двух выборках:
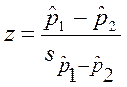
где 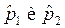 — выборочные доли,
— выборочные доли, 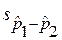 — стандартная ошибка разности долей.
— стандартная ошибка разности долей.
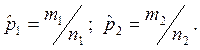 Объединенная оценка доли:
Объединенная оценка доли: 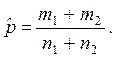
Стандартная ошибка разности долей вычисляется:
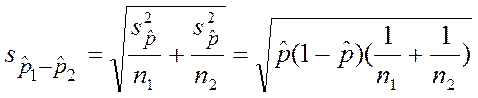 .
.
Для нахождения критических значений z необходимо воспользоваться таблицами значений стандартного нормального распределения. При увеличении числа степеней свободы распределение Стьюдента стремится к нормальному, поэтому критические значения z можно найти в последней строке таблицы распределения Стьюдента. Для α =0,05 z0,05=1,96; для α=0,01 z0,01=2,58.
С учетом этой поправки Йейтса формула для расчета z имеет вид:
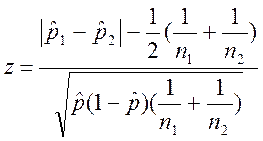 .
.
Пример. Применим z-критерий для задачи о влиянии дополнительного приема эстрогена на риск развития болезни Альцгеймера. В группе принимавшей эстроген (n1=156) количество заболевших составило 9 (m1=9). Во второй группе (n2=968) количество заболевших составило 158 (m2=158).
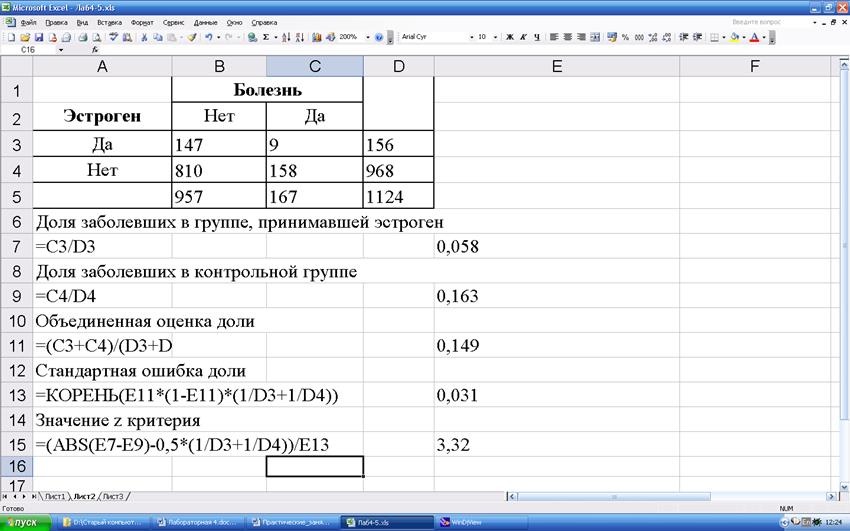
Рассчитанное значение больше, чем z0,01. Поэтому с уровнем значимости 0,01 можем утверждать, что между долями заболевших существуют статистически значимые различия.
Исследовалось влияние экзогенных стероидных гормонов во время беременность у 108 матерей детей с врожденными дефектами. Непреднамеренное использование оральных контрацептивов на ранних сроках беременности рассматривалось как основной фактор воздействия. У матерей больных детей отмечено употребление контрацептивов в 15 случаях, в контрольной группе (также 108 матерей) – в 4 случаях. Есть ли статистически значимые различия между группами?
Сравнение качественных признаков (выраженных в частотах) в 2-х независимых группах с помощью точного метода Фишера
Анализ качественных признаков
В предыдущих лабораторных работах мы производили анализ количественных признаков. Примером таких признаков служат артериальное давление, количество дней госпитализации, время послеродовой активности и т. д. Единицей их измерения могут быть миллиметры ртутного столба, часы или дни. Над значениями количественных признаков можно производить арифметические действия. Можно, например, сказать, что артериальное давление снизилось на какое-то количество единиц. Кроме того, их можно упорядочить: расположить в порядке возрастания или убывания.
Однако очень многие признаки невозможно измерить числом. Например, можно быть либо мужчиной, либо женщиной, либо, больным либо здоровым. Это качественные признаки. Эти признаки не связаны между собой никакими арифметическими соотношениями, упорядочить их также нельзя. Единственный способ описания качественных признаков состоит в том, чтобы подсчитать число объектов, имеющих одно и то же значение. Кроме того, можно подсчитать, какая доля от общего числа объектов приходится на то или иное значение.
Сравнение частот при наличии таблиц сопряженности 2х2 в двух несвязанных выборках с помощью критерия хи-квадрат
Условия и ограничения применения критерия хи-квадрат Пирсона
2) Данный метод позволяет проводить анализ не только четырехпольных таблиц, когда и фактор, и исход являются бинарными переменными, то есть имеют только два возможных значения (например, мужской или женский пол, наличие или отсутствие определенного заболевания в анамнезе. ). Критерий хи-квадрат Пирсона может применяться и в случае анализа многопольных таблиц, когда фактор и (или) исход принимают три и более значений.
4) При анализе четырехпольных таблиц ожидаемые значения в каждой из ячеек должны быть не менее 10. В том случае, если хотя бы в одной ячейке ожидаемое явление принимает значение от 5 до 9, критерий хи-квадрат должен рассчитываться с поправкой Йейтса. Если хотя бы в одной ячейке ожидаемое явление меньше 5, то для анализа должен использоваться точный критерий Фишера.
5) В случае анализа многопольных таблиц ожидаемое число наблюдений не должно принимать значения менее 5 более чем в 20% ячеек.
Пример
Гемодиализ позволяет сохранить жизнь людям, страдающим хронической почечной недостаточностью. При гемодиализе кровь больного пропускают через искусственную почку — аппарат, удаляющий из крови продукты обмена веществ. Искусственная почка подсоединяется к артерии и вене больного: кровь из артерии поступает в аппарат и оттуда, уже очищенная — в вену. Так как гемодиализ проводится регулярно, больному устанавливают артериовенозный шунт. В артерию и вену на предплечье вводят тефлоновые трубки; их концы выводят наружу и соединяют друг с другом. При очередной процедуре гемодиализа трубки разъединяют между собой и присоединяют к аппарату. После диализа трубки вновь соединяют, и кровь течет по шунту из артерии в вену. Завихрения тока крови в местах соединения трубок и сосудов приводят к тому, что шунт часто тромбируется. Тромбы приходится регулярно удалять, а в тяжелых случаях даже менять шунт. Руководствуясь тем, что аспирин препятствует образованию тромбов, Г. Хартер и соавт. решили проверить, нельзя ли снизить риск тромбоза назначением небольших доз аспирина (160 мг/сут). Было проведено контролируемое испытание. Все больные, согласившиеся на участие в испытании и не имевшие противопоказании к аспирину, были случайным образом разделены на две группы: 1-я получала плацебо, 2-я — аспирин. Ни врач, дававший больному препарат, ни больной не знали, был это аспирин или плацебо. Такой способ проведения испытания (он называется двойным слепым) исключает «подсуживание» со стороны врача или больного и, хотя технически сложен, дает наиболее надежные результаты. Исследование проводилось до тех пор, пока общее число больных с тромбозом шунта не достигло 25. Группы практически не различались по возрасту, полу и продолжительности лечения гемодиализом.
В 1-ой группе тромбох шунта произошел у 18 из 25 больнных, во 2-ой – у 6 из 19 (табл). Можно ли говорить о статистически значимом различии доли больных с тромбозом, а тем самым об эффективности аспирина? Таблица результатов исследования представлена в следующем виде:
Влияние аспирина на тромбоз: таблица сопряженности
| Показатели | Плацебо | Аспирин |
| Тромбоз есть | 18 | 6 |
| Тромбоза нет | 7 | 13 |
Нулевая гипотеза:аспирин не влияет на возникновение тромбоза шунта.
Уровень значимостипринимается 0,05.
Запустите программу «Statistica», создайте новый документ. В меню выберите Анализ — Непараметрическая статистика/Statistics-Nonparametric>— Таблицы 2х2/ 2×2 Tables(X/V/Phi, McNemar, Fisherexact) >OK.
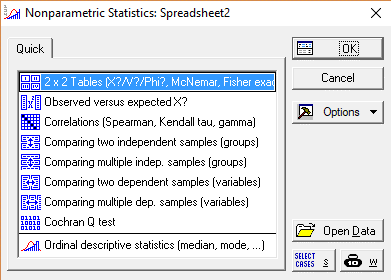
В появившемся окне введите значения из полученной таблицы сопряженности. При этом левый столбец соответствует левому столбику таблицы (Плацебо), а правый соответствует правому (Аспирин). Аналогичная ситуация и со строками.
Нажмите Summary.Появится таблица с результатами статистической обработки.
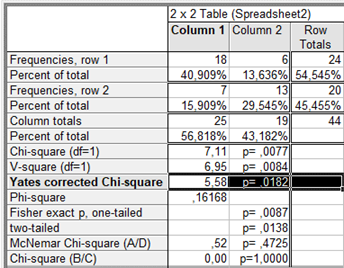
Так, из таблицы видно, что у больных, принимавших аспирин, тромбозы наблюдались в 13,6% случаев против 40,9% больных, принимавших плацебо. Однако необходимо оценить статистическую значимость полученного различия с помощью правильно подобранного критерия.
Так как в данном случае анализ проводился таблицы сопряженности 2х2, то необходимо учитывать поправку Йейтса. Исходя из полученных значений критерия хи-квадрат(5,58)и вероятности p(0,0182), следует заключить, что видимые различия в клетках таблицы сопряженности значимы. Поэтому нулевая гипотеза отвергается. Аспирин действительно положительно влияет на снижение вероятности возникновения тромбоза шунта.
Сравнение качественных признаков (выраженных в частотах) в 2-х независимых группах с помощью точного метода Фишера
Дата добавления: 2018-02-28 ; просмотров: 1508 ; Мы поможем в написании вашей работы!
Статистические типы данных, используемые в машинном обучении

Sep 21, 2020 · 7 min read

Введение в статистику
Статистика — это наука об изучении данных. Знания в этой области позволяют использовать подходящие методы сбора и анализа данных, а также эффективно представлять результаты такого анализа. Статистика играет ключевую роль в научных открытиях, принятии решений и составлении прогнозов, основанных на данных. Она позволяет гораздо глубже разобраться в объекте исследования.
Чтобы стать успешным специалистом по теории и методам анализа данных, необходимо знать основы статистики. Математика и статистика — “строительные блоки” алгоритмов машинного обучения. Чтобы понимать, как и когда следует использовать различные алгоритмы, нужно знать, какие методы за ними стоят. Тут встаёт вопрос — что именно собой представляет статистика?
Ста т истика — это математическая наука о сборе, анализе, интерпретации и представлении данных.
Для чего изучать статистику?
Один из основных принципов науки о данных — получение выводов из их анализа. Статистика отлично для этого подходит. Она является разновидностью математики и использует формулы, но она отнюдь не обязательно покажется пугающей, даже если вам не приходилось сталкиваться с ней раньше.
Машинное обучение зародилось из статистики. Основой используемых в нём алгоритмов и моделей является так называемое статистическое обучение. Знание основ статистики крайне полезно вне зависимости от того, изучаете вы глубоко алгоритмы МО или просто хотите быть в курсе новейших исследований в этой сфере.
Введение в типы данных
Хорошее понимание разных типов данных (шкал измерений) — основное условие для проведения разведочного анализа данных (EDA), ведь для определённых типов данных можно использовать только ограниченный набор статистических измерений.
Чтобы решить, какой метод визуализации выбрать, также необходимо понимать, с какими данными вы имеете дело. Думайте о типах данных как о способе категоризации разновидностей переменных. Далее мы обсудим основные типы данных и рассмотрим примеры для каждого из них.
Данные:
2. Категориальные (выражены словами): цвет глаз, пол, группа крови, этническая принадлежность

Типы данных:
Качественные и количественные данные
Разделение данных на качественные и количественные — основополагающий принцип разделения данных на типы. Чтобы определить тип, нужно выяснить, можно ли объективно измерить исследуемую характеристику с помощью чисел.
1) Качественные данные
В информации представлены характеристики, которые не измеряются числами, в то время как сами наблюдения можно разделить на измеряемое количество групп. Информацию, хранящуюся в таком типе переменной, трудно измерить, а измерения могут быть субъективными. Вкус, цвет автомобиля, архитектурный стиль, семейное положение — всё это типы качественных данных. Аналитики также называют такие данные категориальными.
1.1) Номинальные данные
Номинальные значения выражают дискретные единицы и служат для обозначения переменных, которые не имеют количественного выражения. Номинальные данные не имеют порядка, поэтому при изменении порядка значений итоговый результат не меняется. Ниже представлено два примера номинальных признаков:

Методы визуализации: для визуализации номинальных данных можно использовать круговую или столбчатую диаграмму.
В науке о данных можно использовать прямое кодирование, чтобы преобразовать номинальные данные в числовое свойство.
1.2) Порядковые данные
Порядковые данные — это смесь числовых и категориальных данных. Данные можно разбить на категории, но числа, ассоциируемые с каждой категорией, имеют значение. К примеру, рейтинг ресторана от 0 (самый низкий) до 4 (самый высокий) звёзд — это пример порядковых данных. Порядковые данные часто обрабатываются как категориальные, когда при построении диаграмм и графиков данные разделяются на упорядоченные группы. Однако, в отличие от категориальных, числа в порядковых данных имеют математическое значение. Таким образом, порядковые данные — это почти то же самое, что и номинальные, с тем лишь отличием, что в номинальных порядок не имеет значения. Взгляните на пример ниже:

Порядковые шкалы обычно используются для измерения нечисловых свойств, таких как счастье, уровень удовлетворённости клиентов, успеваемость студентов в классе, уровень квалификации и т. д.
Такие данные можно обобщать с помощью частотности, пропорций, процентных долей, а визуализировать — с помощью круговых и столбчатых диаграмм. Кроме того, можно использовать процентиль, медиану, моду, межквартильный размах.
В дополнение к порядковым и номинальным есть особый тип категориальных данных — бинарные (двоичные).
Бинарные данные принимают только два значения — “да” или “нет”, что можно представить разными способами: “истина” и “ложь” или 1 и 0. Бинарные данные широко применяются в классификационных моделях машинного обучения. В качестве примеров бинарных переменных можно привести следующие ситуации: отменил человек подписку или нет, купил машину или нет.

2) Количественные данные
Информация записывается в виде чисел и представляет объективное измерение или подсчёт. Температура, вес, количество транзакций — вот примеры количественных данных. Аналитики также называют такие данные числовыми.
2.1) Дискретные данные
Дискретные количественные данные — это подсчёт случаев наличия характеристики, результата, предмета, деятельности. Эти измерения невозможно поделить на более мелкие части без потери смысла. Например, у семьи может быть 1 или 2 машины, но их не может быть 1,6. Таким образом, существует конечное число возможных значений, которые можно зарегистрировать в процессе наблюдений.
У дискретных переменных можно подсчитать и оценить интенсивность потока событий или сводное количество (медиана, мода, среднеквадратичное отклонение). К примеру, в 2014 году у каждой американской семьи было, в среднем, по 2,11 транспортных средства.
Обычный способ графического представления дискретных переменных — столбчатые диаграммы, где каждый отдельный столбик представляет отдельное значение, а высота столбика означает его пропорцию к целому.

2.2) Непрерывные данные
Непрерывные данные могут принимать практически любое числовое значение и могут быть разделены на меньшие части, включая дробные и десятичные значения. Непрерывные переменные часто измеряют по шкале. Когда вы измеряете высоту, вес, температуру, вы имеете дело с непрерывными данными.
Например, средний рост в Индии составляет 5 футов 9 дюймов (
175 см.) для мужчин и 5 футов 4 дюйма (
Непрерывные данные подразделяются на 2 типа:
а) Интервальные данные
Интервальные значения представлены упорядоченными единицами, которые имеют одинаковое отличие друг от друга. Таким образом, мы говорим об интервальных данных, когда есть переменная, которая содержит упорядоченные числовые значения, и нам известны точные отличия этих значений. Примером может служить температура в заданном месте:

Проблема со значениями интервальных данных в том, что у них нет “ абсолютного нуля”.
б) Данные соотношения
Данные соотношения также представляют собой упорядоченные единицы с одинаковыми отличиями друг от друга. Это практически то же самое, что и интервальные данные, однако данные соотношения имеют “ абсолютный ноль”. Подходящие примеры — высота, вес, длина и т. д.

При работе с непрерывными данными можно использовать практически все методы: процентиль, медиану, межквартильный размах, среднее арифметическое, моду, среднеквадратичное отклонение, амплитуду.
Для визуализации непрерывных данных можно воспользоваться гистограммой или диаграммой размаха. С помощью гистограммы можно определить среднее значение и крутость распределения, изменчивость и модальность. Имейте в виду, что гистограмма не показывает выбросы — для этого нужно использовать диаграмму размаха.

Заключение
Из этой статьи вы узнали о различных типах данных, используемых в статистике, о разнице между дискретными и непрерывными данными, а также о том, что собой представляют номинальные, порядковые, бинарные, интервальные данные и данные соотношения. Кроме того, теперь вы знаете, какие статистические измерения и методы визуализации можно применять для разных типов данных и как преобразовать категориальные переменные в числовые. Это позволит вам провести большую часть разведочного анализа на представленном наборе данных.
Оценка различий между группами
Количественные признаки.
Нормальное распределение
1. Сравнение независимых групп.
а) Сравнение двух групп.
ПРИМЕР 1. Оценить различия между мужчинами (первая группа) и женщинами (вторая группа) по уровню артериального давления
МЕТОД – Обычный двусторонний критерий Стьюдента (t-критерий) оценивает различия средних.
б) Сравнение трех и более групп.
ПРИМЕР 2. Оценить различия по уровню артериального давления в группах с различным возрастным цензом: 30-39 лет, 40-49 лет, 50-59 лет (соответственно 1-я, 2-я, 3-я группы).
МЕТОД – Дисперсионный анализ оценивает различия средних и дисперсии; устанавливает наличие отличий по всем группам (в ряду оцениваемых групп). Чтобы установить между какими двумя из трех групп существуют различия, а между какими отсутствуют, следует использовать критерий Стьюдента с поправкой Бонферрони (для исключения ошибки связанной с множественным сравнением).
Поясним изложенное. Число попарных сравнений равно 3 (1 и 2 группы, 2и 3 группы, 1 и 3 группы). Допустим, что уровень значимости в двух сравнениях был равен 0,02, в третьем – 0,01 (без применения поправки Бонферрони). Ошибочное выявление различий возрастает пропорционально числу сравнений. Таким образом, истинный уровень значимости будет равен произведению полученной достоверности на число сравнений, т.е. 0,02х3=0,06 и 0,01х3=0,03. Следовательно при уровне значимости принятом в медицине (р>0,05), достоверные отличия выявлены только в одном сравнении.
При числе сравнений больше 8 (т.е. при числе сравниваемых групп более 4) следует использовать критерий Ньюмена-Кейлса.
в) Сравнение нескольких групп с контрольной.
ПРИМЕР 3. Сравнить массу миокарда левого желудочка у здоровых лиц (контрольная группа) с массой миокарда у больных I, II, III степенью артериальной гипертони (1, 2, 3 группы соответственно).
МЕТОД – Критерий Стьюдента с поправкой Бонферрони при числе групп не более 4. При большем количестве групп – критерий Даннета.
2 Сравнение зависимых групп (сравнение повторных измерений)
а) Сравнение двух групп.
ПРИМЕР 4. Оценить достоверно ли изменился ударный объем у больных сердечной недостаточностью после лечения дигоксином.
МЕТОД – Парный критерий Стьюдента.
Оценивает различия средних разностей показателя. Требует нормального распределения разностей.
б) Сравнение трех и более групп.
ПРИМЕР 5. Оценить достоверность изменения уровня холестерина при лечении правастатином в различные сроки наблюдения – через 1, 3, 6,9 месяцев.
Ненормальное распределение
1 Сравнение независимых групп
Примеры задач являются аналогичными при нормальном распределении
а) Сравнение двух групп
МЕТОД – Критерий Манна-Уитни. Альтернативными методами могут быть: критерии Уайта, Ван дер Вадена, Колмогорова-Смирнова.
б) Сравнение трех и более групп.
МЕТОД – Критерий Крускала-Уоллиса. Выявляет различия в ряду изучаемых групп. Для оценки различий между двумя конкретными группами проводят попарное их сравнение с помощью непараметрических вариантов критериев Ньюмена-Кейлса или Даннета (при равном числе наблюдений в группах); критерий Данна (при неодинаковом количестве наблюдений в группах).
2 Сравнение зависимых групп (повторные измерения)
а) Сравнение двух групп.
МЕТОД – Критерий Уилконсона (Вилконсона). Альтернативный метод – критерий знаков.
б) Сравнение трех и более групп.
МЕТОД – Критерий Фридмана. Выявляет различия между всеми группами. Для оценки различий между конкретными двумя группами проводят попарное сравнение с помощью адаптированных (непараметрических) вариантов критериев Ньюмена-Кейлса или Даннета.
Порядковые признаки.
Алгоритм выбора метода анализа такой же, как при ненормальном распределении количественных признаков.
Качественные признаки.
1 Сравнение независимых групп
а) Сравнение двух групп
ПРИМЕР 6. Влияет ли назначение стрептокиназы на реканализацию коронарных артерий у больных острым инфарктом миокарда.Плацебо получали 40 больных, реканализация зарегистрирована у 8 человек. Стрептокиназу вводили 50 больным, реканализация отмечена у 20 человек.
МЕТОД – Критерий Z с поправкой Йетсена на непрерывность. Аналогичен по математическому выражению критерию Стьюдента, но используются долевые [ p и (1-p) ] значения признака. Табличный вариант примера 6 выглядит следующим образом:

Критерий Z применим, если произведение числа наблюдений на значение доли больше 5 в каждой из клеток таблицы. При несоблюдении последнего правила следует использовать точный критерий Фишера (в этом случае поле таблицы вводят абсолютное число наблюдений).
б) Сравнение трех и более групп.
ПРИМЕР 7. Условие то же, что и в примере 6, но добавлен третий вариант лечения – стрептокиназа + гепарин, при котором из 45 лечившихся, реканализация наблюдалась у 25 человек.
МЕТОД – Таблица сопряженности с оценкой различий с помощью критерия  . В поле таблицы вводят абсолютные числовые значения признака. Критерий обладает высокой надежностью, если во всех полях таблицы нет значений признака меньше 5. При этом оценивается наличие различий между всеми группами. Для выявления, между какими двумя группами достоверны различия, а между какими – нет, следует строить несколько четырехпольных таблиц (содержащих результаты двух из трех методов лечения) с оценкой каждой из них по критерию с поправкой Бонферрони.
. В поле таблицы вводят абсолютные числовые значения признака. Критерий обладает высокой надежностью, если во всех полях таблицы нет значений признака меньше 5. При этом оценивается наличие различий между всеми группами. Для выявления, между какими двумя группами достоверны различия, а между какими – нет, следует строить несколько четырехпольных таблиц (содержащих результаты двух из трех методов лечения) с оценкой каждой из них по критерию с поправкой Бонферрони.
2. Сравнение зависимых групп (повторные измерения).
а) Сравнение двух групп.
ПРИМЕР 8. При лечении 40 больных АГ анаприлином эффект наблюдался у 25 человек, а при лечении этих больных гипотиазидом эффект был отмечен у 16 человек.
б) Сравнение трех и более групп
ПРИМЕР 9. Аналогичен примеру 8, но добавляется третий препарат празозин – при лечении которым эффект наблюдался у 18 больных. Оценить достоверны ли различия между препаратами по числу больных с наличием эффекта.
МЕТОД – Критерий Кокрена. Альтернативным методом может служить таблица сопряженности с оценкой различий по .
Для выявления конкретных двух групп между которыми различия по числу больных с эффектом достоверны, общую таблицу следует разбить на несколько четырехпольных таблиц и сравнить их последовательно с помощью критерия .



