Как узнать какую информацию «накопал» на вас Google
Ни для кого не секрет, что поисковые системы и сервисы непрерывно собирают данные о своих пользователях. Ежесекундно в одну только поисковую систему Google поступает более 40 тысяч запросов от пользователей на поиск той или иной информации. Вы отправляете свой запрос, а в ответ поисковые системы инициируют выдачу результатов.
Но параллельно с этим происходит еще один процесс. За каждый ваш запрос в поисковой строке непрерывно проходит борьба рекламодателей, которые готовы платить деньги, чтобы их сайты появились на первых местах в поисковой выдаче. Любая информация о вас может быть монетизирована после тщательного изучения ваших предпочтений.
Это можно сравнить с театральной постановкой. Вы вводите свой запрос в поисковую строку и «на сцене» выключается свет. За несколько секунд декорации впопыхах меняют на новые, а когда свет загорается вновь, вы видите перед собой совершенно новый «интерьер».
Поисковая выдача в ответ на ваш запрос за доли секунды расставляет нужные ссылки на свои места, чтобы вы с большой вероятностью кликнули по ним.
Поисковые системы знают о вас порой намного больше, чем ваши самые близкие друзья. Ведь многие доверяют им свою самую сокровенную информацию.
Сайтам известен ваш возраст и пол, вся ваша личная переписка, а также уровень ваших доходов и вещи, которые вы рассматриваете для покупки, языки, которыми вы владеете и даже права собственности на недвижимость.
Можно сказать, что с того момента, когда вы завели аккаунт в Google, на вас «шьют» личное дело.
Приведем простой пример. Вы устроились на новую работу в 5 км от дома и каждый день стали проходить это расстояние пешком утром, а также вечером, возвращаясь домой. Как только Google это поймет, скорее всего, вы очень скоро увидите рекламу каких-нибудь наушников и фитнес браслетов в своем браузере. Так как велика вероятность, что вы потенциальный покупатель этих вещей.
Откуда Google это известно? Все очень просто. Система отслеживает ваши перемещения по сигналу сотовой связи и GPS и определяет как быстро переходит сигнал от одной сотовой вышки к другой, определяя скорость и частоту ваших перемещений.
Что известно именно про вас?
Как же узнать какая информация о вас известна? Специально для этого Google создала сервис Takeout. Обычно этим термином в английском языке обозначают сервис еды на вынос. Но в данном случае речь идет об информации «на вынос», то есть той, что вы можете изучить и перенести на свой компьютер.
Для того, чтобы просмотреть те данные, что собираются о вас поисковой системой Google, перейдите по ссылке takeout.google.com. Здесь представлена вся информация, которая собирается о вас и которую вы можете экспортировать на ваш компьютер в виде архивов с данными в нужных вам форматах.
Проставьте галочки напротив интересующих вас сервисов.
Там, где рядом с интересующим сервисом есть пункт «Несколько форматов», можно нажать и самостоятельно выбрать нужный из предложенных форматов.
Например, выбирая данные для скачивания «Игровые сервисы Google Play», можно выбрать в зависимости от предпочтений формат HTML или JSON.
После того как вы выбрали данные, которые хотели бы получить, выберите способ получения, тип (ZIP или TGZ) и размер файлов (1, 2,4,10 или 50 ГБ) и нажмите на пиктограмму «Создать экспорт».
Начнется процесс формирования отчета, а на почту придет соответствующее письмо с уведомлением о формировании запроса.
В зависимости от количества выбранных вами данных, будет сформирован отчет, который можно скачать.
После скачивания и открытия архива вы увидите папку Takeout, в которой и будут находиться запрашиваемые вами данные.
Например, так выглядят скачанные данные об истории поиска в сервисе YouTube и история поиска в Картах.
Вы можете задать резонный вопрос: «А зачем Google нужно, чтобы люди знали, какая информация о них известна?»
Во-первых, такие данные могут понадобиться, если вы захотите мигрировать на другой сервис. И вы сможете перенести таким образом все, что необходимо.
Вторая причина, по которой, скорее всего, был разработан данный функционал, – в стремлении Google к максимальной открытости для своих пользователей. Так называемая brand transparency. Чем меньше секретов, тем выше доверие и лояльность аудитории.
А это, как известно, для таких крупных компаний как Google всегда было одним из ключевых факторов.
Как узнать, кто тебя гуглит?
 Вы когда-нибудь гуглили коллегу или себя? Не хотели бы вы знать, кто вас гуглит? Или получать уведомления, как это происходит? К сожалению, Google не раскрывает этот тип информации.
Вы когда-нибудь гуглили коллегу или себя? Не хотели бы вы знать, кто вас гуглит? Или получать уведомления, как это происходит? К сожалению, Google не раскрывает этот тип информации.
Используя Google AdWords, вы можете узнать глобальный ежемесячный объем поиска вашего имени или релевантных ключевых слов, по которым производится поиск вместе с вашим именем. Тем не менее, он ничего не говорит о человеке, который гуглит вас.
И как вы узнаете, действительно ли вы ищете их?
По правде говоря, вы не можете юридически выяснить, кто именно использует поисковую систему для поиска информации о вас. Тем не менее, вы можете узнать, когда и где кто-то ищет вас. Чтобы получить эту информацию, вы должны настроить ловушку. Другими словами, позвольте себе быть найденным. Здесь я представлю 3 сайта, которые помогут вам узнать, когда кто-то ищет вас в Интернете.
Все эти сайты работают, размещая ваш профиль высоко в результатах поиска. Таким образом, ваш соответствующий профиль будет одним из первых хитов, которые увидят люди при поиске вашего имени. И как только кто-то нажмет, вы получите уведомление по электронной почте. Их IP-адрес покажет, откуда был произведен поиск, и используемый ими поисковый термин может сказать, кто они и почему они ищут вас.
Ziggs
В Ziggs вы можете создать полный профиль и продавать себя. Вы можете поделиться своей биографией, написать о себе и загрузить свое резюме. Через некоторое время ваш профиль будет проиндексирован поисковыми системами, и люди найдут вас.
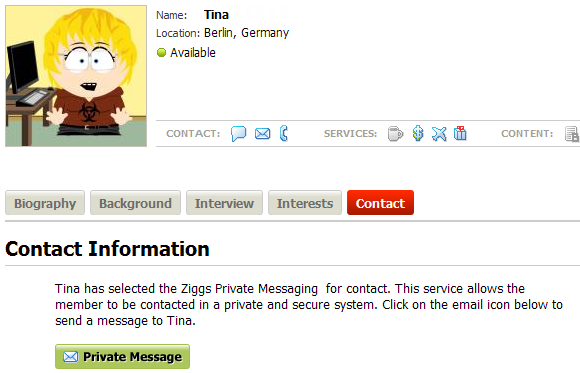
Как только кто-то щелкнет ссылку на ваш профиль, вы получите уведомление по электронной почте. В электронном письме будет указано, когда был произведен поиск в вашем профиле, откуда был произведен поиск (на основе IP-адреса) и какие ключевые слова использовались для поиска вас.
Naymz — еще одна страница, очень похожая на LinkedIn и Ziggs, которая будет предупреждать вас о просмотре вашего профиля.
WikiWorldBook
WikiWorldBook работает очень похоже на Ziggs. Разница в том, что это действительно просто онлайн адресная книга. Вы можете скрыть все свои контактные данные и позволить им связываться с вами только через WikiWorldBook. Люди, которые ищут вас, могут по-прежнему очень легко с вами связаться, без регистрации.
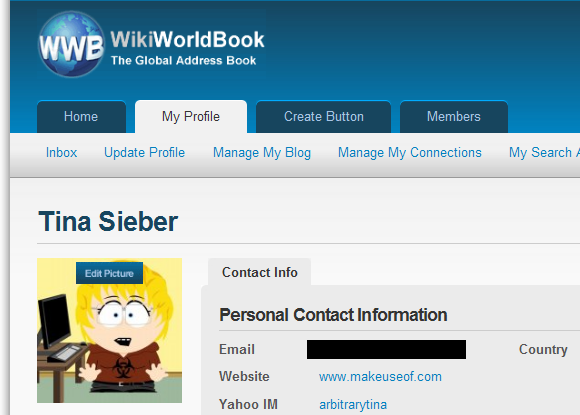
Вы можете ввести массив контактной информации, социальных ссылок и несколько деталей о себе. Вы также можете получить контактную кнопку с их сайта и разместить ее на своем сайте или в социальном профиле. Если кто-то отправит вам сообщение через WikiWorldBook, оно будет перенаправлено на ваш адрес электронной почты.
Вот короткое видео, демонстрирующее, как это работает:
Academia.edu
Этот сайт предназначен для людей, которые работают в области исследований и / или научных кругов.
Он не только позволяет вам находить людей с похожими исследовательскими интересами и отслеживать последние разработки в вашей области исследований, вы также можете настроить свой собственный профиль и получать уведомления, когда кто-то просматривает его.
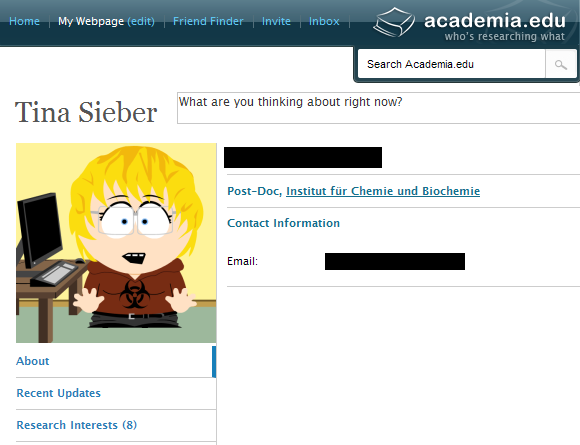
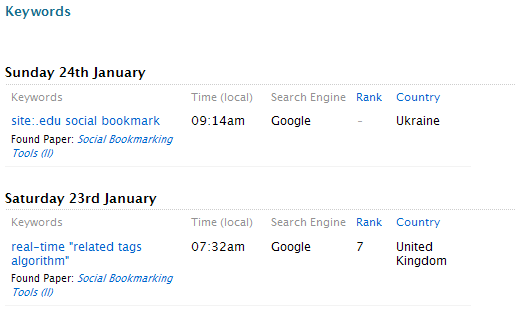
Помимо написания о себе и определения своих научных интересов, вы можете загружать свои публикации, рецензировать статьи или книги, которые вы прочитали, и обновлять свой статус. В категории «Ключевые слова» перечислены все поисковые запросы, которые были использованы для поиска вашего профиля.
Итак, вы нашли свое имя в Google и нашли странные результаты? Не чувствуйте себя в безопасности только потому, что вы нашли кого-то, кто носит ваше имя. Они все еще могут испортить вашу репутацию. Кроме того, если потенциальный работодатель вообще не может найти вас в Google, это может быть не в ваших интересах!
Если вы беспокоитесь о своей репутации в Интернете, сделайте что-нибудь с этим. Следующие две статьи покажут вам, как:
Джон Макклейн показал, как управлять рейтингом поисковой системы для вашего имени
и я объяснил, как поддерживать профессиональный профиль онлайн
Какие твои самые большие грехи в Интернете, которые может показать Google?
Какие данные собирает Google, и как их скачать, или как узнать о человеке всё, взломав только его почту?
Как известно, Google хранит большое количество данных о своих пользователях, чем его непрерывно попрекают. Под давлением и критикой в Google создали механизм, который позволяет выкачать все свои данные. Этот сервис называется Takeout, и у него могут быть разные интересные применения, о которых мы и поговорим. А заодно детально изучим то, что он выдает на руки пользователю.
Источник статьи телеграм канал IT Books

Как скачать сохраненные в Google данные
Причины взять и забрать всё могут быть разными. Например, вы хотите мигрировать на другой сервис и перенести туда свои данные: без конвертации вряд ли обойдется, но иногда это оправданная морока. Или, может быть, вы хотите сделать какую-то аналитическую систему в духе лайфлоггинга и quantified self и вам в этом помогут накопленные в Google данные. Или страна, в которой вы живете, вдруг решила отгородить свой интернет каким-нибудь великим файрволом, после чего Google окажется за бортом.
Если не хотите качать такие объемы, то заказывайте частичные архивы, которые будут включать не все сервисы. Например, если выключить Photos, YouTube и Gmail, а также Drive, если вы там храните что-то помимо тестовых документов, то может получиться всего несколько сот мегабайтов. Кстати, чем меньше архив, тем быстрее приходит ссылка на скачивание.
Какие данные собирает Гугл
В этой главе я расскажу, о каждом (собирающем пользовательские данные) сервисе Google. Начнем с самых популярных и часто используемых.
Какие данные собирает поиск Google
Начнем с одной из самых занимательных вещей — истории поисковых запросов. Она лежит в папке Searches и разбита на файлы по три месяца, к примеру 2018-01-01 January 2018 to March 2006.json. Если открыть один из них, то увидите, что информация о каждом запросе состоит всего из двух вещей: времени в формате Unix и искомой строки.
Для перевода времени можно использовать какой-нибудь онлайновый конвертер, а если нужно будет сконвертировать массово, то это делается одной строкой на Python (замените слово «время» на свое значение):
Но подробным анализом я предлагаю вам заняться самостоятельно. Мы же забавы ради попробуем поискать вхождения тех или иных строк при помощи grep. Поскольку данные сохранены в JSON, их сначала нужно будет сконвертировать в строки — я для этого использовал утилиту gron.
Если у вас gron, можете написать что-то в таком духе:
$ for F in *; do cat «$
» | gron | grep «deepwebteam»; done
И увидите все свои запросы со словом spysoftnet за все время. Какие еще ключевики можно попробовать? Ну например, слово «скачать».
Или вот занятная идея: если поискать символ @, то вы найдете все почтовые адреса и аккаунты Twitter, которые вы пробивали через Google.
Обратите внимание, что здесь нет поиска по картинкам и видео, но мы их еще обнаружим в папке My Activity.
Какие данные собирает чат Google
Возможно, у вас уже где-то спрятана папка со старыми логами ICQ и вы бы хотели присовокупить к ней еще и все когда-либо написанное через Google Talk и Hangouts. Это вполне реально, но, к сожалению, читать переписку в том виде, в котором она приходит из Takeout, практически невозможно (в отличие, кстати, от логов ICQ).
Весь текст экспортируется как единственный файл JSON плюс горка приложенных картинок — все это лежит в папке Hangouts. С картинками никаких проблем, а вот в JSON на каждое написанное сообщение приходится порядка двух десятков строк метаданных. Но пожалуй, главная головная боль — в том, что вместо имени отправителя здесь ID пользователя.
Наверное, самое простое, что мы можем сделать, — это выкинуть всю мишуру и оставить только текст. По крайней мере можно увидеть какие-то, пусть и обезличенные, беседы.
Так хотя бы есть шанс что-то выловить.
Какие данные собирает Google+
Что действительно есть смысл бэкапить — это посты из социальной сети Google+, которая стремительно становится артефактом прошлого. Если вы, конечно, вообще когда-либо ей пользовались.
Данные поделены на три папки: Google+ Stream, Circles и Pages. Давайте заглянем в них по порядку.
Circles — это контакты людей, организованные по «кругам» из Google Plus. Формат — vCard (VCF) с той информацией, которую люди сами о себе заполнили. Можно при желании одним махом импортировать в любую адресную книгу.
Папка Pages будет присутствовать в том случае, если у вас имелись публичные страницы. Но ничего интересного там нет, разве что юзерпик и обложка страницы.
Также к данным Google+ стоит отнести папку Profile. В ней содержится JSON с копией всех тех данных, что вы заполнили о себе в этой соцсети. Основные интересные вещи лежат в структурах urls (ссылки на другие профили в соцсетях) и organizations (места работы с датами). Забавная деталь: при том, что у меня в профиле не указан возраст, здесь присутствует поле «ageRange»: <«min»: 21>, значение которого Google, кажется, определил самостоятельно.
Самое главное вы найдете в папке Google+ Stream. Здесь в качестве отдельных HTML свалены все ваши посты с комментариями и даже отдельные комментарии. Можно полистать и поностальгировать, а можно парой строк на Python с BeautifulSoup выдрать, к примеру, только тексты постов. Выбирать нужно будет элементы с классами entry-title и entry-content.
К сожалению, картинки из постов не бэкапятся автоматически — они так и остаются ссылками на сервер Google, который еще и не отдаст их без авторизации. Недоработочка!
Какие данные собирает сервис Карты
Еще одна большая и важная категория личных данных. Начнем с простого — папки MyMaps. Это маршруты, созданные вами в Google Maps, — по одному файлу KMZ на маршрут.
KMZ — это формат Google Earth, который поддерживается и в других картографических приложениях. Ну а по сути это ZIP, в котором лежит файл KML, являющийся валидным XML. Если для ваших целей это по каким-то причинам не подходит, можете воспользоваться сервисом GeoConverter и сконвертировать его, например, в GeoJSON, работать с которым немного попроще.
Папка Maps (your places) содержит один файл — Saved Places.json. В нем собраны все ваши закладки из Google Maps в виде очередной заковыристой структуры. Каждая из закладок — это элемент массива features, у которого есть заголовок, дата добавления, дата изменения и ссылка на Google Maps. А вот геокоординаты могут быть записаны по-разному: как поле geometry с массивом coordinates или как Location с полями Latitude и Longitude, но оно же (чтобы жизнь медом не казалась) может называться, например, Geo Coordinates. В общем, при желании учесть все эти особенности не слишком тяжело, но могло бы быть и попроще.
Наконец, самая занимательная папка — это Location History — файл со всей историей ваших перемещений с мобильным телефоном в кармане за все время. У меня эти данные занимают 7,5 Мбайт.
Файл устроен очень просто, особенно в сравнении с другими архивами. Это огромный массив из структур, включающих в себя: время в формате Unix, широту, долготу и точность определения. Иногда к ним добавляются (вероятно, когда их удавалось определить) направление движения в градусах, высота в метрах и точность определения высоты.
Что делать с этим файлом, кроме как сохранить на память?
Например, можете поупражняться в его анализе на Python или на R. Есть и специализированный софт для ковыряния таких данных — Location History Visualizer Pro (стоит 70 долларов), а также любительские сервисы вроде They Know Where You’ve Been (если вы совсем уж не опасаетесь делиться этими данными со случайными людьми).
Однако сам сервис Google здесь пока что вне конкуренции. К Google Maps прилагается утилита Timeline, где накопленные данные можно отсматривать по дням, и здесь, помимо голых данных, которые выдаются через Takeout, есть всякая аналитика. Google, например, определяет названия мест и заведений, которые вы посещали, и прекрасно различает транспортные средства (и может легко понять, например, на мотоцикле вы передвигались, на машине или на велосипеде).
Какие данные собирает Google Chrome
Это крайне интересная папка, которая содержит всю облачную часть Google Chrome (а может быть, и не всю — никогда нельзя быть уверенным!). Вот что в ней лежит.
Bookmarks.html — содержимое закладок в виде списка HTML. Распарсить его не составит труда — хватайте данные из a href и делите на секции по содержимому h3. Для многих закладок указано время добавления в формате Unix.
Dictionary.csv — по всей видимости, здесь должны быть исключения для проверки орфографии, которых у меня нет.
Extensions.json — данные об установленных расширениях.
SearchEngines.json — данные о дополнительных поисковиках. Если вам когда-нибудь понадобятся правила составления поисковых запросов к разным поисковикам, этот файл как раз пригодится. В остальных случаях — вряд ли.
SyncSettings.json — настройки Chrome.
Autofill.json — в теории здесь должны быть данные для автоматического заполнения форм, но у меня только пустой массив. Похоже, если понадобится, эти данные проще вытащить из самого Chrome.
BrowserHistory.json — честно говоря, я ожидал увидеть в этой папке огромный кладезь личной информации: шутка ли — полный список всех сайтов, которые я когда-либо открывал в Chrome! Однако меня ждало разочарование: в этом файле перечислены лишь четырнадцать ссылок, которые я успел открыть в мобильном Chrome, когда скачал его посмотреть. На десктопе при этом внушительный список сайтов и включена галочка Sync Everything. Глюк Takeout?
Если с последним пунктом вам повезет больше, то вы с легкостью сможете проанализировать историю своих перемещений по интернету. Google сохраняет: тип перехода (по ссылке — LINK или напрямую — TYPED), заголовок страницы, URL, ID клиента (полезно, чтобы отличить свой десктоп от телефона и планшета) и время в формате Unix.
Какие данные собирает сервис My Activity
Это, пожалуй, одна из самых интересных папок, возможно даже более интересная, чем история поиска. Ее содержимое дает ответ на вопрос о том, как именно Google следит за пользователями. Пройдясь по папкам, вы можете своими глазами увидеть, что он записывает каждые:
переход на сайт, аффилированный с Google Adwords;
книгу, открытую в Books;
сайт, на который вы заходил через Chrome;
использованный API (папка Developers);
котировку, открытую в Finance;
запрос к Goggles (поиск объектов на снимке);
просмотр страницы в Google Play Store;
обращение к справке (папка Help);
запрос к Image Search и переход по ссылке;
просмотр объекта на карте (Maps);
поиск в Google News и чтение статьи на сайте-источнике;
поисковый запрос и переход по ссылке из результатов (папка Search);
поиск товара или покупку в магазине (папка Shopping);
просмотр поездок в Google Trips;
поиск видео и переход из результатов (Video Search);
голосовой поиск (папка Voice and Audio);
поисковый запрос и просмотр роликов на YouTube.
Отмечу, что история сайтов Chrome у меня была такая же полупустая, как и в папке самого Chrome, а раздел Shopping вообще никуда не годится: за двенадцать лет Google едва отследил пару настоящих покупок. Тем не менее массив информации очень внушительный. Особенно радуют файлы MP3 в папке Voice and Audio: вы можете послушать собственный голос, который произносит фразы из серии «Окей, Гугл…».
Всю ту же информацию вы можете просматривать и фильтровать на сайте «Моя активность». Там же можно удалить отдельные записи и отключить отслеживание отдельных активностей.
При этом формат, в котором все это выгружается, оставляет желать много лучшего. Это снова HTML с не самой удобоваримой разметкой и 150-килобайтным куском Material Design в каждом файле. Я на скорую руку сочинил вот такой скриптик на Python, который можно закинуть в любую из папок и запустить.
Хотите узнать, что известно о вас Google?
Что Google знает о каждом из нас? Давайте узнаем с помощью нового инструмента “О себе”.


Когда-то Google был просто поисковой системой, собирающей данные, чтобы улучшить качество поиска и точнее показывать рекламу. Но со временем эта компания приобрела и создала огромное количество популярных платформ и сервисов, таких как Android, Gmail, Google+, YouTube, Docs, Drive и многие другие.
Вы когда-нибудь думали, сколько персональных данных собирают и хранят эти сервисы? Станет еще интереснее, если задуматься, что в некоторых случаях к ним может получить доступ любой, кто умеет гуглить.

Впрочем, если и раньше вы не сильно переживали по поводу конфиденциальности, не стоит излишне переживать и теперь. Google решил показать, что он лучше Facebook, и создал инструмент, позволяющий пользователям сохранить приватность онлайн.
Недавно поисковый гигант запустил сервис «О себе», показывающий, какая информация о вас доступна с разных Google-платформ. Вы можете опробовать новую функцию, перейдя на https://aboutme.google.com и выбрав «Проверить настройки конфиденциальности».

Кнопка «Начать» отправит вас в виртуальный тур, наглядно показывающий, какие данные о вас собирает Google. Первым пунктом будет информация из соцсети Google+. На каждом этапе вы можете выбрать, какими данными готовы поделиться с окружающим миром.
Во время тура вы увидите оповещения от поискового гиганта в зависимости от того, какими сервисами Google вы пользуетесь. В них будет подробно описано, как отключение той или иной опции помешает работе приложений или операционной системы.

Даже если для защиты ваших персональных данных вы уже создали свой собственный виртуальный Форт-Нокс, инструмент Google все равно будет вам интересен, ведь с его помощью можно увидеть, не утекли ли в Сеть ваши данные без вашего ведома. Мы рекомендуем проводить такую проверку регулярно, так как большинство людей не читают условия использования при установке разнообразных приложений и регистрации на разных сайтах.
Разумеется, создание инструмента для проверки конфиденциальности — отличная идея, но этого недостаточно, чтобы обезопасить свои данные в мире онлайн-рекламы, сторонних приложений и базах ваших поисковых запросов.
В конфиденциальность уже не верят: люди уверены, что «маркетологи так или иначе доберутся до приватных данных» — http://t.co/dyc9L8ieca
Вот пять советов, которые стоит иметь в виду, чтобы обеспечить онлайн-безопасность личных данных.
Более половины Android-клиентов сайтов знакомств не гарантируют сохранность и конфиденциальность данных: http://t.co/cRYggVSurL
Очень важный и нужный совет недели: как защититься от сбора данных в Интернете — https://t.co/ur7xgTeg2X pic.twitter.com/YI7uogDqqG
На наш взгляд, воспользоваться новым инструментом Google стоит как можно быстрее.
«Это рак всего»: почему мы гуглим симптомы и ставим себе страшные диагнозы
![]()

Медицина – одна из популярнейших тематик в интернете. Специалисты «Яндекса» подсчитали, что каждую минуту люди отправляют не менее 5 тысяч запросов на разные медицинские темы. Неисключено, что среди них есть и твои.
Это точно рак!
Идея поинтересоваться, с чем могут быть связаны те или иные симптомы, может показаться не такой уж плохой, тем более что интернет позволяет это делать с легкостью. Но весь вопрос в том, что ты делаешь с полученными результатами. В некоторых случаях они повергают в панику и любой симптом – головную боль, боль в животе, сильную усталость или даже безобидный кашель (привет, коронавирус) – ты связываешь с опасным, редким или даже смертельным заболеванием.
Свой вклад вносит и специфика интернет-поиска. В 2009 году ученые решили выяснить, что именно получают пользователи, которые гуглят безобидные симптомы. Оказалось, что в первой десятке выдачи оказываются сайты, содержащие информацию о самых серьезных и пугающих болезнях. Так, в каждом третьем случае по запросу «головная боль» пользователь получал развернутое описание опухолей головного мозга. Это, конечно, нисколько не способствовало успокоению, а напротив, только усиливало невроз. Люди, у которых и так были все шансы нервничать, например те, у кого в семье были случаи опухолей мозга, тревожились еще сильнее.



