Наглядно о том, как работает свёрточная нейронная сеть

К старту курса о машинном и глубоком обучении мы решили поделиться переводом статьи с наглядным объяснением того, как работают CNN — сети, основанные на принципах работы визуальной коры человеческого мозга. Ненавязчиво, как бы между строк, автор наталкивает на размышления о причинах эффективности CNN и на простых примерах разъясняет происходящие внутри этих нейронных сетей преобразования.
Начинаем сначала
Свёрточная нейронная сеть (ConvNet/CNN) — это алгоритм глубокого обучения, который может принимать входное изображение, присваивать важность (изучаемые веса и смещения) аспектам или объектам изображении и отличать одно от другого. При этом изображения в сравнении с другими алгоритмами требуют гораздо меньше предварительной обработки. В примитивных методах фильтры разрабатываются вручную, но достаточно обученные сети CNN учатся применять эти фильтры/характеристики.
Архитектура CNN аналогична структуре связей нейронов в мозгу человека, учёные черпали вдохновение в организации зрительной коры головного мозга. Отдельные нейроны реагируют на стимулы только в некоторой области поля зрения, также известного как перцептивное поле. Множество перцептивных полей перекрывается, полностью покрывая поле зрения CNN.
Почему слои свёртки расположены над сетью с прямой связью
Изображение — не что иное, как матрица значений пикселей, верно? Так почему бы не сделать его плоским (например, матрицу 3×3 сделать вектором 9×1) и скормить этот вектор многослойному перцептрону, чтобы тот выполнил классификацию? Хм… всё не так просто.
В случаях простейших двоичных изображений при выполнении прогнозирования классов метод может показать среднюю точность, но на практике, когда речь пойдёт о сложных изображениях, в которых повсюду пиксельные зависимости, он окажется неточным.
Сеть CNN способна с успехом схватывать пространственные и временные зависимости в изображении через применение соответствующих фильтров. Такая архитектура за счёт сокращения числа задействованных параметров и возможности повторного использования весов даёт лучшее соответствие набору данных изображений. Иными словами, сеть можно научить лучше понимать сложность изображения.
Входное изображение
На рисунке мы видим разделённое на три цветовых плоскости (красную, зелёную и синюю) RGB-изображение, которое можно описать в разных цветовых пространствах — в оттенках серого (Grayscale), RGB, HSV, CMYK и т. д.
Можно представить, насколько интенсивными будут вычисления, когда изображения достигнут размеров, например, 8 K (76804320). Роль CNN заключается в том, чтобы привести изображения в форму, которую легче обрабатывать, без потери признаков, имеющих решающее значение в получении хорошего прогноза. Это важно при разработке архитектуры, которая не только хорошо изучает функции, но и масштабируется для массивных наборов данных.
Слой свёртки — ядро
1 — количество каналов, например, RGB.
В демонстрации выше зелёная секция напоминает наше входное изображение 5×5×1. Элемент, участвующий в выполнении операции свёртки в первой части слоя свёртки, называется ядром/фильтром K, он представлен жёлтым цветом. Пусть K будет матрицей 3×3×1:
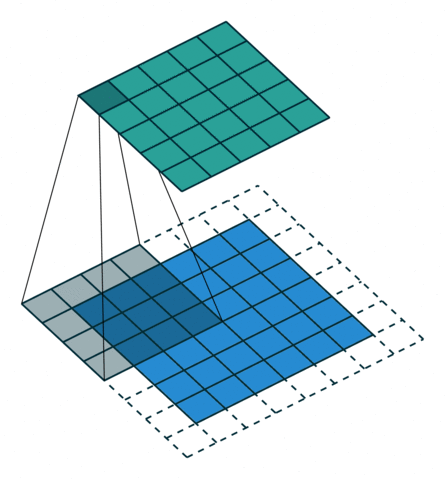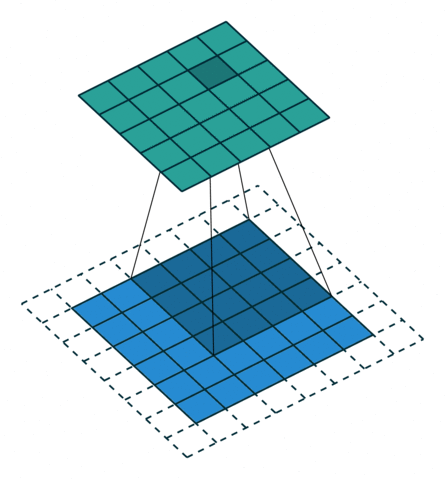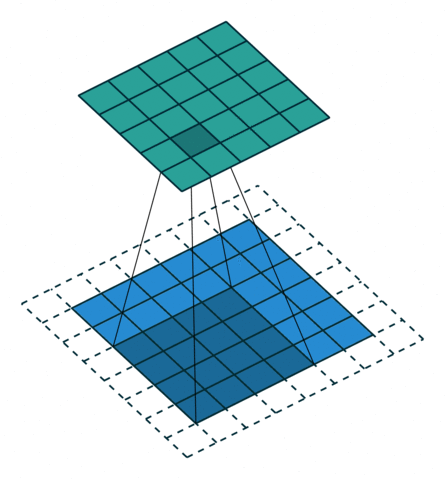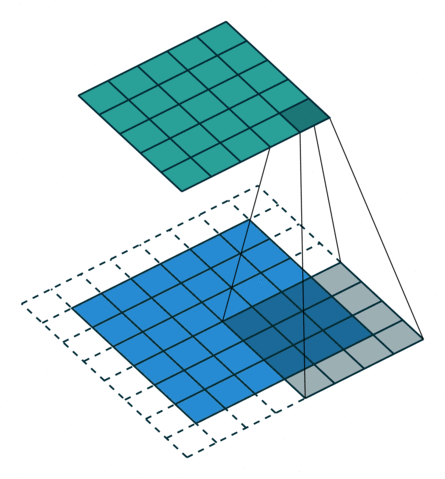
Ядро смещается 9 раз из-за длины шага в единицу (то есть шага нет), каждый раз выполняя операцию умножения матрицы K на матрицу P, над которой находится ядро.
 Перемещение ядра
Перемещение ядра
Фильтр перемещается вправо с определённым значением шага, пока не проанализирует всю ширину. Двигаясь дальше, он переходит к началу изображения (слева) с тем же значением шага и повторяет процесс до тех пор, пока не проходит всё изображение.
Операция свёртки на матрице изображения M×N×3 с ядром 3×3×3
В случае изображений с несколькими каналами (например, RGB) ядро имеет ту же глубину, что и у входного изображения. Матричное умножение выполняется между стеками Kn и In ([K1, I1]; [K2, I2]; [K3, I3]), все результаты суммируются со смещением, чтобы получить уплощённый канал вывода свёрнутых признаков с глубиной в 1.
Операция свёртки с длиной шага, равной 2
Свёртка делается, чтобы извлечь высокоуровневые признаки, например края входного изображения. Сеть не нужно ограничивать единственным слоем. Первый слой условно несёт ответственность за схватывание признаков низкого уровня, таких как кромки, цвет, ориентация градиента и т. д. Через дополнительные слои архитектура адаптируется к признакам высокого уровня, мы получаем сеть со здравым пониманием изображений в наборе данных, похожем на наше.
У результатов свёртки два типа: первый — свёрнутый признак уменьшается в размере по сравнению с размером на входе, второй тип касается размерности — она либо остаётся прежней, либо увеличивается. Это делается путём применения допустимого заполнения в первом случае или нулевого заполнения — во втором.
Нулевое заполнение: для создания изображения 6×6×1 изображение 5×5×1 дополняется нулями
Увеличивая изображение 5×5×1 до 6×6×1, а затем проходя над ним ядром 3×3×1, мы обнаружим, что свёрнутая матрица будет обладать разрешением 5×5×1. Отсюда и название — нулевое заполнение. С другой стороны, проделав то же самое без заполнения, мы обнаружим матрицу с размерами самого ядра (3×3×1); эта операция называется допустимым заполнением.
В этом репозитории содержится множество таких GIF-файлов, они помогут лучше понять, как заполнение и длина шага работают вместе для достижения необходимых результатов.
Слой объединения
Подобно свёрточному слою, слой объединения отвечает за уменьшение размера свёрнутого объекта в пространстве. Это делается для уменьшения необходимой при обработке данных вычислительной мощности за счёт сокращения размерности. Кроме того, это полезно для извлечения доминирующих признаков, которые являются вращательными и позиционными инвариантами, тем самым позволяя поддерживать процесс эффективного обучения модели.
Есть два типа объединения: максимальное и среднее. Первое возвращает максимальное значение из покрытой ядром части изображения. А среднее объединение возвращает среднее значение из всех значений покрытой ядром части.
Максимальное объединение также выполняет функцию шумоподавления. Оно полностью отбрасывает зашумленные активации, а также устраняет шум вместе с уменьшением размерности. С другой стороны, среднее объединение для подавления шума просто снижает размерность. Значит, можно сказать, что максимальное объединение работает намного лучше среднего объединения.
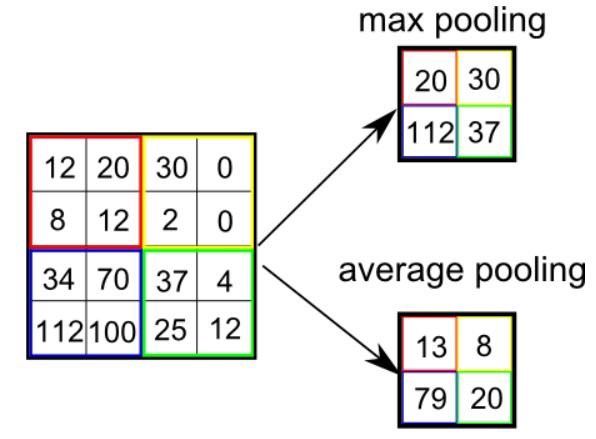 Типы объединения
Типы объединения
Слои объединения и свёртки вместе образуют i-тый слой свёрточной нейронной сети. Количество таких слоёв может быть увеличено в зависимости от сложности изображений, чтобы лучше схватывать детали, но это делается за счёт увеличения вычислительной мощности.
Выполнение процесса выше позволяет модели понимать особенности изображения. Преобразуем результат в столбцовый вектор и скормим его обычной классифицирующей нейронной сети.
Классификация — полносвязный слой

Добавление полносвязного слоя — это (обычно) вычислительно недорогой способ обучения нелинейным комбинациям высокоуровневых признаков, которые представлены на выходе слоя свёртки. Полносвязный слой изучает функцию в этом пространстве, которая может быть нелинейной.
После преобразования входного изображения в подходящую для многоуровневого перцептрона форму мы должны сгладить изображение в вектор столбец. Сглаженный выходной сигнал подаётся на нейронную сеть с прямой связью, при этом на каждой итерации обучения применяется обратное распространение. За серию эпох модель обретает способность различать доминирующие и некоторые низкоуровневые признаки в изображениях и классифицировать их методом классификации Softmax.
У CNN есть различные архитектуры, сыгравшие ключевую роль в построении алгоритмов, на которых стоит и в обозримом будущем будет стоять искусственный интеллект в целом. Некоторые из этих архитектур перечислены ниже:
Репозиторий с проектом по распознаванию цифр.
CNN имеет огромное количество практических приложений; и если вам интересны эксперименты и поиски в области ИИ, обратите внимание на наш курс о машинном и глубоком обучении или прокачайтесь в работе с данными или освойте перспективную специальность с помощью нашего флагманского курса о Data Science.
Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Принцип работы свёрточной нейронной сети. Просто о сложном
Глубокие нейронные сети привели к прорыву во множестве задач распознавания образов, таких как компьютерное зрение и распознавание голоса. Сверточная нейронная сеть один из популярных видов нейронных сетей.
В своей основе сверточную нейронную сеть можно рассматривать как нейронную сеть, использующую множество идентичных копий одного и того же нейрона. Это позволяет сети иметь ограниченное число параметров при вычислении больших моделей.
2D Свёрточная нейронная сеть
Этот приём с несколькими копиями одного и того же нейрона имеет близкую аналогию с абстракцией функций в математике и информатике. При программировании функция пишется один раз и затем повторно используется, не требуя писать один и тот же код множество раз в разных местах, что ускоряет выполнение программы и уменьшает количество ошибок. Аналогично сверточная нейронная сеть, однажды обучив нейрон, использует его во множестве мест, что облегчает обучение модели и минимизирует ошибки.
Структура сверточных нейронных сетей
Предположим, дана задача в которой требуется предсказать по аудио, есть ли голос человека в аудиофайле.
На входе получаем образцы аудио в разные моменты времени. Образцы равномерно распределены.
Самый простой способ классифицировать их с нейронной сетью — подключить все образцы к полносвязному слою. При этом каждый вход соединяется с каждым нейроном.
Более сложный подход учитывает некоторую симметрию в свойствах, которые которая находится в данных. Мы уделяем много внимания локальным свойствам данных: какая частота звука в течение определенного времени? Увеличивается или уменьшается? И так далее.
Мы учитываем те же свойства во все моменты времени. Полезно знать частоты вначале, середине и в конце. Обратите внимание, что это локальные свойства, поскольку нужно только небольшое окно аудиопоследовательности, чтобы определить их.
Таким образом, возможно создать группу нейронов A, которые рассматривают небольшие сегменты времени в наших данных. A смотрит на все такие сегменты, вычисляя определенные функции. Затем, выход этого сверточного слоя подается в полносвязный слой F.
В приведенном выше примере A обрабатывало только сегменты, состоящие из двух точек. Это редко встречается на практике. Обычно, окно слоя свертки намного больше.
В следующем примере A получает на вход 3 отрезка. Это тоже маловероятно для реальных задач, но, к сожалению, сложно визуализировать A, соединяющее множество входов.
Одно приятное свойство сверточных слоев состоит в том, что они являются составными. Можно подавать вывод одного сверточного слоя в другой. С каждым слоем сеть обнаруживает более высокие, более абстрактные функции.
В следующем примере есть новая группа нейронов B. B используется для создания еще одного сверточного слоя, уложенного поверх предыдущего.
Сверточные слои часто переплетены pooling (объединяющими) слоями. В частности, есть вид слоя, называемый max-pooling, который чрезвычайно популярен.
Часто, нас не волнует точный момент времени, когда присутствует полезный сигнал в данных. Если изменение частоты сигнала происходит раньше или позже, имеет ли это значение?
Max-pooling вбирает максимум фичей из небольших блоков предыдущего уровня. Вывод говорит, присутствовал ли полезный сигнал функции в предыдущем слое, но не точно где.
Max-pooling слоев — это «уменьшение». Оно позволяют более поздним сверточным слоям работать на больших участках данных, потому что небольшие патчи после слоя объединения соответствует гораздо большему патчу перед ним. Они также делают нас инвариантными к некоторым очень небольшим преобразованиям данных.
В наших предыдущих примерах использовались одномерные сверточные слои. Однако сверточные слои могут работать и с более объемными данными. Фактически самые известные решения на базе сверточных нейронных сетей используют двумерные сверточные нейронные сети для распознавания образов.
В двумерном сверточном слое вместо того, чтобы смотреть на сегменты, A будет смотреть патчи.
Для каждого патча, A будет вычислять функции. Например, она может научиться обнаруживать наличие края, или текстуру, или контраст между двумя цветами.
В предыдущем примере вывод сверточного слоя подавался в полносвязный слой. Но, возможно составить два сверточных слоя, как это было в рассмотренном одномерном случае.
Мы, также можем выполнять max-pooling в двух измерениях. Здесь мы берем максимум фичей из небольшого патча.
Это сводится к тому, что при рассмотрении целого изображения не важно точное положение края, вплоть до пикселя. Достаточно знать, где он находится в пределах нескольких пикселей.
Также, иногда используются трехмерные сверточные сети для таких данных, таких как видео или объемные данные (например, 3D-сканирование в медицине). Однако, такие сети не очень широко используются, и гораздо сложнее в визуализации.
Ранее, мы говорили, что A — группа нейронов. Будем более точными в том: что такое А?
В традиционных сверточных слоях A представляет собой параллельную связку нейронов, все нейроны получают одинаковые входные сигналы и вычисляют разные функции.
Например, в двумерном сверточном слое один нейрон может обнаруживать горизонтальные края, другой, вертикальные края, а третий зелено-красные цветовые контрасты.
В статье ‘Network in Network’ (Lin et al. (2013)) предлагается новый слой «Mlpconv». В этой модели, A имеет несколько уровней нейронов, причем последний слой выводит функции более высокого уровня для обрабатываемого региона. В статье, модель достигает впечатляющих результатов, устанавливая новый уровень техники в ряде эталонных наборов данных.
Для целей этой публикации мы сосредоточимся на стандартных сверточных слоях.
Результаты сверточных нейронных сетей
В 2012 году Alex Krizhevsky, Ilya Sutskever, и Geoff Hinton достигли существенного улучшения качества распознавания в сравнении с известными на тот момент решениями (Krizehvsky et al. (2012)).
Прогресс был результатом объединения нескольких подходов. Использовались графические процессоры для обучения большой (по меркам 2012 года), глубокой нейронной сети. Использовался новый тип нейронов (ReLU) и новая техника для уменьшения проблемы, называемой «overfitting» (DropOut). Использовали большой набор данных с большим количеством категорий изображений (ImageNet). И конечно же, это была сверточная нейронная сеть.
Архитектура, показанная ниже, была глубокой. Она имеет 5 сверточных слоев, 3 pooling с чередованием и три полносвязных слоя.
From Krizehvsky et al. (2012)
Сеть была обучена классификации фотографий в тысячи разных категорий.
Модель Крижевского и др. была способна дать правильный ответ в 63% случаев. Кроме того, правильный ответ из 5 лучших ответов, присутствует 85% прогнозов!
Проиллюстрируем, что узнает первый уровень сети.
Напомним, что сверточные слои были разделены между двумя графическими процессорами. Информация не идет назад и вперед по каждому слою. Оказывается, каждый раз, когда модель запускается, обе стороны специализируются.
Фильтры, полученные первым сверточным слоем. Верхняя половина соответствует слою на одном графическом процессоре, нижняя — на другом. From Krizehvsky et al. (2012)
Нейроны с одной сторону, фокусируются на черно-белом цвете, учась обнаруживать края разных ориентаций и размеров. Нейроны с другой стороны, специализируются на цвете и текстуре, обнаруживают цветовые контрасты и узоры. Помните, что нейроны случайным образом инициализируются. Ни один человек не пошел и не поставил их пограничными детекторами, или разделил таким образом. Это произошло при обучении сети классификации изображений.
Эти замечательные результаты (и другие захватывающие результаты примерно в то время) были только началом. За ними быстро последовало множество других работ, которые тестировали измененные подходы и постепенно улучшали результаты или применяли их в других областях.
Сверточные нейронные сети являются важным инструментом в компьютерном видении и современном распознавании образов.
Формализация сверточных нейронных сетей
Рассмотрим одномерный сверточный слой с входами
Сравнительно легко описать результаты в терминах входных данных:
Например, в приведенном выше примере:
у0 = А (х0, х1)
y1 = А (x1, x2)
Аналогично, если мы рассмотрим двумерный сверточный слой с входами
Сеть можно представить двумерной матрицей из значений.
Глубокие свёрточные нейросети: руководство для начинающих

Jul 18, 2020 · 14 min read

Перед прочтением
Введение
С появлением глубокого обучения “компьютерное зрение” пере ш ло на новую ступень развития. На смену разрозненным значениям пикселей и ограниченному количеству созданных вручную признаков пришли способы сделать машинное распознавание деталей изображения более простым и понятным — это привело к смене парадигмы в этой области. Сегодня в привычных нам вещах из сфер производства и торговли используется множество самых современных приложений для компьютерного зрения. Недавний прорыв в сфере глубокого обучения в компьютерном зрении привнёс колоссальные изменения в нашу повседневную жизнь. Вы могли даже не заметить, как именно в каких-то вещах используется компьютерное зрение. Вот несколько любопытных примеров: автопилот в автомобилях Tesla, разблокировка с помощью Face ID, Animoji и продвинутый функционал камеры в iPhone, эффект боке в режиме портретной съёмки, фильтры в мессенджерах Snapchat и Facebook и т. д.
Основная идея компьютерного зрения начинается с очень простой задачи — определить, что изображено на картинке. Оказывается, эту задачу чрезвычайно сложно решить, хотя мы, люди, легко справляемся с ней.
В цифровом формате изображения представлены в виде 3D-матрицы из значений пикселей (длины, ширины и цветовых каналов RGB). Извлекать информацию из этой 3D-матрицы не так уж просто.
Немного истории
Устаревшие решения для компьютерного зрения
С появлением машинного обучения проблемы компьютерного зрения решались относительно успешно. Прежде всего, в этом помогали созданные вручную признаки и традиционные алгоритмы машинного обучения, такие как метод опорных векторов (SVM). Созданные вручную признаки — это параметры изображений, извлекаемые с помощью множества других алгоритмов. Типичный пример — поиск контуров и углов. Простой алгоритм контурного детектора ищет области резкого изменения насыщенности изображения, то есть большую разницу в значениях соседних пикселей. Несколько таких вот простых и пара более сложных признаков выделялись с помощью комбинации алгоритмов и далее передавались алгоритму контролируемого машинного обучения.
Такой подход работает, однако результаты не особо впечатляют. Прежде всего, чтобы создать признаки самостоятельно, придётся приложить немало усилий, скажу больше — это требует серьёзного уровня предметных знаний. К тому же признаки сильно отличаются от случая к случаю. К примеру, то, что создано для диагностики переломов на рентгеновских снимках, вполне может не подойти для распознавания имени на почтовой посылке.

Чтобы упросить процесс создания признаков, мы можем представить изображение в табличной форме, то есть когда каждый пиксель преобразуется в признак. Однако результат неутешительный: не остаётся практически никакой информации, которую может использовать нейросеть/алгоритм МО — отсюда плохая производительность.

Из сказанного выше можно выделить важный момент: извлечение признаков из изображения — неизбежная, но трудно реализуемая необходимость.
Рассмотрим несколько примеров, чтобы понять, почему задачи, предполагающие использование компьютерного зрения, сложно решить. Для простоты давайте предположим, что наша бинарная задача — найти на картинке кошку.
Взгляните на два изображения ниже: если основываться на значениях пикселей, эти изображения имеют совершенно разное представление в цифровом формате. Поскольку в пикселе передаётся только его цвет, семантическое значение исходного представления неочевидно.

К тому же часто окрас кошки сливается с фоном. Посмотрите на изображения ниже: применение традиционных признаков оказалось бы безрезультатным. Таким образом, созданные вручную признаки здесь менее эффективны.

К тому же кошку можно сфотографировать во множестве совершенно разных поз, и это ещё больше усложняет процесс. Далее представлено всего несколько возможных вариантов.

При перенесении этих проблем на более общие случаи (к примеру, на поиск множества объектов на изображении) сложность возрастает экспоненциально.
Очевидно, что табличное представление пикселей, самостоятельное создание признаков для поиска конкретных параметров или сочетание двух этих подходов — не лучшие способы решать задачи, связанные с компьютерным зрением.
Есть ли лучшее решение?
Как показал опыт, созданные вручную признаки пусть и требуют много усилий, но всё же в некоторой степени способны решать стоящие перед ними задачи. Однако этот процесс получился бы крайне дорогостоящим, а для решения каждой отдельной задачи требовались бы обширные предметные знания.
Что если автоматизировать извлечение признаков?
К счастью, такое возможно, и это наконец подводит нас к нашей основной теме — свёрточным нейронным сетям. СНС предоставляют продвинутые способы решения задач компьютерного зрения с использованием универсального, масштабируемого, самодостаточного подхода, который можно применять к разным предметным областям без необходимости знать о них что-либо. Больше не требуется создавать признаки самим, поскольку нейросеть сама учится извлекать полезные признаки при достаточном обучении и объёме данных.
О глубоких свёрточных нейронных сетях впервые заговорили в своих публикациях Хинтон, Крижевский и Суцкевер. Тогда такие сети применялись, чтобы добиться высочайшей производительности в работе по классификации проекта ImageNet. Это исследование совершило революцию в сфере компьютерного зрения.
Подробнее о глубоких свёрточных нейросетях
Обобщённая архитектура СНС показана ниже. Некоторые детали пока могут казаться неясными, но подождите немного — скоро мы подробно разберём каждый компонент. Компонент извлечения (экстрактор) признаков в этой архитектуре — это комбинация свёртки и пулинга. Вероятно, вы заметили, что этот компонент повторяется — такое можно увидеть в большинстве современных архитектур. Эти экстракторы извлекают вначале низкоуровневые признаки (например, контуры и линии), затем среднеуровневые (формы и комбинации из нескольких низкоуровневых признаков) и, наконец, высокоуровневые признаки (ухо/нос/глаза в примере с распознаванием кошки). В конце эти слои уплощаются и связываются с выходным слоем функцией-активатором (как и в нейронных сетях прямого распространения).

Начнём с основ
Давайте разберёмся, как человеческий мозг распознаёт образы с помощью зрения. Говоря простым языком, наш мозг принимает сигналы с сетчатки о полученных из внешнего мира визуальных образах. Сначала распознаются контуры, затем эти контуры помогают распознать изгибы, потом идут более сложные паттерны (например, форма) и т. д. Иерархическая организация нейронной активности от контуров до линий, изгибов и всё усложняющихся форм помогает идентифицировать конкретный объект. Конечно, это очень упрощённая интерпретация процесса, и человеческий мозг одновременно производит гораздо более сложные операции.
По аналогии с этим в свёрточных нейросетях изучение элементарных признаков происходит в первичных слоях. Слово “глубокий” в выражении “глубокие СНС” относится к количеству слоёв в сети. В обычной СНС, как правило, бывает 5–10 и даже больше слоёв по изучению признаков. Архитектуры самых современных приложений включают нейросети с более 50–100 слоями. Работа СНС схожа с упрощённой моделью работы человеческого мозга по распознаванию визуальных компонентов в зрительной коре.
Подробнее о структуре СНС
“Свёртка” — операция из области обработки сигнала. В глубоком обучении это перемножение матрицы изображения (собственно матрица) и ядра/фильтра (ещё одна матрица меньшего размера) путём прохождения через длину и ширину. На анимации ниже демонстрируется свёртка фильтра/ядра размером 3×3 и изображения размером 5×5. Результат свёртки — изображение меньшего размера (3×3).
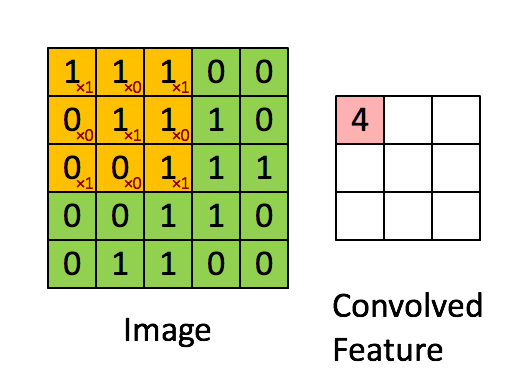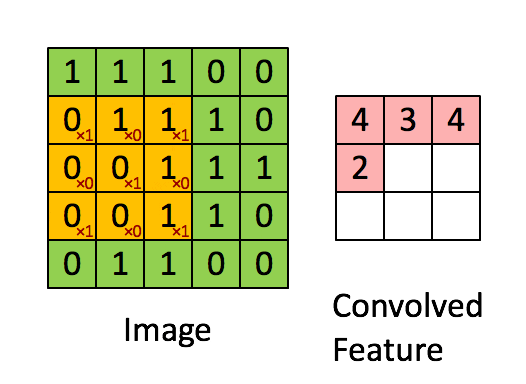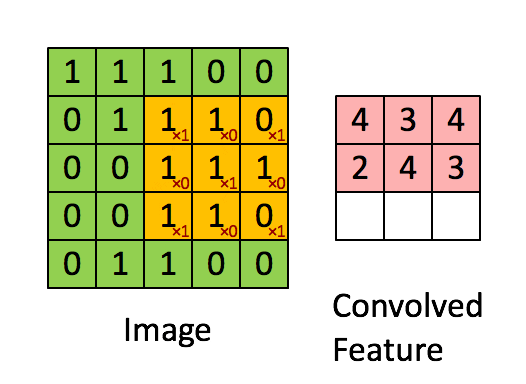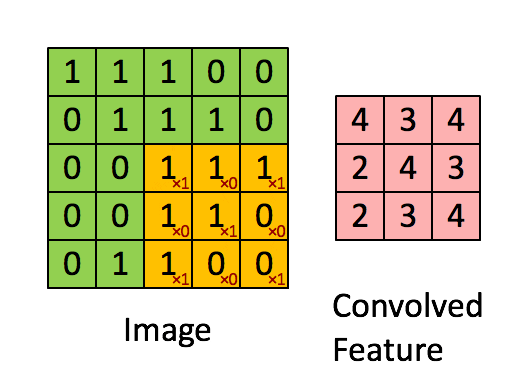
Это перемножение матриц по сути является основой извлечения признаков. Опираясь на верные значения в ядре, можно извлечь значимые признаки изображения. Пример применения такой манипуляции приведён ниже. Можно заметить, что оригинальное изображение не меняется, если использовать ядро в качестве матрицы тождественности. Однако при использовании разных ядер результат может напоминать применение других контурных детекторов и техник сглаживания или увеличения резкости изображения.

Это один аспект компонента. Другой его аспект — пулинг. Слой пулинга помогает сократить пространственное представление изображения, чтобы уменьшить количество параметров и объём вычислений в сети. Это простая операция: надо только задать максимальное значение определённому размеру ядра. Ниже дан простой пример пулинга: он проводится с использованием ядра размером 10×10 на выходе свёртки (другой матрицы) размером 20×20. В итоге получается матрица размером 2×2.
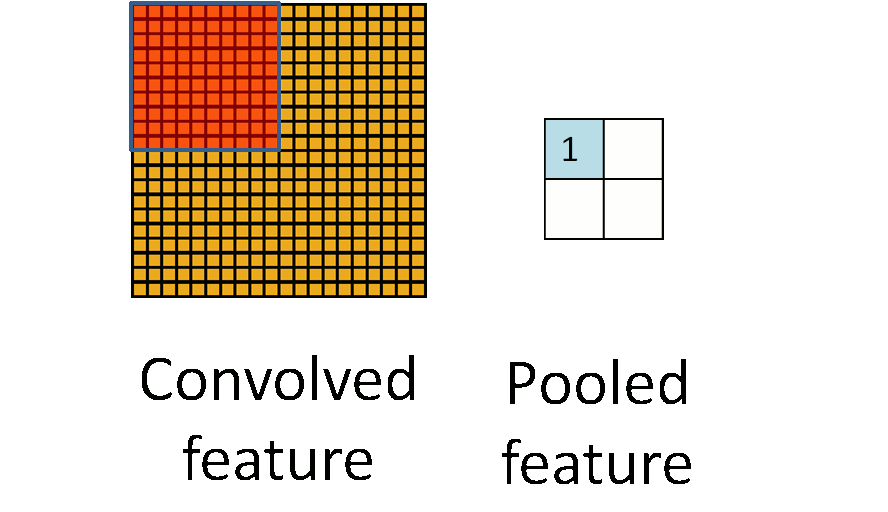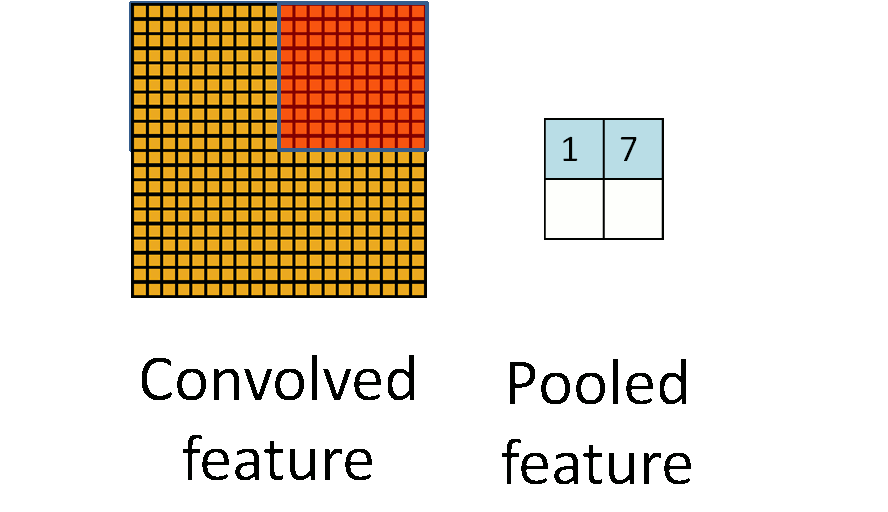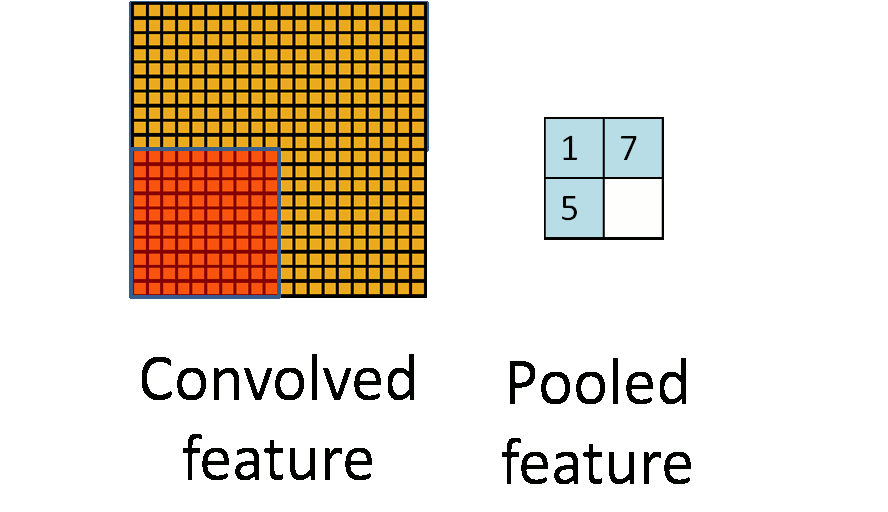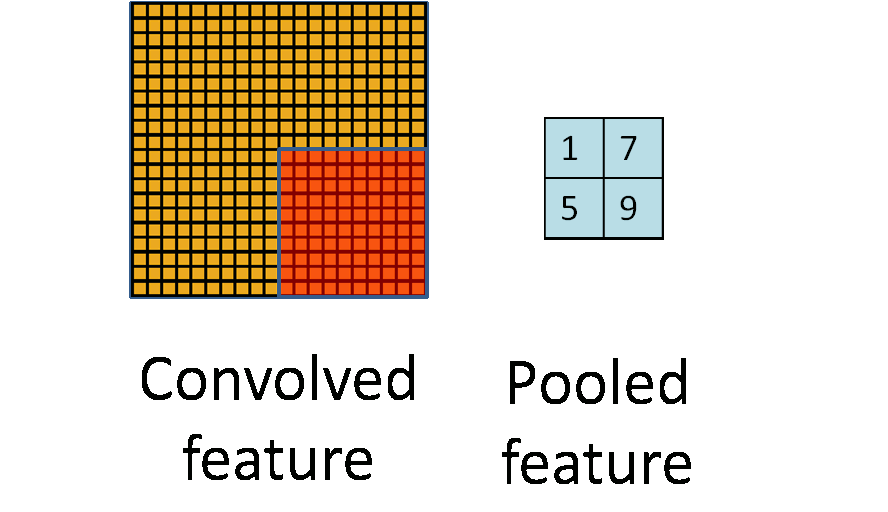
Используя комбинацию слоёв свёртки и слоёв пулинга (с определением максимального значения), мы получаем основной структурный элемент СНС. Свёртка и пулинг уменьшают исходные размеры изображения на входе в зависимости от размеров ядра и пулинга. Применяя свёртку с одним ядром, получаем карту признаков. В СНС обычно применяется несколько ядер на одну свёртку. На рисунке ниже показаны карты признаков, извлечённых из n ядер при свёртке.

Многократное повторение этого процесса приводит к углублению свёрточных нейронных сетей. Каждый слой извлекает признаки из предыдущего. Иерархическая организация слоёв способствует последовательному изучению признаков: от контуров к более сложным признакам, созданным из простых, и далее к высокоуровневым признакам, которые уже содержат достаточно информации для составления нейросетью точного прогноза.
Последний свёрточный слой связан с полносвязным слоем, который используется для применения подходящей функции-активатора для прогнозирования выхода: для бинарных выходов используется сигмоидная, а для небинарных — многопеременная функция.
Вся описанная архитектура в упрощённом виде показана ниже.

До сих пор мы не уделяли внимание нескольким важным аспектам сложной архитектуры СНС. Я сделал это специально, чтобы не усложнять и помочь вам разобраться с основами структурных элементов СНС.
Вот ещё пара ключевых понятий:
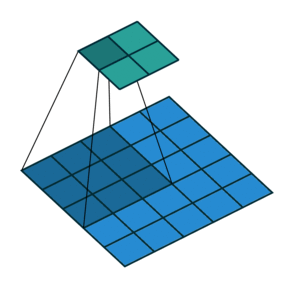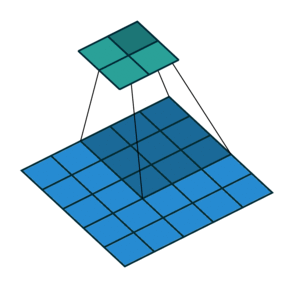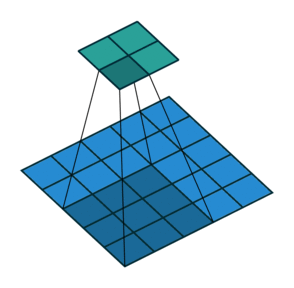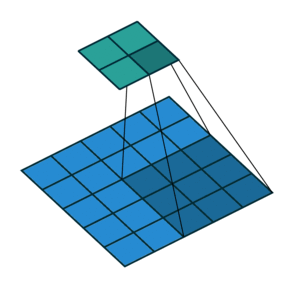
Две иллюстрации ниже отлично демонстрируют понятия дополнения и шага.
2. Шаги без дополнения ( голубым показан вход, зелёным — выход):
Есть ещё пара важных аспектов, которых мы пока не касались — слои пакетной нормализации и слои исключения. Оба эти понятия значимы и важны для СНС. Сегодня мы определяем сегмент свёртки как комбинацию трёх компонентов ( свёртка + пулинг с определением максимального значения + пакетная нормализация), а не двух первых. Пакетная нормализация — это приём, который помогает упростить обучение очень глубоких нейронных сетей путём стандартизации входов в слой для каждого мини-пакета. Стандартизация входов стабилизирует процесс обучения и таким образом уменьшает количество эпох обучения глубоких нейросетей.
В свою очередь исключение — это приём регуляризации, который отлично справляется с переобучением и чрезмерным обобщением.
Связываем всё воедино
Теперь, когда мы уже неплохо разбираемся в основных структурных элементах свёрточной нейронной сети, уверен, у вас появились более детальные вопросы. Самые важные, которые могли возникнуть, касаются фильтров: “Как решить, какие фильтры использовать?”, “Сколько фильтров использовать?” и т. п.
Давайте отдельно ответим на каждый из этих вопросов.
Как решить, какие фильтры использовать?
Ответ на этот вопрос простой. Мы устанавливаем фильтры со случайными значениями на основе нормального или какого-либо другого распределения. Эта идея может казаться немного неоднозначной и трудной для понимания, однако она хорошо работает. В процессе обучения нейронная сеть постепенно изучает лучшие фильтры, которые помогают извлекать максимум информации, необходимой для точного прогноза метки. Здесь-то и случается магия: мы, строго говоря, избавляемся от необходимости создавать признаки самостоятельно. При достаточном обучении и объёме данных нейросеть сама создаёт подходящие фильтры для извлечения наиболее значимых признаков.
Сколько фильтров использовать в каждом сегменте свёртки?
Здесь нет никаких стандартов. Размер и количество фильтров — настраиваемые гиперпараметры. Универсальное правило — использовать фильтры с нечётными размерами (3×3, 5×5, 7×7). Также крупным фильтрам обычно предпочитают маленькие, но возможны и компромиссные соотношения, которые надо вычислять эмпирически.
Как обучается сеть?
Процесс похож на обучение нейросетей прямого распространения, которые мы обсуждали в предыдущей статье. Мы используем алгоритм обратного распространения ошибки, для того чтобы сеть меняла веса фильтров и изучала основные признаки изображения. Обучение позволяет нейросети находить оптимальные фильтры для извлечения максимального объёма информации из изображений на входе.
Изображение выше было обычным 2D, в то время как большинство изображений представляют собой 3D. Как нейросеть работает с 3D?
2D-изображения демонстрировались для простоты. Большинство используемых изображений — 3D с цветовыми каналами (RGB). В этом случае ничего не меняется, кроме измерений ядра. Ядра будут трёхмерными, где третье измерение равно количеству каналов: например, 5x5x 3 для 3 цветовых каналов (R, G и B) в изображении на входе.
Какая разница между свёрточными нейронными сетями и глубокими свёрточными нейронными сетями?
Это одно и то же. Слово “глубокий” здесь относится к количеству слоёв в архитектуре. Большинство современных СНС содержит от 30 до 100 слоёв.
Нужны ли для обучения СНС графические процессоры (GPU)?
Не обязательны, но желательны. Эффективное использование GPU позволяет увеличить скорость обработки изображений при обучении нейросетей примерно в 50 раз. Платформы Kaggle и Google Colab предоставляют бесплатные (с ограниченной частотой использования в неделю) окружения с поддержкой GPU.
Заканчиваем с основами — впереди реальный пример
Давайте на практике разберём пример, который демонстрирует создание свёрточной нейронной сети при помощи библиотеки PyTorch.
Здесь нам пригодится всё вышеизложенное.
Для начала давайте импортируем все необходимые пакеты: утилиты, модули ядер нейронной сети и несколько внешних модулей из библиотеки Scikit-learn для оценки производительности нейросети.
Далее загружаем набор данных из памяти. К примеру, я использую набор данных MNIST в csv-формате с Kaggle. Вы можете найти полный набор здесь.

Теперь, когда мы загрузили данные, давайте преобразуем их в представление, понятное PyTorch.

Настало время определить архитектуру СНС, а также дополнительные функции, которые пригодятся при оценке и составлении прогнозов.

И, наконец, давайте обучим модель.
Теперь у нас есть простая модель с периодом обучения в 5 эпох. В большинстве случаев для достижения отличной производительности требуется более 30 эпох. Давайте посчитаем точность в наборе данных для проверки и построим матрицу неточностей.

На этом мы заканчиваем наше поверхностное знакомство с этой сложной темой. Надеюсь, вам понравилось. Также рекомендую попрактиковаться с этим замечательным инструментом, чтобы понимать, как каждый слой генерирует фильтры и карты признаков для разных входных изображений.
Вы также можете загрузить всю памятку целиком с моего репозитория — PyTorchExamples.
Заключение
Целью этой статьи было познакомить новичков с основами темы, используя простые объяснения. Упрощение расчётов и сосредоточение на функционале позволит эффективно использовать глубокие свёрточные нейросети для современных корпоративных проектов.



