4 способа развернуть собственный аналог Dropbox

Хотите получить облачное хранилище, но при этом иметь больше контроля над вашим сервисом, чем вы могли бы получить от Dropbox и его конкурентов? Здесь представлены несколько способов, чтобы создать ваше собственное хранилище в стиле Dropbox.
Первый метод основан на использовании GlusterFS, второй использует Git для синхронизации файлов. Эти проекты предназначены для Unix-подобных операционных систем, таких как Linux и OSX, но некоторые могут также работать и под Cygwin.
Использование GlusterFS
Джефф Дарси из CloudFS написал учебник по построению собственных Dropbox-подобных сервисов с помощью GlusterFS с помощью монтирования файловых систем с удаленного сервера на локальный компьютер. Он использует Rackspace Cloud для его приложения, но отмечает, что это должно работать и на любых виртуальных выделенных серверах (VPS) (и, конечно же, не виртуальных серверах тоже).
Недостатком такого подхода является отсутствие доступа в автономном режиме — то есть вместо синхронизации папок мы получаем удаленное место, работающее как локальная папка. Это может быть решено с использованием Rsync или других приложений для синхронизации.
SparkleShare
DVCS-Autosync
DVCS-AutoSync — это другая, основанная на Git, opensource-альтернатива Dropbox, также поддерживающая Mercurial и другие распределенные системы контроля версий. Он предоставляет большую функциональность, чем SparkleShare, но немного сложнее в установке.
Программа Dropbox: преимущества, функции, использование
 Dropbox — облачное хранилище, которое предназначено для обмена и хранения файлов. Программа была разработана Дью Хьюстоном. Стабильная версия хранилища появилась в общем доступе в 2010 году. Dropbox стал программой, которая послужила базой для создания множества современных хранилищ.
Dropbox — облачное хранилище, которое предназначено для обмена и хранения файлов. Программа была разработана Дью Хьюстоном. Стабильная версия хранилища появилась в общем доступе в 2010 году. Dropbox стал программой, которая послужила базой для создания множества современных хранилищ.
Дропбокс можно установить на ПК, ноутбук, планшет и смартфон. Программу можно инсталлировать на такое программное обеспечение:
Приложение после установки появляется на рабочем столе в виде папки, которая дает доступ к облаку. Лимит памяти хранилища зависит от версии программы. Рассмотрим главные функции, преимущества и особенности использования приложения, для чего программа Dropbox нужна, а также что такое Dropbox на андроиде более подробно.
Основные функции
 Среди основных функций приложения можно выделить следующие:
Среди основных функций приложения можно выделить следующие:
Рассмотрим же основные преимущества и недостатки облачного хранилища Dropbox.
Преимущества Dropbox
 Дропбокс — программа, которая стала базой для разработки множества современных приложений облачного хранения и обмена файлами, а потому она имеет ряд преимуществ. Основными из них являются следующие:
Дропбокс — программа, которая стала базой для разработки множества современных приложений облачного хранения и обмена файлами, а потому она имеет ряд преимуществ. Основными из них являются следующие:
Использование Dropbox позволяет значительно сэкономить время современному человеку. Облачное хранилище открывает новые возможности в учебе и бизнесе, позволяет планировать встречи, редактировать и создавать файлы сразу на нескольких устройствах и многое другое. При этом необязательно покупать платную версию. Для личного использования достаточно будет установить бесплатную программу.
Недостатки
Несмотря на все преимущества и удобства хранилища, Dropbox все же имеет и некоторые недостатки, главным из которых является отсутствие шифрования данных. Это означает, что в случае взлома удаленного сервера информация будет доступной хакеру, так как не защищена кодом. А потому хранить в облаке важные данные, такие, как пароли, логины, номера кредитных карт и банковских счетов и другую подобную информацию, не стоит.
Как установить и зарегистрироваться
 Чтобы начать пользоваться Дропбоксом, необходимо зарегистрироваться на сайте Dropbox, после чего скачать приложение. Для регистрации вам понадобится ввести следующие данные:
Чтобы начать пользоваться Дропбоксом, необходимо зарегистрироваться на сайте Dropbox, после чего скачать приложение. Для регистрации вам понадобится ввести следующие данные:
Также вам нужно будет согласиться с условиями использования программы, после чего выбрать тарифный план.
Тарифные планы приложения
Dropbox имеет несколько тарифов. Установить программу можно в трех версиях:
Благодаря нескольким тарифным планам можно подобрать Dropbox для личных нужд, учебы или ведения предпринимательской деятельности за соответствующую цену.
После этого можно перейти к скачиванию приложения. Для этого нужно перейти на официальный сайт по адресу dropbox.com и загрузить установочный файл, после чего открыть его, выбрать русский язык интерфеса и следовать инструкциям мастера установок.
После инсталляции приложения необходимо будет войти в зарегистрированный аккаунт, введя в высветившимся окне электронный адрес и пароль. Также можно сделать процедуру в обратном порядке: сначала скачать приложение, а после пройти регистрацию.
Рассмотрим установку и регистрацию по шагам:
После этого на рабочем столе появится рабочая папка Dropbox. Как начать работать с приложением, рассмотрим далее.
Как пользоваться Dropbox
 Использование облака не является чем-то сложным. Разобраться с Dropbox сможет абсолютно каждый, благодаря удобному интерфейсу.
Использование облака не является чем-то сложным. Разобраться с Dropbox сможет абсолютно каждый, благодаря удобному интерфейсу.
Интерфейс
Интерфейс приложения простой. После установки программы откроется обучающая инструкция, которая расскажет о том, что Dropbox работает по принципу обычной компьютерной папки, за исключением того, что файлы, помещенные в нее, хранятся не на жестком диске, а на удаленном сервере. А потому для того, чтобы проводить различные операции с файлами (сохранять, перемещать, изменять и удалять их), вам понадобится иметь доступ к Интернету. При этом в Dropbox можно создать различные папки, где легко упорядочить информацию по темам, форматам или датам.
Настройки
В зависимости от того, на какое устройство установлено хранилище, а также от версии и тарифа приложения, можно выбрать различные настройки. Так, используя Dropbox на смартфоне, можно выбрать, что фото и видео будут сразу сохраняться в облачном хранилище. Инсталлировав приложение на ноутбук или компьютер, можно сделать Dropbox папкой загрузок.
В расширенной и бизнес-версиях Dropbox можно устанавливать настройки совместного доступа, при этом в business приложении доступ можно делать многоуровневым, чтобы было удобнее работать.
Также можно контролировать действия своих сотрудников, просматривая через журнал, какой именно пользователь внес последние изменения в файл.
Также есть возможность ведения журнала действий, который позволит восстанавливать удаленные и измененные файлы.
В настройках можно также выбрать такие функции:
Как добавлять файлы
 Для того чтобы добавить файлы в Dropbox, вам достаточно просто скопировать или переместить их в папку на вашем устройстве, после чего данные будут сохранены на удаленном сервисе облака.
Для того чтобы добавить файлы в Dropbox, вам достаточно просто скопировать или переместить их в папку на вашем устройстве, после чего данные будут сохранены на удаленном сервисе облака.
На Dropbox можно хранить файлы такого типа:
То есть на Дропбоксе можно хранить данные любого типа и формата в ограничении по объему согласно выбранному тарифу.
Как удалить Dropbox
 В случае, если программа более не нужна, то ее можно деинсталлировать. При этом вы не потеряете свой аккаунт и при необходимости сможете снова установить программу на свое устройство. Для того чтобы удалить приложение, вам достаточно выйти из Dropbox, после чего зайти в «Пуск», выбрать «Панель управления», перейти в «Программы и компоненты». В высветившемся списке программ найти Dropbox и нажать «Удалить приложение». После этого высветится окно деинсталляции, где нужно будет подтвердить действие. После окончания процесса достаточно перезагрузить компьютер.
В случае, если программа более не нужна, то ее можно деинсталлировать. При этом вы не потеряете свой аккаунт и при необходимости сможете снова установить программу на свое устройство. Для того чтобы удалить приложение, вам достаточно выйти из Dropbox, после чего зайти в «Пуск», выбрать «Панель управления», перейти в «Программы и компоненты». В высветившемся списке программ найти Dropbox и нажать «Удалить приложение». После этого высветится окно деинсталляции, где нужно будет подтвердить действие. После окончания процесса достаточно перезагрузить компьютер.
Отзывы о программе
В Интернете можно найти множество откликов об использовании приложения. Среди наиболее распространенных выделяются следующие:
Удобная прога для синхронизации файлов, легко передавать данные с ноута на телефон, открыть доступ нескольким людям. Из минусов — довольно медленно работает на Андроиде.
Пользуюсь Дропбоксом больше двух лет. Очень эффективный инструмент для бизнеса. Помогает быстро вносить изменения в документы, планировать деловые встречи, постоянно быть в контакте с сотрудниками.
Удобный сервис, благодаря которому легко синхронизировать данные на телефоне и компьютере.
Dropbox: взгляд изнутри
В этой статье я расскажу о внутреннем устройстве популярного сервиса облачного хранения Dropbox. В частности, будет затронуто устройство протокола Dropbox, а также показана статистика его использования в некоторых странах Европы. Кроме этого, я сравню его с другими сервисами, такими как iCloud, Google Drive и SkyDrive.
Статья сугубо техническая. Не будет никаких сводных таблиц со стоимостью за Гб и анализом того, сколько еще можно получить за приглашенных «друзей».
Текст основан на научной статье “Dropbox изнутри: Изучаем сервисы облачного хранения” (Inside Dropbox: Understanding Personal Cloud Storage Services). PDF
В последние несколько лет произошел огромный скачок популярности сервисов облачного хранения данных. В гонке вооружений участвуют все крупные игроки и несколько молодых стартапов. В основном, вся информация о внутреннем устройстве сервисов и реальных цифрах их использования — это тайна за семью печатями. Нас кормят только данными, прошедшими через отдел маркетинга, что, безусловно, несколько отличается от реальности. Поэтому давайте копнем поглубже вместе с ребятами Idilio Drago, Anna Sperotto, Marco Mellia, Ramin Sadre, Maurizio M. Munafò и Aiko Pras — авторами исследования.
Вступление
Dropbox клиент разработан в основном на языке Python с использованием сторонних библиотек, таких как librsync. Клиент поддерживает все основные ОС: Windows, Mac, Linux. Использование Python однозначно говорит о том, что клиент разрабатывался с учетом облегченного портирования на различные платформы.
Основной элемент системы — это блок (chunk) размером до 4 Mb. В случае, если файл большего размера, он разбивается на несколько блоков, и каждый блок воспринимается системой независимо от других. Для каждого блока вычисляется SHA256 хеш, и эта информация является частью метаинформации о файле. Dropbox уменьшает объем передаваемых данных за счет передачи только разницы между измененными блоками файла. Кроме того, локально он содержит всю метаинформацию по файлам, которую синхронизирует с сервером и передает только изменения с прошлой версии (incremental updates).
Dropbox использует два типа серверов: управляющий (control) и сервер данных (data storage). Сервера управления находятся под контролем Dropbox, сервера данных — это сервера Амазона (Amazon S3, EC2). Для коммуникациями с серверами во всех случаях используется HTTPS.
Доменные имена, используемые Dropbox, всегда заканчиваются на dropbox.com. В таблице ниже приведены поддомены для управляющих серверов и серверов данных.
| Поддомен | Хостинг | Описание |
|---|---|---|
| client-lb/clientX | Dropbox | Meta data |
| notifyX | Dropbox | Notifications |
| api | Dropbox | API control |
| www | Dropbox | Web servers |
| d | Dropbox | Event logs |
| dl | Amazon | Direct links |
| dl-clientX | Amazon | Client storage |
| dl-debugX | Amazon | Back traces |
| dl-web | Amazon | Web storage |
| api-content | Amazon | API storage |
Dropbox: изнутри
Поскольку Dropbox использует HTTPS для шифрования всего трафика между серверами, простой перехват не даст никакой полезной информации. Для исследования мы устанавливали Squid и направляли весь трафик с компьютера под Linux на этот прокси. Также на прокси поставили SSL-bump, чтобы можно было расшифровывать SSL. Последним шагом устанавливаем самоподписанный сертификат на Squid и изменяем сертификат внутри запущенного Dropbox приложения. Данная конфигурация позволяет расшифровать и просмотреть трафик Dropbox.

Иллюстрация показывает протокол, используемый Dropbox для загрузки локально измененных блоков на свои сервера. После регистрации клиента на управляющих серверах clientX.dropbox.com, команда list получает изменения в метаданных, которые показывают разницу между локальной копией и тем, что находится на сервере. Как только происходит локальное изменение файлов, Dropbox вызывает команду commit_batch (client-lb.dropbox.com) и посылает измененные метаданные на сервер. После этого сервер отвечает, какие блоки ему необходимы, используя команду need_blocks, и клиент отсылает эти блоки на Amazon (dl-clientX.dropbox.com). Сохранение каждого блока подтверждается командой ОК.
После этого локальный клиент еще раз раз посылает команду commit_batch на сервер и получает подтверждение, что все блоки получены. Транзакции сохранения данных могут выполняться параллельно.
Протокол управления
Dropbox использует следующие группы управляющих серверов:
Набор данных и популярность клиентов
Мы избрали пассивный способ наблюдения за Dropbox. Для сбора трафика использовался open source инструмент Tstat. Tstat позволяет собирать разнообразную информацию о ТСР, предоставляя сведения более, чем о сотне разнообразных параметров соединения. Для анализа Dropbox мы предприняли несколько дополнительных шагов.
Поскольку Dropbox использует HTTPS, мы установили, что имя во всех сертификатах, используемых Dropbox — *.dropbox.com. Это было важно для правильной классификации трафика.
Мы пополнили открытую информацию записями с серверов DNS, к которым обращались клиенты. Таким образом мы связали IP адреса и имена серверов.
Tstat возвращал незашифрованную информацию об устройстве и именах директорий, которыми обменивался клиент и сервер уведомлений.
Данные были получены с помощью установки Tstat в 4 точках в Европе. Записи с точек, обозначенных как Home 1 и Home 2, составляют данные пользователей известного интернет-провайдера (ISP), предоставляющего интернет по ADSL и оптическому кабелю. Данные, обозначенные как Campus 1 и Campus 2, были собраны в университетах. Исследования проводились с 24 Марта 2012 по 5 Мая 2012.
| Имя | Тип | Количество IP адресов | Обьем данных (GB) |
|---|---|---|---|
| Campus 1 | Wired | 400 | 5,320 |
| Campus 2 | Wired/Wireless | 2,528 | 55,054 |
| Home 1 | FTTH/ADSL | 18,785 | 509,909 |
| Home 2 | ADSL | 13,723 | 301,448 |
Ниже приведен график, который показывает, сколько различных IP адресов связывалось с облачным сервисом хранения хотя бы раз в день.
Второй график показывает, сколько данных было передано на это облачное хранилище в день.
Таблица показывает суммарный трафик Dropbox, который мы отследили в ходе наших измерений.
| Campus 1 | Campus 2 | Home 1 | Home 2 | Всего | |
|---|---|---|---|---|---|
| Запросов | 167,189 | 1,902,824 | 1,438,369 | 693,086 | 4,204,666 |
| Обьем (GB) | 146 | 1,814 | 1,153 | 506 | 3,624 |
| Устройств | 283 | 6,609 | 3,350 | 1,313 | 11,561 |
Анализ трафика
Графики показывают куммулятивную функцию распределения для различного количества блоков.
Оказалось, что более, чем в 80% процентах случаев, количество блоков при сохранении данных не превышает 10. График для данных с точки Home 2 существенно отличается от остальных, так как здесь мы наблюдали одного клиента, который постоянно, на протяжении нескольких дней, пересылал одни и те же блоки. Анализ полученных данных показывает, что основной сценарий использования Dropbox — это постоянная работа с небольшими, постоянно изменяемыми файлами.
Как мы рассмотрели выше, Dropbox использует центральные сервера для хранения данных. Это сразу наводит на вопрос о скорости работы сервиса для пользователей, которые находятся географически далеко от серверов.
Максимальная скорость, которую мы наблюдали, была близка к 10 Mbit/s и наблюдалась на файлах с размером больше 1 Mb. Средняя скорость для Campus 2 была: запись — 462 kbits/s и чтение — 797 kbits/s. Для Campus 1: запись — 359 kbits/s и чтение — 783 kbits/s.
Также из графиков видно, что скорость существенно зависит от количества блоков: чем больше блоков, тем ниже скорость.
Изменения в Dropbox 1.4.0
Начиная с версии 1.4.0, Dropbox добавил две новые команды: store_batch и retrieve_batch, что позволяет работать с несколькими блоками одновременно. Это улучшение должно существенно улучшить пропускную способность сервиса.
Количество устройств
График показывает количество установок Dropbox у пользователей дома. Примерно в 60% случаев у пользователей существует только 1 устройство с Dropbox. У 25% пользователей дома есть 2 устройства, использующих Dropbox.
Среднее время использования
График показывает среднее время использования Dropbox. Анализируя время использования, мы смотрели, сколько времени клиент поддерживал связь с сервером уведомлений. Поскольку клиент всегда держит это соединение открытым либо открывает его заново, это хороший способ оценить время использования.
Из графика видно, что время использования Dropbox в большинстве случаев меньше 4 часов. Исключение составляет Campus 1, где много рабочих компьютеров и компьютеров, работающих постоянно.
Исходные данные
Вы можете загрузить исходные данные, которые использовались в этой статье для дальнейшего анализа. (Исходные данные).
Хочу обратить внимание, что оригинальная статья содержит больше информации. В ней могут быть ответы на вопросы, которые могут возникнуть у вас после прочтения.
Развитие баз данных в Dropbox. Путь от одной глобальной базы MySQL к тысячам серверов
Когда только Dropbox запустился, один пользователь на Hacker News прокомментировал, что реализовать его можно несколькими bash-скриптами с помощью FTP и Git. Сейчас такого сказать никак нельзя, это крупное облачное файловое хранилище с миллиардами новых файлов каждый день, которые не просто как-то хранятся в базе данных, а так, что любую базу можно восстановить на любую точку в течение последних шесть дней.
Под катом расшифровка доклада Славы Бахмутова (m0sth8) на Highload++ 2017, о том, как развивались базы данных в Dropbox и как они устроены сейчас.
О спикере: Слава Бахмутов — site reliability engineer в команде Dropbox, очень любит Go и иногда появляется в подкасте golangshow.com.
Содержание
Архитектура Dropbox простым языком
Dropbox появился в 2008 году. По сути, это облачное файловое хранилище. Когда только Dropbox запустился, пользователь на Hacker News прокомментировал, что реализовать его можно несколькими баш-скриптами с помощью FTP и Git. Но, тем не менее, Dropbox развивается, и сейчас это достаточно крупный сервис c более чем 1,5 миллиардами пользователей, 200 тысячами бизнесов и огромным количеством (несколько миллиардов!) новых файлов каждый день.
Как выглядит Dropbox? 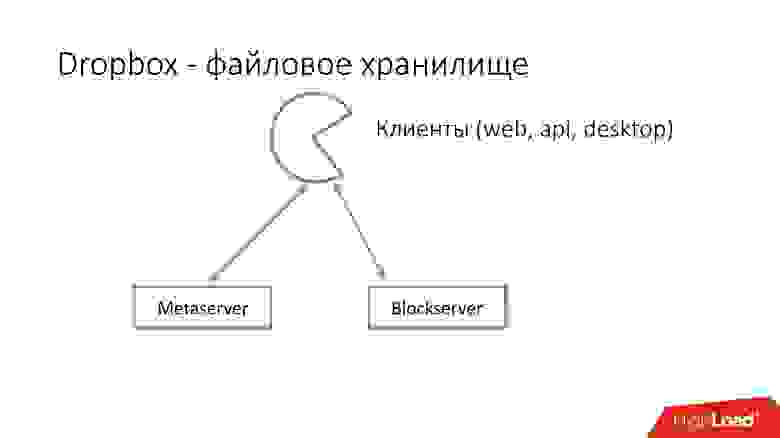
У нас есть несколько клиентов (web интерфейс, API для приложений, которые пользуются Dropbox, desktop-приложения). Все эти клиенты используют API и общаются с двумя большими сервисами, которые логически можно разделить на:
Как это работает?
Например, у вас есть файл video.avi с каким-то видео. 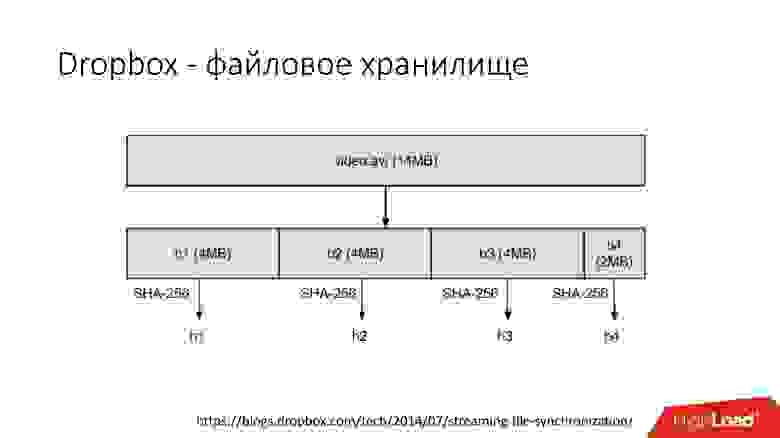 Ссылка со слайда
Ссылка со слайда
Конечно, это очень упрощенная схема, протокол намного сложней: там есть синхронизация между клиентами внутри одной сети, есть драйверы ядра, возможность разрешать коллизии и т.д. Это достаточно сложный протокол, но схематически он работает примерно так. 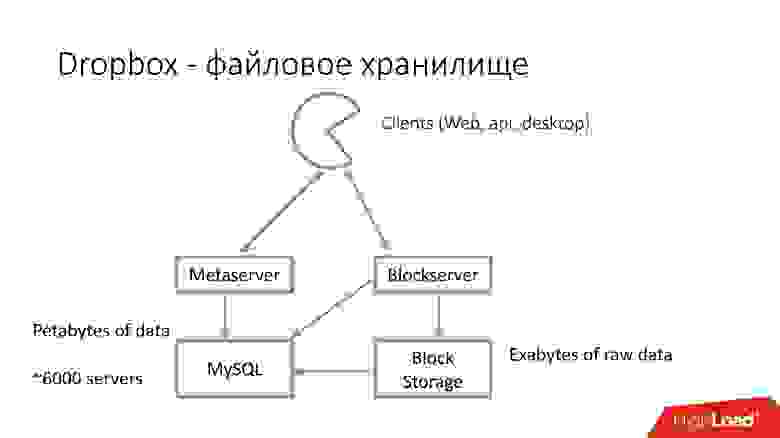
Когда клиент сохраняет что-то на Metaserver, вся информация попадает в MySQL. Blockserver информацию о файлах, о том, как они структурированы, из каких блоков состоят, тоже хранит в MySQL. Также Blockserver хранит сами блоки в Block Storage, который в свою очередь информацию о том, где лежит какой блок, на каком сервере и как он обработан в данный момент, тоже сохраняет в MYSQL.
Для хранения экзабайтов пользовательских файлов мы параллельно сохраняем дополнительную информацию в базу данных на несколько десятков петабайт, раскиданных по 6 тысячам серверов.
История развития баз данных
Как развивались базы данных в Dropbox? 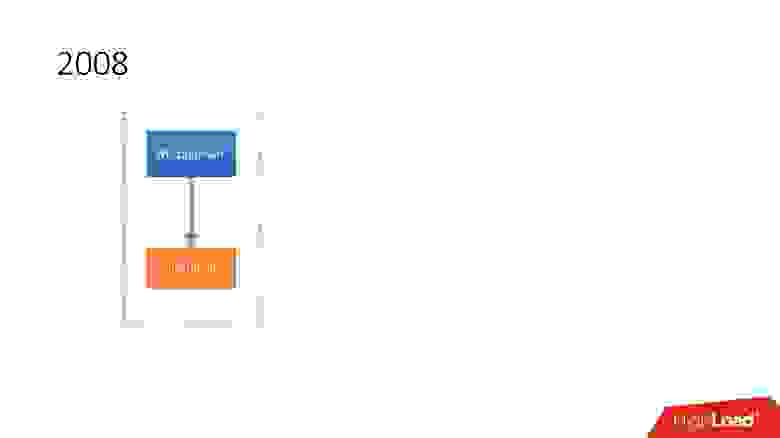
В 2008 году все начиналось с одного Metaserver и одной глобальной базы данных. Всю информацию, которую Dropbox нужно было куда-то сохранять, он сохранял в единственный глобальный MySQL. Так продолжалось недолго, потому что количество пользователей росло, и отдельные базы и таблички внутри баз разбухали быстрее, чем другие. 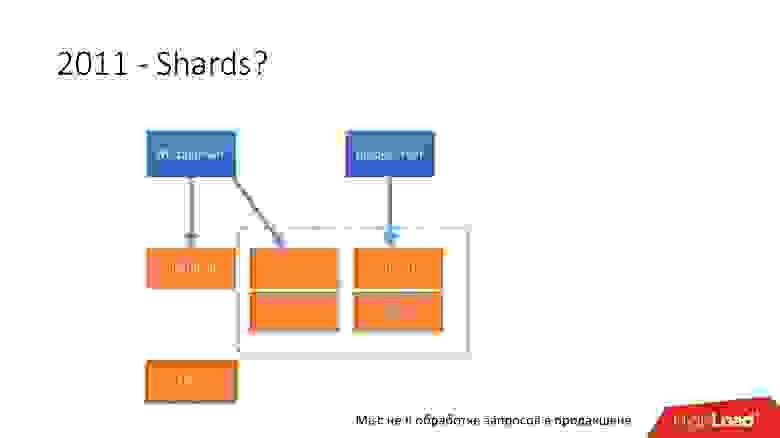
Поэтому в 2011 году несколько таблиц были вынесены на отдельные сервера:
Но после 2012 года Dropbox начал очень сильно расти, с тех пор мы растем примерно на 100 млн пользователей в год. 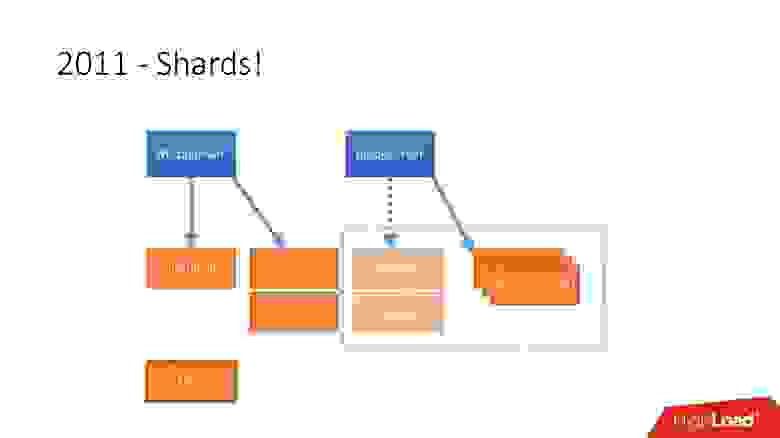
Нужно было учитывать такой огромный рост, и поэтому в конце 2011 года у нас появились шарды — база, состоящая из 1 600 шардов. Изначально всего 8 серверов по 200 шардов на каждом. Сейчас это 400 мастер-серверов по 4 шарда на каждом. 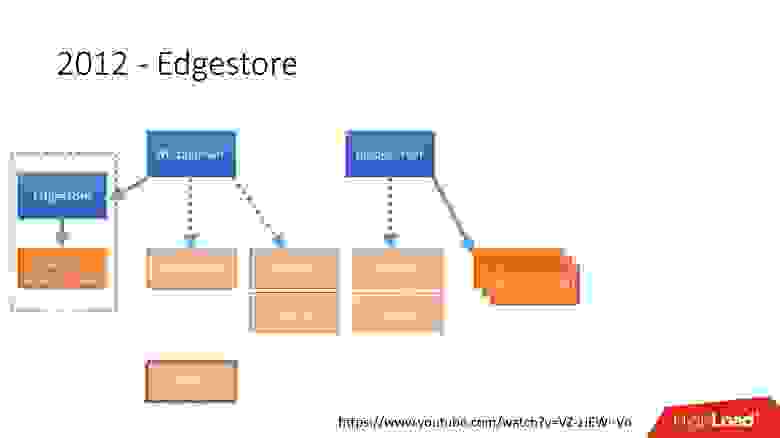 Ссылка со слайда
Ссылка со слайда
В 2012 году мы поняли, что создавать таблицы и обновлять их в БД на каждую добавляемую бизнес-логику очень сложно, муторно и проблематично. Поэтому в 2012 году мы изобрели свой собственный графовый storage, который назвали Edgestore, и с тех пор вся бизнес-логика и метаинформация, которую генерирует приложение сохраняется в Edgestore.
Edgestore, по сути, абстрагирует MySQL от клиентов. У клиентов есть некие сущности, которые соединены между собой ссылками из gRPC API к Edgestore Сore, который преобразует эти данные в MySQL и каким-то образом там хранит их (в основном он отдает все это из кэша). 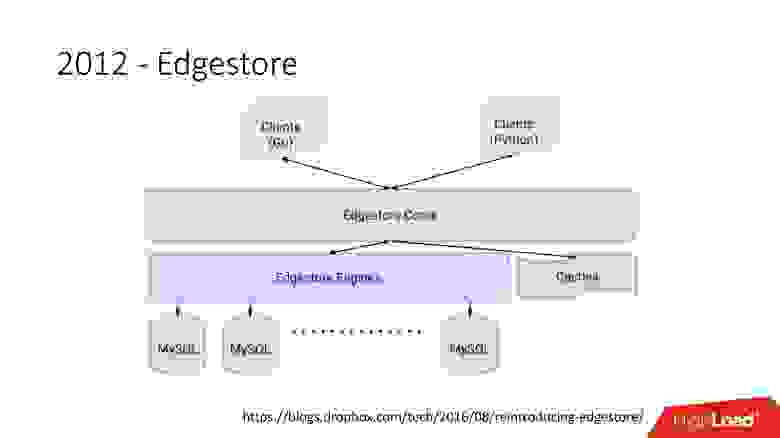 Ссылка со слайда
Ссылка со слайда
В 2015 году мы ушли с Amazon S3, разработали собственное облачное хранилище под названием Magic Pocket. В нем информация о том, где какой блок-файл находится, на каком сервере, о перемещениях этих блоков между серверами, хранится в MySQL. 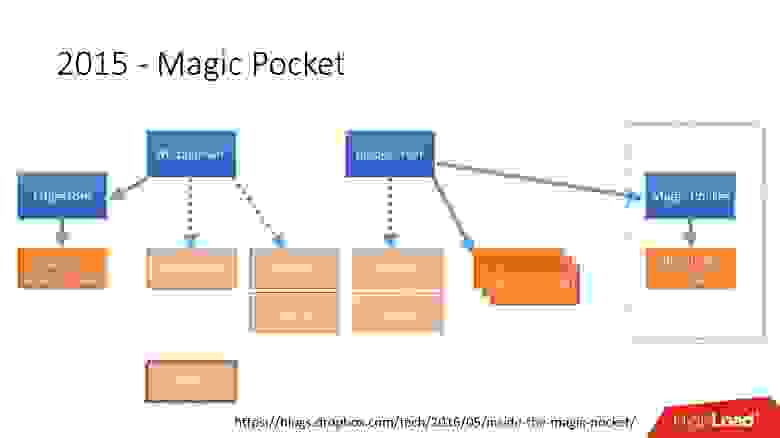 Ссылка со слайда
Ссылка со слайда
Но MySQL используется очень хитрым образом — по сути, как большая распределеннуя хэш-таблица. Это очень разная нагрузка, в основном, на чтение случайных записей. 90% утилизации это I/O.
Архитектура баз данных
Во-первых, мы сразу же определили некие принципы, по которым строим архитектуру нашей базы данных:
Базовая топология
База данных устроена примерно следующим образом:
Такая топология выбрана потому, что если у нас вдруг умирает первый дата-центр, то во втором дата-центре у нас уже практически полная топология. Мы просто меняем в Discovery все адреса, и клиенты могут работать.
Специализированные топологии
Также у нас есть специализированные топологии.
Топология Magic Pocket состоит из одного master-сервера и двух slave-серверов. Так сделано, потому что сам Magic Pocket дублирует данные среди зон. Если он теряет одни кластер, то может восстановить через erasure code все данные с других зон. 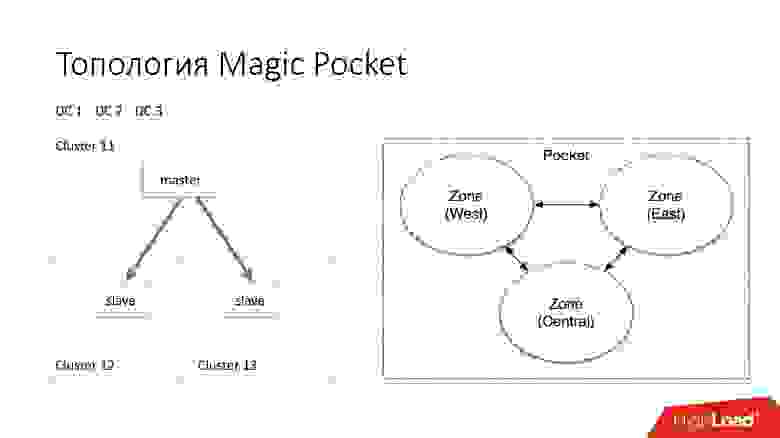
Топология active-active — кастомная топология, которая используется в Edgestore. В ней есть по одному master и двум slave в каждом из двух дата-центров, и они являются slave друг для друга. Это очень опасная схема, но Edgestore на своем уровне точно знает, какие данные на какой master по какому range он может записать. Поэтому эта топология не ломается. 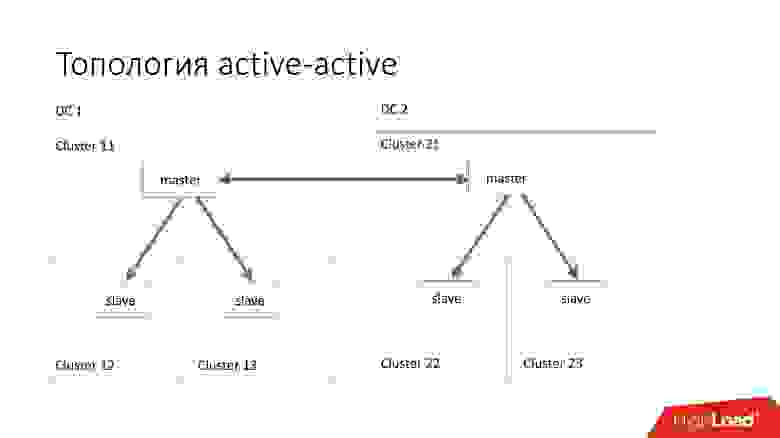
Instance
У нас установлены достаточно простые сервера с конфигурацией 4-5 летней давности:
Single Instance
На этом сервере у нас есть один большой инстанс MySQL, на котором находятся несколько шардов. Этот MySQL инстанс сразу выделяет себе практически всю память. На сервере запущены и другие процессы: proxy, сбор статистики, логи и т.д.
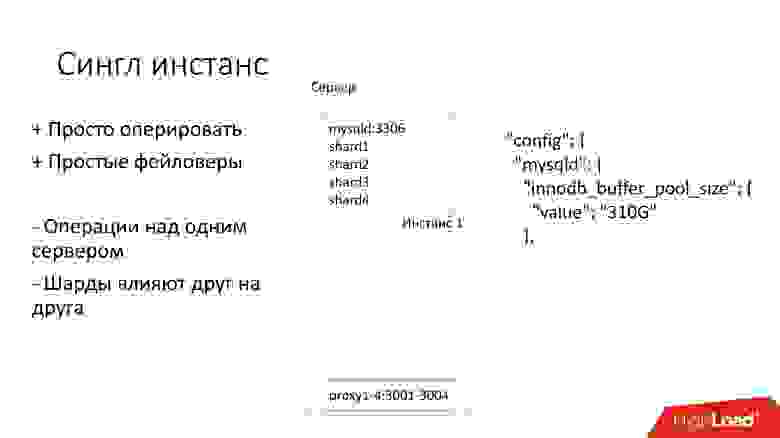
Это решение хорошо тем, что:
+ Им легко управлять. Если нужно заменить MySQL инстанс, просто заменяем сервер.
+ Просто делать фейловеры.
− Проблематично то, что любые операции происходят над целым инстансом MySQL и сразу над всеми шардами. Например, если нужно сделать бэкап, мы делаем бэкап сразу всех шардов. Если нужно сделать фейловер, мы делаем фейловер сразу всех четырех шардов. Соответственно, доступность страдает в 4 раза больше.
− Проблемы с репликацией одного шарда влияют на другие шарды. Репликация в MySQL не параллельная, и все шарды работают в один поток. Если с одним шардом что-то происходит, то остальные тоже становятся жертвами.
Поэтому сейчас мы переходим на другую топологию.
Multi Instance

В новом варианте на сервере запущено сразу несколько инстансов MySQL, в каждом есть по одному шарду. Чем это лучше?
+ Мы можем проводить операции только над одним конкретным шардом. То есть если нужен фейловер, переключаем только один шард, если нужен бэкап, делаем бэкап только одного шарда. Это значит, что операции очень сильно ускоряются — в 4 раза для четырех-шардового сервера.
+ Шарды почти не влияют друг на друга.
+ Улучшение в репликации. Мы можем миксовать разные категории и классы баз данных. Edgestore занимает очень много места, например, все 4 Тб, а Magic Pocket занимает всего 1 Тб, но у него утилизация 90%. То есть мы можем объединять различные категории, которые по-разному используют I/O и ресурсы машины, и запустить 4 потока репликаций.
Конечно, у этого решения есть и минусы:
− Самый большой минус — намного сложнее всем этим управлять. Нужен какой-то умный планировщик, который будет понимать, куда он может вынести этот инстанс, где будет оптимальная нагрузка.
− Сложнее фейловеры.
Поэтому мы только сейчас переходим на это решение.
Discovery
Клиенты должны как-то знать, как подключаться к нужной базе, поэтому у нас есть Discovery, который должен:
Как развивался Discovery
Сначала все было просто: адрес базы данных в исходном коде в конфиге. Когда нам нужно было обновить адрес, то просто все деплоилось очень быстро. 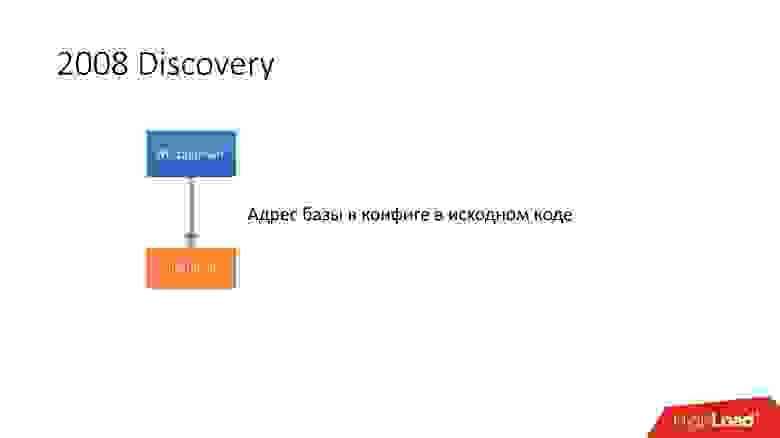
К сожалению, это не работает, если серверов становится очень много. 
Выше самый первый Discovery, который у нас появился. Были скрипты базы данных, которые изменяли табличку в ConfigDB — это была отдельная табличка MySQL, а клиенты уже слушали эту БД и периодически забирали оттуда данные. 
Таблица очень простая, есть категория базы данных, ключ шарда, класс БД master/slave, proxy и адрес БД. По сути, клиент запрашивал категорию, класс БД, ключ шарда, и ему возвращался MySQL-ный адрес, по которому он уже мог устанавливать соединение. 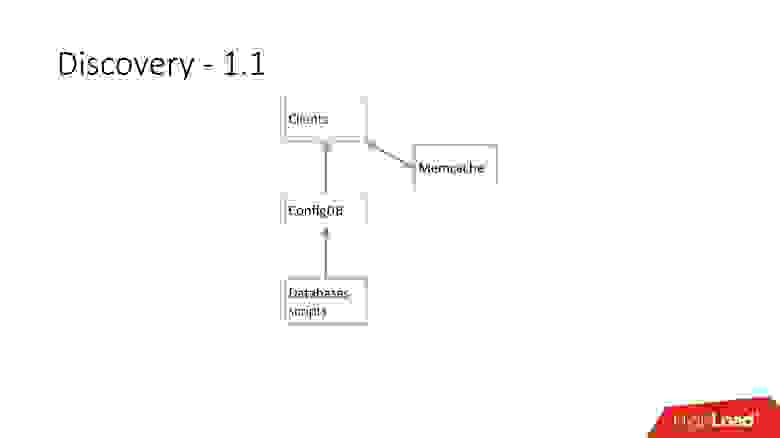
Как только серверов стало очень много, добавился Memcaсhе и клиенты стали общаться уже с ним.
Но потом мы это переработали. MySQL скрипты начали общаться через gRPC, через тонкий клиент с сервисом, который мы назвали RegisterService. Когда какие-то изменения происходили, у RegisterService была очередь, и он понимал, как применять эти изменения. RegisterService сохранял данные в AFS. AFS — это наша внутренняя система, построенная на базе ZooKeeper. 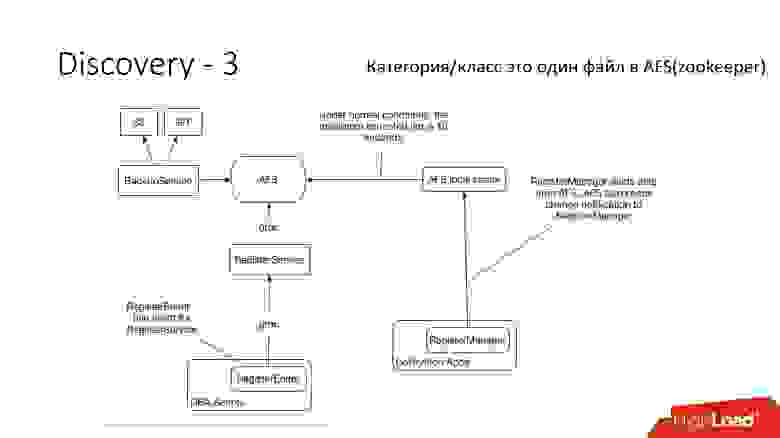
Второе решение, которое здесь не показано, напрямую использовало ZooKeeper, и это создавало проблемы, потому что у нас каждый шард был узлом в ZooKeeper. Например, 100 тысяч клиентов подключаются к ZooKeeper, если они вдруг умерли из-за какого-то бага все вместе, потом прийдет сразу 100 тысяч запросов к ZooKeeper, что просто его уронит, и он не сможет подняться.
Поэтому была разработана система AFS, которой пользуется весь Dropbox. По сути, она абстрагирует работу с ZooKeeper для всех клиентов. AFS демон локально крутится на каждом сервере и предоставляет очень простой файловый API вида: создать файл, удалить файл, запросить файл, получить нотификацию на изменение файла и compare and swap операции. То есть можно попробовать заменить файл с какой-то версии, а если эта версия поменялась в процессе смены, то операция отменяется.
По существу, такая абстракция над ZooKeeper, в которой есть локальный backoff и джиттер-алгоритмы. ZooKeeper уже не падает под нагрузкой. С AFS мы снимаем бэкапы в S3 и в GIT, потом сам локальный AFS уведомляет клиентов о том, что данные изменились. 
В AFS данные хранятся в виде файлов, то есть это API файловой системы. Например, выше приведен файл shard.slave_proxy — самый большой, он занимает порядка 28 Кб, и когда мы изменяем категорию shard и slave_proxy класс, то все клиенты, которые подписаны на этот файл, получают нотификацию. Они перечитывают этот файл, в котором есть вся нужная информация. По shard key получают категорию и перенастраивают пул соединения к базе данных.
Операции
Мы используем очень простые операции: promotion, clone, backups/recovery. 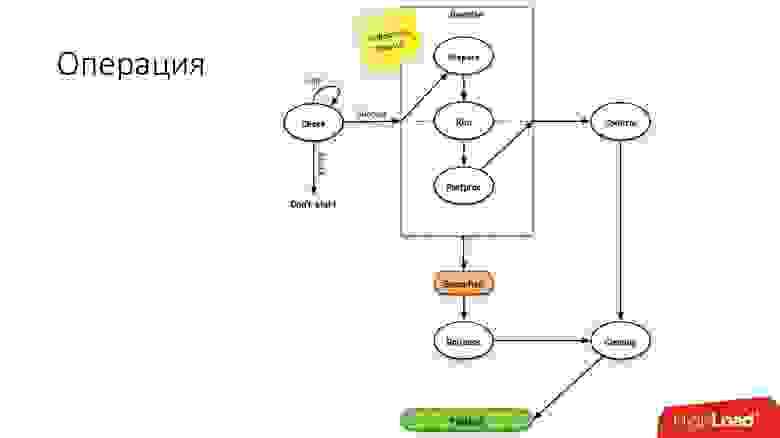
Операция — это простая стейт-машина. Когда мы заходим в операцию, мы производим какие-то проверки, например, spin-check, который несколько раз по таймауту проверяет, можно ли нам выполнить эту операцию. После этого мы делаем какое-то подготовительное действие, которое не влияет на внешние системы. Дальше собственно сама операция.
У всех шагов внутри операции есть rollback-step (отмена). Если с операцией возникла какая-то проблема, то операция пытается восстановить систему в исходное положение. Если все нормально, то происходит cleanup, и операция завершена.
Такая простая стейт-машина у нас на любой операции.
Promotion (смена мастера)
Это очень частая операция в БД. Были вопросы о том, как делать alter на горячем master-сервере, который работает — он же встанет колом. Просто все эти операции производятся на slave-серверах, и потом slave меняется с master местами. Поэтому операция promotion очень частая. 
Нужно обновить kernel — делаем swap, нужно обновить версию MySQL — обновляем на slave, переключаем на master, обновляем там. 
Мы добились очень быстрого promotion. Например, у нас для четырех шардов сейчас promotion порядка 10-15 с. На графике выше видно, что при promotion availability пострадало на 0,0003%.
Но нормальные promotion не так интересны, потому что это обычные операции, которые выполняются каждый день. Интересны фейловеры.
Фейловер (замена поломанного мастера)
Фейловер (failover) значит, что база данных умерла.
Ниже примерная схема того, как работает фейловер. 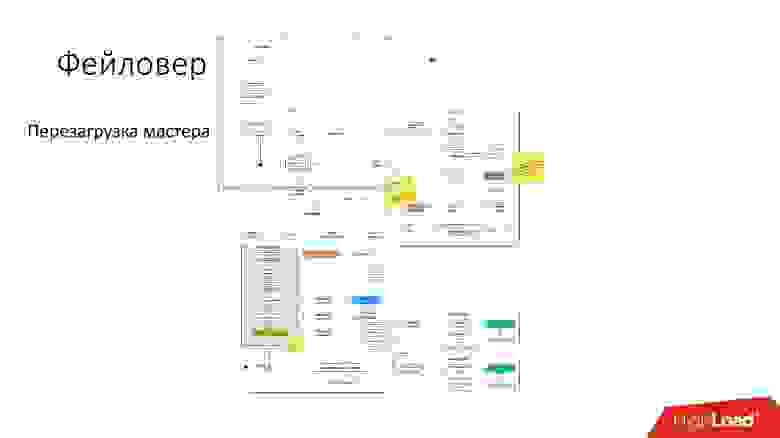
Синхронизация кластера. Зачем нам нужна синхронизация кластера? 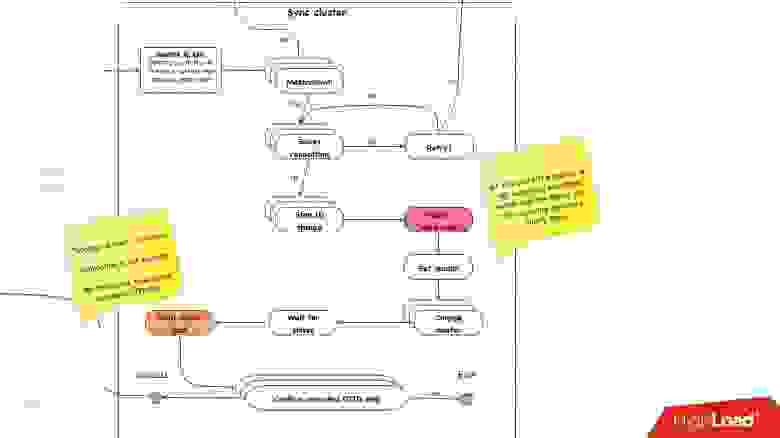
Если вспомнить предыдущую картинку с нашей топологией, у одного master-сервера есть три slave-сервера: два в одном дата-центре, один — в другом. При promotion нам нужно, чтобы master был в том же основном дата-центре. Но иногда, когда slave нагружены, при semisync бывает так, что semisync-slave’ом становится slave в другом дата-центре, потому что он-то не нагружен. Поэтому нам нужно сначала синхронизировать весь кластер, а потом уже сделать promotion на slave в нужном нам дата-центре. Это делается очень просто:
Бэкапы
Бэкапы — очень важная тема в базах данных. Я не знаю, делаете ли вы бэкапы, но мне кажется, все должны их делать, это уже избитая шутка.
Паттерны использования
● Добавить новый slave
Самый главный паттерн, который мы используем при добавлении нового slave-сервера, мы просто его восстанавливаем из бэкапа. Это происходит постоянно.
● Восстановление данных на точку в прошлом
Достаточно часто пользователи удаляют данные, а потом просят их восстановить, в том числе из базы данных. Эта достаточно частая операция восстановления данных на точку в прошлом у нас автоматизирована.
● Восстановить целиком весь кластер с нуля
Все думают, что бэкапы нужны для того, чтобы восстановить все данные с нуля. На самом деле эта операция практически никогда нам не требовалась. Последний раз мы использовали ее 3 года назад.
Мы смотрим на бэкапы, как на продукт, поэтому говорим клиентам, что у нас есть гарантии:
Это наши основные гарантии, которые мы даем нашим клиентам. Скорость в 1 Тб за 40 минут, потому что есть ограничения по сети, мы не одни на этих стойках, на них еще продакшен трафик.
Цикл
Мы ввели такую абстракцию, как цикл. В одном цикле мы стараемся забэкапить практически все наши базы данных. У нас одновременно крутится 4 разных цикла. 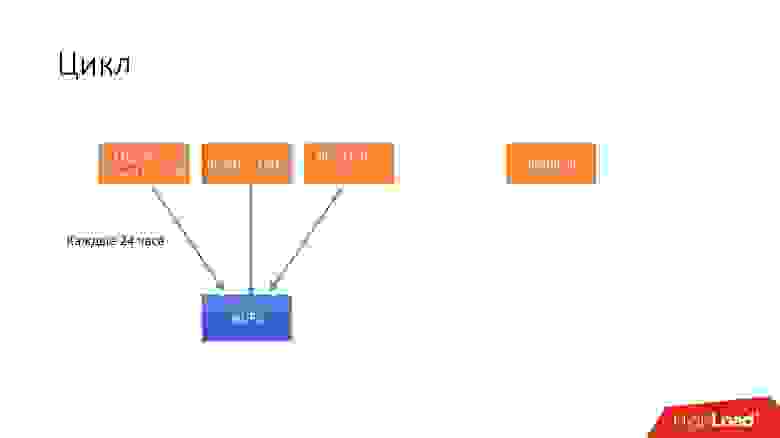
Все это хранится в течении нескольких циклов. Допустим, если мы храним 3 цикла, то в HDFS у нас есть последние 3 дня, и последние 6 дней в S3. Так мы поддерживаем наши гарантии.
Это пример, как они работают. 
В данном случае у нас запущено два длинных цикла, которые делают бэкапы шардированных баз данных, и один короткий. При завершении каждого цикла мы обязательно верифицируем, что бэкапы работают, то есть делаем recovery на какой-то процент базы данных. К сожалению, мы не можем восстановить все данные, но какой-то процент данных для цикла мы обязательно проверяем. В итоге у нас будет 100 процентов бекапов, которые мы восстановили.
У нас есть определенные шарды, которые мы всегда восстанавливаем, чтобы смотреть скорость восстановления, чтобы мониторить возможные регрессии, и есть шарды, которые мы восстанавливаем просто рандомно, чтобы проверить, что они восстановились и работают. Плюс при клонировании мы тоже восстанавливаемся из бэкапов.
Горячие бэкапы

Сейчас у нас происходит hot-бэкап, для которого мы используем инструмент Percona xtrabackup. Запускаем его в режиме —stream=xbstream, и он нам возвращает на рабочей базе данных, поток бинарных данных. Дальше у нас есть script-splitter, который этот бинарный поток делит на четыре части, и потом мы сжимаем этот поток.
MySQL хранит данные на диске очень странным образом и у нас получилась компрессия больше 2x. Если база данных занимает 3 Тб, то, в результате сжатия, бэкап занимает примерно 1 500 Гб. Дальше мы шифруем эти данные, чтобы никто не мог их прочитать, и отправляем в HDFS и в S3.
В обратную сторону работает абсолютно точно так же. 
Подготавливаем сервер, куда будем устанавливать бэкап, достаем бэкап из HDFS или из S3, декодируем и декомпрессируем его, splitter сжимает это все и отправляет в xtrabackup, который восстанавливает все данные на сервер. Потом происходит crash-recovery.
Некоторое время самой главной проблемой hot бэкапов было то, что crash-recovery занимает достаточно длительное время. В целом нужно проиграть все транзакции за то время, пока вы делаете бэкап. После этого мы проигрываем binlog, чтобы наш сервер догнал текущий master.
Как мы сохраняем binlogs?
Раньше мы сохраняли файлики binlog’ов. Мы собирали на master файлики, чередовали их каждые 4 минуты, либо по 100 Мб, и сохраняли в HDFS.
Сейчас у нас используется новая схема: есть некий Binlog Backuper, который подключен к репликациям и ко всем базам данных. Он, по сути, постоянно сливает binlog к себе и сохраняет их на HDFS. 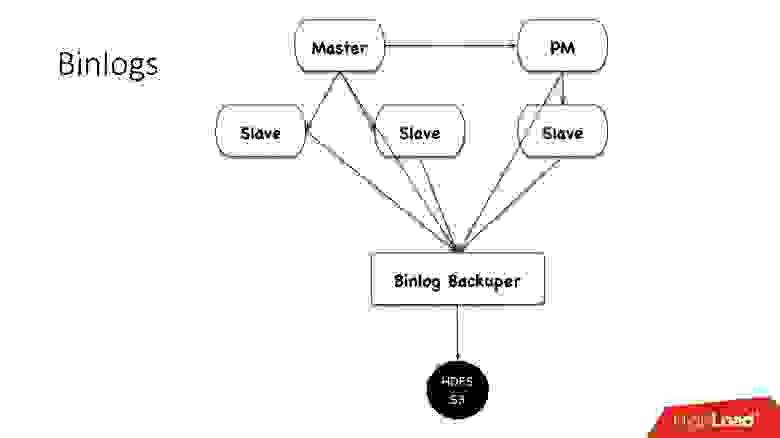
Соответственно, в предыдущей реализации мы могли потерять 4 минуты бинарных логов, если потеряли все 5 серверов, в этой же реализации, в зависимости от нагрузки, мы теряем буквально секунды. Все сохраненное в HDFS и в S3 хранится в течение месяца.
Холодные бэкапы
Мы подумываем перейти на холодные бэкапы.
Предпосылки для этого:
В нашей топологии есть slave в другом дата-центре, который практически ничего не делает. Мы периодически его останавливаем, делаем холодный бэкап и запускаем обратно. Все очень просто.
Планы ++
Это планы на дальнее будущее. Когда мы будем делать обновление нашего Hardware парка, мы хотим добавить на каждый сервер дополнительный шпиндельный диск (HDD) порядка 10 Тб, и делать на него горячие бэкапы + crash recovery xtrabackup, а после этого загружать уже бэкапы. Соответственно, у нас будут бэкапы на всех пяти серверах одновременно, в разные точки времени. Это, конечно, усложнит всю обработку и оперирование, но снизит стоимость, потому что HDD стоит копейки, а огромный кластер HDFS стоит дорого.
Как я уже говорил, клонирование — это простая операция:
Автоматизация
Конечно же, на 6 000 серверах никто ничего не делает вручную. Поэтому у нас есть различные скрипты и сервисы автоматизации, их очень много, но основные из них — это:
Auto-replace
Этот скрипт нужен, когда сервер умер, и нужно понять, правда ли он умер, и что за проблема — может, сеть поломалась или еще что-то. Это нужно решить, как можно быстрее.
Availability (доступность) — это функция от времени между возникновением ошибок и временем, за которое вы можете детектировать и починить эту ошибку. Починить мы можем очень быстро — у нас recovery очень быстрый, поэтому нам нужно как можно скорее определить существование проблемы. 
На каждом сервере MySQL запущен сервис, которые пишет heartbeat. Heartbeat — это текущий timestamp. 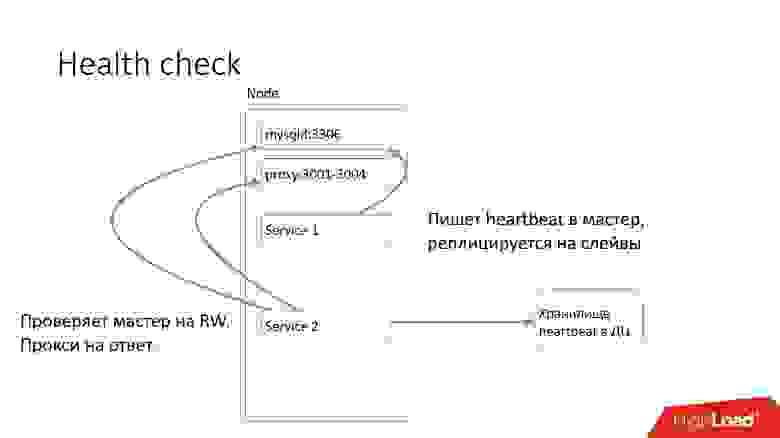
Есть также другой сервис, который пишет значение некоторых предикатов, например, что master в режиме read-write. После этого второй сервис отправляет в центральное хранилище этот heartbeat.
У нас есть auto-replace скрипт, работающий по такой схеме.  Схема в лучшем качестве и отдельно ее увеличенные фрагменты есть в презентации доклада, начиная с 91 слайда.
Схема в лучшем качестве и отдельно ее увеличенные фрагменты есть в презентации доклада, начиная с 91 слайда.
Что здесь происходит?
Соответственно, для slave-сервера мы запускаем клонирование и просто удаляем его из топологии, а если это master, то запускаем фейловер, так называемый emergency promotion.
DBManager
DBManager — это сервис для управления нашими базами данных. В нем есть:
DBManager достаточно прост архитектурно.
Есть достаточно простой CLI интерфейс, где можно запускать задачи и также просматривать их в удобных представлениях. 
Remediations
Еще у нас есть система реагирования на проблемы. Когда у нас что-то поломалось, например, диск вышел из строя, либо какой-то сервис не работает, срабатывает Naoru. Это система, которая работает во всем Dropbox, все ею пользуются, и она построена именно для таких небольших задач. Про Naoru я рассказывал в своем докладе в 2016 году.
Система Wheelhouse основана на базе стейт-машины и предназначена для долгих процессов. Например, нам нужно обновить ядро на всех MySQL на всем нашем кластере из 6000 машин. Wheelhouse четко это делает — обновляет на slave-сервере, запускает promotion, slave становится master, обновляет на master-сервере. Эта операция может занять месяц или даже два.
Мониторинг

Если вы не мониторите систему, то скорее всего она не работает.
Мы мониторим все в MySQL — вся информация, которую мы можем получить из MySQL, у нас где-то сохраняется, мы можем получить к ней доступ по времени. Мы сохраняем информацию по InnoDb, статистику по запросам, по транзакциям, по длине транзакций, перцентили на длины транзакции, по репликации, по сети — все-все-все — огромное количество метрик.
Alert
У нас настроено 992 алерта. Вообще-то на метрики никто не смотрит, мне кажется, что нет людей, которые приходят на работу и начинают смотреть на график метрик, есть более интересные задачи. 
Поэтому есть алерты, которые срабатывают при достижении определенных пороговых значений. У нас 992 алерта, что бы ни случилось, мы об этом узнаем.
Инциденты

У нас есть PagerDuty — это сервис, через который распространяются алерты на ответственных лиц, которые начинают принимать меры. 
В данном случае произошла ошибка в emergency promotion и сразу после этого зарегистрировался алерт о том, что упал master. После этого дежурный проверил, что помешало emergency promotion, и сделал необходимые ручные операции.
Мы обязательно разбираем каждый произошедший инцидент, для каждого инцидента у нас есть задача в task tracker. Даже если этот инцидент — проблема в наших алертах, мы тоже создаем задачу, потому что, если проблема в логике алерта и порогах срабатывания, то их надо поменять. Алерты не должны просто так портить людям жизнь. Алерт — это всегда больно, особенно в 4 часа ночи.
Тестирование
Как и с мониторингом, я уверен, что тестированием занимаются все. Помимо юнит-тестов, которыми мы покрываем наш код, у нас есть интеграционные тесты, в которых мы тестируем:
Пример топологии 
У нас есть топологии на все случаи жизни: 2 дата-центра с multi instance, с шардами, без шардов, с кластерами, один дата-центр — вообще практически любая топология — даже те, которые мы не используем, просто, чтобы посмотреть. 
В этом файле у нас просто есть настройки, какие сервера и с чем нам нужно поднимать. Например, нам нужно поднять master, и мы говорим, что сделать это нужно с такими-то данными инстансов, с такими-то базами данных на таких-то портах. У нас практически все собирается с помощью Bazel, который на базе этих файлов создает топологию, запускает MySQL сервера, после этого запускается тест. 
Тест выглядит очень просто: мы указываем, какая используется топология. В данном тесте Уы тестируем auto_replace.
Stages
Stage-окружение — это такие же базы данных, как и в продакшене, но на них нет пользовательского трафика, а есть некий синтетический трафик, который похож на продакшен, через Percona Playback, sysbench и похожие системы.
В Percona Playback мы записываем трафик, потом проигрываем его на stage-окружении с различной интенсивностью, можем в 2-3 раза быстрее проиграть. То есть это искусственная, но очень близкая к реальной нагрузка.
Это нужно, потому что в интеграционных тестах мы не можем протестировать наш продакшен. Мы не можем протестировать алерт или то, что метрики работают. На стейджинге мы тестируем алерты, метрики, операции, периодически убиваем сервера и смотрим, что они нормально собираются.
Плюс мы тестируем все автоматизации вместе, потому что в интеграционных тестах, скорее всего, тестируется одна часть системы, а в стейджинге все автоматизированные системы работают одновременно. Иногда вы думаете, что система поведет себя так, а не иначе, но она может повести себя вообще по-другому.
DRT (Disaster recovery testing)
Также мы проводим тесты в продакшене — прямо на реальных базах. Это называется Disaster recovery testing. Почему нам это нужно?
● Мы хотим протестировать наши гарантии.
Это делают многие крупные компании. Например, в Google есть один сервис, который работал настолько стабильно — 100% времени, — что все сервисы, которые его использовали, решили, что этот сервис реально 100% стабилен и никогда не падает. Поэтому Google пришлось этот сервис ронять специально, чтобы пользователи учитывали и такую возможность.
Так и мы — у нас есть гарантия, что MySQL работает — а иногда не работает! И у нас есть гарантия, что он может не работать какой-то промежуток времени, клиенты должны это учитывать. Периодически мы убиваем production master, либо, если мы хотим сделать фейловер, убиваем все slave-серверы, чтобы посмотреть, как поведет себя semisync репликация.
Почему это хорошо? У нас был случай, когда при promotion 4 шардов из 1600, availability падала до 20%. Кажется, что что-то не так, для 4 шардов из 1600 должны быть какие-то другие цифры. Фейловеры для этой системы происходили достаточно редко, примерно раз в месяц, и все решили: «Ну, это фейловер, бывает».
В какой-то момент, когда мы переходили на новую систему, один человек решил оптимизировать те два сервиса записи heartbeat и объединил их в одни. Этот сервис делал еще что-то и, в конечном итоге, умирал и переставали записываться heartbeat’ы. Так получилось, что для этого клиента у нас стало 8 фейловеров в день. Все лежало — 20% availability.
Оказалось, что в этом клиенте keep-alive 6 часов. Соответственно, как только master умирал, у нас все соединения держались еще 6 часов. Пул не мог дальше работать — у него коннекты держатся, он ограничен и не работает. Это починили.
Делаем фейловер опять — уже не 20%, но все равно много. Что-то все-равно не так. Оказалось, что баг в реализации пула. Пул при запросе обращался ко многим шардам, а потом соединял все это. Если какие-то шарды фейловерились, происходил какой-то race condition в Go коде, и весь пул забивался. Все эти шарды не могли больше работать.
Disaster recovery тестирование очень полезно, потому что клиенты должны быть готовы к этим ошибкам, они должны проверять свой код.
● Плюс Disaster recovery testing хорош тем, что проходит в бизнес часы и все на месте, меньше стресса, люди знают, что сейчас произойдет. Это происходит не ночью, и это здорово.
Заключение
1. Всё нужно автоматизировать, никогда не лезть руками.
Каждый раз, когда у нас кто-то лезет в систему руками, у нас все умирает и ломается — каждый божий раз! — даже на простых операциях. Например, умер один slave, человек должен был добавить второй, но решил удалить умерший slave руками из топологии. Однако вместо умершего он скопировал в команду живой — master остался вообще без slave. Такие операции не должны делаться вручную.
2. Тесты должны быть постоянные и автоматизированные (и в продакшене).
Ваша система меняется, ваша инфраструктура меняется. Если вы один раз проверили, и она вроде работала, это не значит, что она будет и завтра работать. Поэтому нужно постоянно, каждый день делать автоматизированное тестирование, в продакшене в том числе.
3. Обязательно нужно владеть клиентами (библиотеками).
Пользователи могут не знать, как работают базы данных. Они могут не понимать, зачем нужны таймауты, keep-alive. Поэтому лучше владеть этими клиентами — вам будет спокойнее.
4. Нужно определить свои принципы построения системы и свои гарантии, и всегда соблюдать их.
Таким образом можно поддерживать 6 тысяч серверов баз данных.
Вопросы и ответы
— Что будет, если есть дисбаланс нагрузки на шарды — какая-то метаинформация о каком-то файле оказалась популярнее? Есть ли возможность этот шард расплитить, или нагрузка на шарды не отличается нигде на порядки?
Она не отличается на порядки. Она практически нормально распределена. У нас есть троттлинг, то есть мы не можем перегрузить шард по сути, мы троттлим на уровне клиента. Вообще бывает такое, что какая-нибудь звезда выкладывает фотографию, и шард практически взрывается. Тогда мы баним эту ссылку
— Вы говорили у вас 992 алерта. Можно поподробнее, что это такое — это из коробки или это создается? Если создается, то это ручной труд или что-то вроде машинного обучения?
Это все создается вручную. У нас есть собственная внутренняя система, называется Vortex, где хранятся метрики, в ней поддерживаются алерты. Есть yaml-файл, в котором написано, что есть условие, например, что бэкапы должны выполняться каждый день, и если это условие выполняется, то алерт не срабатывает. Если не выполняется, тогда приходит алерт.
Это наша внутренняя разработка, потому что мало кто умеет хранить столько метрик, сколько нам нужно.
— Насколько крепкие должны быть нервы, чтобы делать DRT? Ты уронил, CODERED, не поднимается, с каждой минутой паники все больше.
Вообще работать в базах данных — это реально боль. Если база данных упала, сервис не работает, весь Dropbox не работает. Это реальная боль. DRT полезно тем, что это бизнес-часы. То есть я готов, я сижу за рабочим столом, я выпил кофе, я свеж, я готов сделать все, что угодно.
У нас в 4 часа ночи умирают 40 мастеров. Когда умирает 40 мастеров, это реально очень страшно и опасно. DRT — это не страшно и не опасно. Мы лежали где-то час.
Кстати, DRT — это хороший способ отрепетировать такие моменты, чтобы мы точно знали, какая последовательность действий нужна, если что-то массово поломается.
— Хотел бы подробнее узнать про переключение master-master. Во-первых, почему не используется кластер, к примеру? Кластер баз данных, то есть не master-slave с переключением, а master-master аппликация, чтобы если один упал, то и не страшно.
Вы имеете в виду что-нибудь вроде group replication, galera cluster и т.п.? Мне кажется, group application еще не готов к жизни. Galera мы, к сожалению, еще не пробовали. Это здорово, когда фейловер есть внутри вашего протокола, но, к сожалению, у них есть очень многих дргуих проблем, и не так просто перейти на это решение.
— Кажется, в MySQL 8 есть что-то типа InnoDb кластера. Не пробовали?
У нас до сих пор еще 5.6 стоит. Я не знаю, когда мы перейдем на 8. Может, попробуем.
— В таком случае, если у вас есть один большой master, при переключении с одного на другой, получается на slave-серверах высокой нагрузкой скапливается очередь. Если master погасить, надо, чтобы очередь добежала, чтобы slave переключить в режим master — или как-то по-другому это делается?
Нагрузка на master регулируется semisync’ом. Semisync ограничивает запись на мастер производительностью slave-серверов. Конечно, может быть такое, что транзакция пришла, semisync отработал, но slave’ы очень долго проигрывают эту транзакцию. Нужно тогда подождать, пока slave проиграет эту транзакцию до конца.
— Но тогда на master будут поступать новые данные, и надо будет.
Когда мы запускаем процесс promotion, мы отключаем I/O. После этого master не может ничего записать, потому что semisync репликация. Может прийти фантомное чтение, к сожалению, но это другая проблема уже.
— Эти все красивые стейт—машины — на чем написаны скрипты и как сложно добавить новый шаг? Что нужно сделать тому, кто пишет эту систему?
Все скрипты написаны на Python, все сервисы написаны на Go. Это наша политика. Логику поменять несложно — просто в Python-коде, по которому генерируется стейт-диаграмма.
— А можно подробнее про тестирование. Как написаны тесты, как они разворачивают ноды в виртуалке — это контейнеры?
Да. Тестирование у нас собирается с помощью Bazel. Есть некие настроечные файлы (json) и Bazel поднимает скрипт, который по этому настроечному файлу создает топологию для нашего теста. Там описаны разные топологии.
У нас это все работает в docker-контейнерах: либо это работает в CI, либо на Devbox. У нас есть система Devbox. Мы все разрабатываем на некоем удаленном сервере, и это может на нем работать, например. Там это тоже запускается внутри Bazel, внутри docker-контейнера или в Bazel Sandbox. Bazel очень сложный, но прикольный.
— Когда вы сделали на одном сервере 4 инстанса, не потеряли ли вы в эффективности использования памяти?
Каждый инстанс стал меньше. Соответственно, чем с меньшей памятью MySQL оперирует, тем ему проще жить. Любой системе проще оперировать небольшим количеством памяти. В этом месте мы ничего не потеряли. У нас есть простейшие С-группы, которые ограничивают по памяти эти инстансы.
— Если у вас 6 000 серверов хранят базы данных, можете назвать, сколько миллиардов петабайт хранится в ваших файлах?
Это десятки экзабайт, мы переливали данные с Амазона в течение года.
— Получается, у вас вначале было 8 серверов, на них по 200 шардов, потом 400 серверов по 4 шарда. У вас 1600 шардов — это какое-то жестко заданное значение? Вы больше не сможете никогда сделать? Это будет больно, если вам понадобится, например, 3 200 шардов?
Да, изначально было 1600. Это было сделано чуть меньше 10 лет назад, и до сих пор живем. Но у нас еще есть 4 шарда — в 4 раза мы можем еще увеличить место.
— Как умирают сервера, в основном по каким причинам? Что происходит чаще, что реже, и особенно интересно, происходят ли спонтанные карапты блоков?
Самое главное — это диски вылетают. У нас RAID 0 — диск вылетел, мастер умер. Это самая главная проблема, но нам проще заменить этот сервер. Google проще заменить дата-центр, нам сервер пока еще. Corruption checksum у нас практически не бывало. Если честно, я не помню, когда последний раз такое было. Просто мы достаточно часто обновляем мастера. У нас время жизни одного мастера ограничено 60 днями. Он не может жить дольше, после этого мы его заменяем на новый сервер, потому что почему-то в MySQL постоянно что-то накапливается, и через 60 дней мы видим, что начинают проблемы происходить. Может быть, не в MySQL, может быть, в Linux.
Мы не знаем, что это за проблема и не хотим с этим разбираться. Мы просто ограничили время 60 днями, и обновляем весь стек. Не нужно прикипать к одному мастеру.
— Вы сказали, что за последние 6 дней можете восстановиться из бэкапа на любое состояние. Например, человек залил JPEG с одним названием, потом залил такой же JPEG, но измененный, то вы можете достать первую версию? То есть, получается, вы храните версионность файлов и какие-то метаданные с версиями? Если человек попросит — я хочу достать первую версию файла, вы можете ему это отдать или нет?
Мы храним информацию о файле, о блоках. Мы можем — в Dropbox есть возможность восстанавливать файлы.
— Как вы потом вычищаете это все? Нет проблем с фрагментацией на дисках и так далее? Много данных стирается с диска, получается, через какое-то время, когда версия становится ненужной, протухшей? Допустим, человек залил 10 версий файлов поочередно. Очевидно, через 7 дней в бэкапе вы поймете, что вам первые 6 версий уже не нужны, и их нужно удалить. Или они вечно хранятся?
Вообще в Dropbox есть какие-то гарантии, за какой промежуток времени сколько версий хранится. Это немножко другое. Есть система, которая умеет восстанавливать файлы, и там файлы просто не удаляются сразу, они в какую-то корзину кладутся.
Есть проблема, когда совершенно все удалено. Файлы есть, есть блоки, но в базе данных нет информации, как из этих блоков файл собрать. В такой момент мы можем проиграть до какого-то момента, то есть восстановились за 6 дней, проиграли до момента, когда этот файл был удален, не стали его удалять, восстановили и отдали пользователю.
Следите за блогом или подпишитесь на рассылку, в facebook или youtube-канал — мы регулярно публикуем свежие материалы и обновления в подготовке Highload++ 2018. В последнем можно принять деятельное участие, до 1 сентября отправив заявку на доклад.



