Истинная реализация нейросети с нуля на языке программирования C#

Здравствуй, Хабр! Данная статья предназначена для тех, кто приблизительно шарит в математических принципах работы нейронных сетей и в их сути вообще, поэтому советую ознакомиться с этим перед прочтением. Хоть как-то понять, что происходит можно сначала здесь, потом тут.
Недавно мне пришлось сделать нейросеть для распознавания рукописных цифр(сегодня будет не совсем её код) в рамках школьного проекта, и, естественно, я начал разбираться в этой теме. Посмотрев приблизительно достаточно об этом в интернете, я понял чуть более, чем ничего. Но неожиданно(как это обычно бывает) получилось наткнуться на книгу Саймона Хайкина(не знаю почему раньше не загуглил). И тогда началось потное вкуривание матчасти нейросетей, состоящее из одного матана.
На самом деле, несмотря на обилие математики, она не такая уж и запредельно сложная. Понять сатанистские каракули и письмена этого пособия сможет среднестатистический 11-классник товарищ-физмат или 1
2-курсник технарьского учебного заведения. Помимо этого, пусть книга достаточно объёмная и трудная для восприятия, но вещи, написанные в ней, реально объясняют, что «твориться у тачки под капотом». Как вы поняли я крайне рекомендую(ни в коем случае не рекламирую) «Нейронные сети. Полный курс» Саймона Хайкина к прочтению в том случае, если вам придётся столкнуться с применением/написанием/разработкой нейросетей и прочего подобного stuff’а. Хотя в ней нет материала про новомодные свёрточные сети, никто не мешает загуглить лекции от какого-нибудь харизматичного работника Yandex/Mail.ru/etc. никто не мешает.
Моя видеокарта называется ATI Radeon HD Mobility 4570. И если кто знает, как обратиться к её мощностям для параллелизации нейросетевых вычислений, пожалуйста, напишите в комментарии. Тогда вы поможете мне, и возможно у этой статьи появится продолжение. Не осуждается предложение других ЯП.
Просто, как я понял, она настолько старая, что вообще ничего не поддерживает. Может быть я не прав.
То, что я увидел(третье вообще какая-то эзотерика с некрасивым кодом), несомненно может повергнуть в шок и вас, так как выдаваемое за нейросети связано с ними так же, как и тексты Lil Pump со смыслом. Вскоре я понял, что могу рассчитывать только на себя, и решил написать данную статью, чтобы всякие юзеры не вводили других в заблуждение.
Здесь я не буду рассматривать код сети для распознования цифр(как упоминалось ранее), ибо я оставил его на флэшке, удалив с ноута, а искать сей носитель информации мне лень, и в связи с этим я помогу вам сконструировать многослойный полносвязный персептрон для решения задачи XOR и XAND(XNOR, хз как ещё).
Многослойный полносвязный персептрон.
Один скрытый слой.
4 нейрона в скрытом слое(на этом количестве персептрон сошёлся).
Алгоритм обучения — backpropagation.
Критерий останова — преодоление порогового значения среднеквадратичной ошибки по эпохе.(0.001)
Скорость обучения — 0.1.
Функция активации — логистическая сигмоидальная.

Потом надо осознать, что нам нужно куда-то записывать веса, проводить вычисления, немного дебажить, ну и кортежи поиспользовать. Соответственно, using’и у нас такие.
В папке release||debug этого прожекта располагаются файлы(на каждый слой по одному) по имени типа (fieldname)_memory.xml сами знаете для чего. Они создаются заранее с учётом общего количества весов каждого слоя. Знаю, что XML — это не лучший выбор для парсинга, просто времени было немного на это дело.
Также вычислительные нейроны у нас двух типов: скрытые и выходные. А веса могут считываться или записываться в память. Реализуем сию концепцию двумя перечислениями.
Всё остальное будет происходить внутри пространства имён, которое я назову просто: Neural Network.
Прежде всего, важно понимать, почему нейроны входного слоя я изобразил квадратами. Ответ прост. Они ничего не вычисляют, а лишь улавливают информацию из внешнего мира, то есть получают сигнал, который будет пропущен через сеть. Вследствие этого, входной слой имеет мало общего с остальными слоями. Вот почему стоит вопрос: делать для него отдельный класс или нет? На самом деле, при обработке изображений, видео, звука стоит его сделать, лишь для размещения логики по преобразованию и нормализации этих данных к виду, подаваемому на вход сети. Вот почему я всё-таки напишу класс InputLayer. В нём находиться обучающая выборка организованная необычной структурой. Первый массив в кортеже — это сигналы-комбинации 1 и 0, а второй массив — это пара результатов этих сигналов после проведения операций XOR и XAND(сначала XOR, потом XAND).
Теперь реализуем самое важное, то без чего ни одна нейронная сеть не станет терминатором, а именно — нейрон. Я не буду использовать смещения, потому что просто не хочу. Нейрон будет напоминать модель МакКаллока-Питтса, но иметь другую функцию активации(не пороговую), методы для вычисления градиентов и производных, свой тип и совмещенные линейные и нелинейные преобразователи. Естественно без конструктора уже не обойтись.
Ладно у нас есть нейроны, но их необходимо объединить в слои для вычислений. Возвращаясь к моей схеме выше, хочу объяснить наличие чёрного пунктира. Он разделяет слои так, чтобы показать, что они содержат. То есть один вычислительный слой содержит нейроны и веса для связи с нейронами предыдущего слоя. Нейроны объединяются массивом, а не списком, так как это менее ресурсоёмко. Веса организованы матрицей(двумерным массивом) размера(нетрудно догадаться) [число нейронов текущего слоя X число нейронов предыдущего слоя]. Естественно, слой инициализирует нейроны, иначе словим null reference. При этом эти слои очень похожи друг на друга, но имеют различия в логике, поэтому скрытые и выходной слои должны быть реализованы наследниками одного базового класса, который кстати оказывается абстрактным.
Класс Layer — это абстрактный класс, поэтому нельзя создавать его экземпляры. Это значит, что наше желание сохранить свойства «слоя» выполняется путём наследования родительского конструктора через ключевое слово base и пустой конструктор наследника в одну строчку(ибо вся логика конструктора определена в базовом классе, и её не надо переписывать).
Теперь непосредственно классы-наследники: Hidden и Output. Сразу два класса в цельном куске кода.
В принципе, всё самое важное я описал в комментариях. У нас есть все компоненты: обучающие и тестовые данные, вычислительные элементы, их «конгламераты». Теперь настало время всё связать обучением. Алгоритм обучения — backpropagation, следовательно критерий останова выбираю я, и выбор мой — есть преодоление порогового значения среднеквадратичной ошибки по эпохе, которое я выбрал равным 0.001. Для поставленной цели я написал класс Network, описывающий состояние сети, которое принимается в качестве параметра многих методов, как вы могли заметить.
Результат обучения.
Итого, путём насилования мозга несложных манипуляций, мы получили основу работающей нейронной сети. Для того, чтобы заставить её делать что-либо другое, достаточно поменять класс InputLayer и подобрать параметры сети для новой задачи.
За сим всё, буду рад ответить на вопросы в комментариях, а пока извольте, новые дела ждут.
P.S.: Для желающих потыкать в код клацать.
UPD1(22.10.2020): господи как давно это было, надеюсь больше не буду писать такие статьи. Скорее всего в то время хотел поделиться с сообществом таким кодом, но так в ML никто не пишет)
Нейросети для чайников. Начало
Так получилось, что в университете тема нейросетей успешно прошла мимо моей специальности, несмотря на огромный интерес с моей стороны. Попытки самообразования несколько раз разбивались невежественным челом о несокрушимые стены цитадели науки в облике непонятных «с наскока» терминов и путанных объяснений сухим языком вузовских учебников.
В данной статье (цикле статей?) я попытаюсь осветить тему нейросетей с точки зрения человека непосвященного, простым языком, на простых примерах, раскладывая все по полочкам, а не «массив нейронов образует перцептрон, работающий по известной, зарекомендовавшей себя схеме».
Заинтересовавшихся прошу под кат.
Для чего же нужны нейросети?
Нейросеть – это обучаемая система. Она действует не только в соответствии с заданным алгоритмом и формулами, но и на основании прошлого опыта. Этакий ребенок, который с каждым разом складывает пазл, делая все меньше ошибок.
И, как принято писать у модных авторов – нейросеть состоит из нейронов.
Тут нужно сделать остановку и разобраться.
Договоримся, что нейрон – это просто некая воображаемая чёрная коробка, у которой кучка входных отверстий и одно выходное.
Причем как входящая, так и исходящая информация может быть аналоговой (чаще всего так и будет).
Как выходной сигнал формируется из кучи входных – определяет внутренний алгоритм нейрона.
Для примера напишем небольшую программу, которая будет распознавать простые изображения, скажем, буквы русского языка на растровых изображениях.
Условимся, что в исходном состоянии наша система будет иметь «пустую» память, т.е. этакий новорожденный мозг, готовый к бою.
Для того чтобы заставить его корректно работать, нам нужно будет потратить время на обучение.
Уворачиваясь от летящих в меня помидоров, скажу, что писать будем на Delphi (на момент написания статьи была под рукой). Если возникнет необходимость – помогу перевести пример на другие языки.
Также прошу легкомысленно отнестись к качеству кода – программа писалась за час, просто чтобы разобраться с темой, для серьезных задач такой код вряд ли применим.
Итак, исходя из поставленной задачи — сколько вариантов выхода может быть? Правильно, столько, сколько букв мы будем уметь определять. В алфавите их пока только 33, на том и остановимся.
Далее, определимся со входными данными.Чтобы слишком не заморачиватсья – будем подавать на вход битовый массив 30х30 в виде растрового изображения:
В итоге – нужно создать 33 нейрона, у каждого из которых будет 30х30=900 входов.
Создадим класс для нашего нейрона:
Создадим массив нейронов, по количеству букв:
Теперь вопрос – где мы будем хранить «память» нейросети, когда программа не работает?
Чтобы не углубляться в INI или, не дай бог, базы данных, я решил хранить их в тех же растровых изображениях 30х30.
Вот например, память нейрона «К» после прогона программы по разным шрифтам:
Как видно, самые насыщенные области соответствуют наиболее часто встречаемым пикселям.
Будем загружать «память» в каждый нейрон при его создании:
В начале работы необученной программы, память каждого нейрона будет белым пятном 30х30.
Распознавать нейрон будет так:
— Берем 1й пиксель
— Сравниваем его с 1м пикселем в памяти (там лежит значение 0..255)
— Сравниваем разницу с неким порогом
— Если разница меньше порога – считаем, что в данной точке буква похожа на лежащую в памяти, добавляем +1 к весу нейрона.
И так по всем пикселям.
Вес нейрона – это некоторое число (в теории до 900), которое определяется степенью сходства обработанной информации с хранимой в памяти.
В конце распознавания у нас будет набор нейронов, каждый из которых считает, что он прав на сколько-то процентов. Эти проценты – и есть вес нейрона. Чем больше вес, тем вероятнее, что именно этот нейрон прав.
Теперь будем скармливать программе произвольное изображение и пробегать каждым нейроном по нему:
Как только закончится цикл для последнего нейрона – будем выбирать из всех тот, у которого вес больше:
Именно по вот этому значению max_n, программа и скажет нам, что, по её мнению, мы ей подсунули.
По началу это будет не всегда верно, поэтому нужно сделать алгоритм обучения.
Само обновление памяти будем делать так:
Т.е. если данная точка в памяти нейрона отсутствует, но учитель говорит, что она есть в этой букве – мы её запоминаем, но не полностью, а только наполовину. С дальнейшим обучением, степень влияния данного урока будет увеличиваться.
Вот несколько итераций для буквы Г:
На этом наша программа готова.
Обучение
Начнем обучение.
Открываем изображения букв и терпеливо указываем программе на её ошибки:
Через некоторое время программа начнет стабильно определять даже не знакомые ей ранее буквы:
Заключение
Программа представляет собой один сплошной недостаток – наша нейросеть очень глупа, она не защищена от ошибок пользователя при обучении и алгоритмы распознавания просты как палка.
Зато она дает базовые знания о функционировании нейросетей.
Если данная статья заинтересует уважаемых хабравчан, то я продолжу цикл, постепенно усложняя систему, вводя дополнительные связи и веса, рассмотрю какую-нибудь из популярных архитектур нейросетей и т.д.
Поиздеваться над нашим свежерожденный интеллектом вы можете, скачав программу вместе с исходниками тут.
За сим откланяюсь, спасибо за чтение.
UPD: У нас получилась заготовка для нейросети. Пока что это ещё ей не является, но в следующей статье мы постараемся сделать из неё полноценную нейросеть.
Спасибо Shultc за замечание.
Нейросеть с нуля своими руками. Часть 1. Теория
Здравствуйте. Меня зовут Андрей, я frontend-разработчик и я хочу поговорить с вами на такую тему как нейросети. Дело в том, что ML технологии все глубже проникают в нашу жизнь, и о нейросетях сказано и написано уже очень много, но когда я захотел разобраться в этом вопросе, я понял что в интернете есть множество гайдов о том как создать нейросеть и выглядят они примерно следующим образом:
Более подробная информация разбросана кусками по всему интернету. Поэтому я постарался собрать ее воедино и изложить в этой статье. Сразу оговорюсь, что я не являюсь специалистом в области ML или биологии, поэтому местами могу быть не точным. В таком случае буду рад вашим комментариям.
Пока я писал эту статью я понял, что у меня получается довольно объемный лонгрид, поэтому решил разбить ее на несколько частей. В первой части мы поговорим о теории, во второй напишем собственную нейросеть с нуля без использования каких-либо библиотек, в третьей попробуем применить ее на практике.
Так как это моя первая публикация, появляться они будут по мере прохождения модерации, после чего я добавлю ссылки на все части. Итак, приступим.
Для чего нужны нейросети
В нашем глазу есть сенсоры, которые улавливают количество света попадающего через зрачок на заднюю поверхность глаза. Они преобразуют эту информацию в электрические импульсы и передают на прикрепленные к ним нервные окончания. Далее это сигнал проходит по всей нейронной сети, которая принимает решение о том, не опасно ли такое количество света для глаза, достаточно ли оно для того, чтобы четко распознавать визуальную информацию, и нужно ли, исходя из этих факторов, уменьшить или увеличить количество света.
На выходе этой сети находятся мышцы, отвечающие за расширение или сужение зрачка, и приводят эти механизмы в действие в зависимости от сигнала, полученного из нейросети. И таких механизмов огромное количество в теле любого живого существа, обладающего нервной системой.
Устройство нейрона
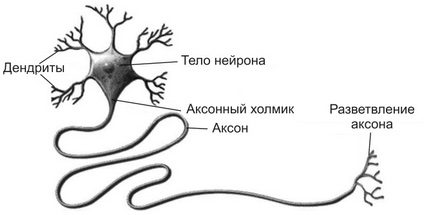
Дендриты нейрона создают дендритное дерево, размер которого зависит от числа контактов с другими нейронами. Это своего рода входные каналы нервной клетки. Именно с их помощью нейрон получает сигналы от других нейронов.
Тело нейрона в природе, достаточно сложная штука, но именно в нем все сигналы, поступившие через дендриты объединяются, обрабатываются, и принимается решение о том передавать ли сигнал далее, и какой силы он должен быть.
Нейросети в IT
Что же, раз механизм нам понятен, почему бы нам не попробовать воспроизвести его с помощью информационных технологий?
Итак, у нас есть входной слои нейронов, которые, по сути, являются сенсорами нашей системы. Они нужны для того, чтобы получить информацию из окружающей среды и передать ее дальше в нейросеть.
Также у нас есть несколько слоев нейронов, каждый из которых получает информацию от всех нейронов предыдущего слоя, каким-то образом ее обрабатывают, и передают на следующий слой.
И, наконец, у нас есть выходные нейроны. Исходя из сигналов, поступающих от них, мы можем судить о принятом нейросетью решении.
Такой простейший вариант нейронной сети называется перцептрон, и именно его мы с вами и попробуем воссоздать.
Все нейроны по сути одинаковы, и принимают решение о том, какой силы сигнал передать далее с помощью одного и того же алгоритма. Это алгоритм называется активационной функцией. На вход она получает сумму значений входных сигналов, а на выход передает значение выходного сигнала.
Но в таком случае, получается, что все нейроны любого слоя будут получать одинаковый сигнал, и отдавать одинаковое значение. Таким образом мы могли бы заменить всю нашу сеть на один нейрон. Чтобы устранить эту проблему, мы присвоим входу каждого нейрона определенный вес. Этот вес будет обозначать насколько важен для каждого конкретного нейрона сигнал, получаемый от другого нейрона. И тут мы подходим к самому интересному.
То есть мы подаем на вход нейросети определенные данные, для которых мы знаем, каким должен быть результат. Далее мы сравниваем результат, который нам выдала нейросеть с ожидаемым результатом, вычисляем ошибку, и корректируем веса нейронов таким образом, чтобы эту ошибку минимизировать. И повторяем это действие большое количество раз для большого количества наборов входных и выходных данных, чтобы сеть поняла какие сигналы на каком нейроне ей важны больше, а какие меньше. Чем больше и разнообразнее будет набор данных для обучения, тем лучше нейросеть сможет обучиться и впоследствии давать правильный результат. Этот процесс называется обучением с учителем.
Добавим немного математики.
В качестве активационной функции нейрона может выступать любая функция, существующая на всем отрезке значений, получающихся на выходе нейрона и входных данных. Для нашего примера мы возьмем сигмоиду. Она существует на отрезке от минус бесконечности до бесконечности, плавно меняется от 0 до 1 и имеет значение 0,5 в точке 0. Идеальный кандидат. Выглядит она следующим образом:

Таким образом сумма входных значений первого нейрона скрытого слоя будет равна
Передав это значение в активационную функцию, мы получим значение, которое наш нейрон передаст далее по сети в следующий слой.
sigmoid(0,22) = 1 / (1 + e^-0,22) = 0,55
Аналогичные операции произведём для второго нейрона скрытого слоя и получим значение 0,60.
И, наконец, повторим эти операции для единственного нейрона в выходном слое нашей нейросети и получим значение 0,60, что мы условились считать как истину.
Пока что это абсолютно случайное значение, так как веса мы выбирали случайно. Но, предположим, что мы знаем ожидаемое значение для такого набора входных данных и наша сеть ошиблась. В таком случае нам нужно вычислить ошибку и изменить параметры весов, таким образом немного обучив нашу нейросеть.
Первым делом рассчитаем ошибку на выходе сети. Делается это довольно просто, нам просто нужно получить разницу полученного значения и ожидаемого.
Чтобы узнать насколько нам надо изменить веса нашего нейрона, нам нужно величину ошибки умножить на производную от нашей активационной функции в этой точке. К счастью, производная от сигмоиды довольно проста.

Таким образом наша дельта весов будет равна
Новый вес для входа нейрона рассчитывается по формуле
Аналогичным образом рассчитаем новый вес для второго входа выходного нейрона:
Итак, мы скорректировали веса для входов выходного нейрона, но чтобы рассчитать остальные, нам нужно знать ошибку для каждого из нейронов нашей нейросети. Это делается не так очевидно как для выходного нейрона, но тоже довольно просто. Чтобы получить ошибку каждого нейрона нам нужно новый вес нейронной связи умножить на дельту. Таким образом ошибка первого нейрона скрытого слоя равна:
error = 0.18 * 0.24 = 0.04
Теперь, зная ошибку для нейрона, мы можем произвести все те же самые операции, что провели ранее, и скорректировать его веса. Этот процесс называется обратным распространением ошибки.
Итак, мы знаем как работает нейрон, что такое нейронные связи в нейросети и как происходит процесс обучения. Этих знаний достаточно чтобы применить их на практике и написать простейшую нейросеть, чем мы и займемся в следующей части статьи.
Создаём простую нейросеть

Что мы будем делать? Мы попробуем создать простую и совсем маленькую нейронную сеть, которую мы объясним и научим что-нибудь различать. При этом не будем вдаваться в историю и математические дебри (такую информацию найти очень легко) — вместо этого постараемся объяснить задачу (не факт, что удастся) вам и самим себе рисунками и кодом.
Многие из терминов в нейронных сетях связаны с биологией, поэтому давайте начнем с самого начала:
Мозг — штука сложная, но и его можно разделить на несколько основных частей и операций:
Возбудитель может быть и внутренним (например, образ или идея):
А теперь взглянем на основные и упрощенные части мозга:
Мозг вообще похож на кабельную сеть.
Нейрон — основная единица исчислений в мозге, он получает и обрабатывает химические сигналы других нейронов, и, в зависимости от ряда факторов, либо не делает ничего, либо генерирует электрический импульс, или Потенциал Действия, который затем через синапсы подает сигналы соседним связанным нейронам:
Сны, воспоминания, саморегулируемые движения, рефлексы да и вообще все, что вы думаете или делаете — все происходит благодаря этому процессу: миллионы, или даже миллиарды нейронов работают на разных уровнях и создают связи, которые создают различные параллельные подсистемы и представляют собой биологическую нейронную сеть.
Разумеется, это всё упрощения и обобщения, но благодаря им мы можем описать простую
нейронную сеть:
И описать её формализовано с помощью графа:
Тут требуются некоторые пояснения. Кружки — это нейроны, а линии — это связи между ними,
и, чтобы не усложнять на этом этапе, взаимосвязи представляют собой прямое передвижение информации слева направо. Первый нейрон в данный момент активен и выделен серым. Также мы присвоили ему число (1 — если он работает, 0 — если нет). Числа между нейронами показывают вес связи.
Графы выше показывают момент времени сети, для более точного отображения, нужно разделить его на временные отрезки:
Для создания своей нейронной сети нужно понимать, как веса влияют на нейроны и как нейроны обучаются. В качестве примера возьмем кролика (тестового кролика) и поставим его в условия классического эксперимента.
Когда на них направляют безопасную струю воздуха, кролики, как и люди, моргают:
Эту модель поведения можно нарисовать графами:
Как и в предыдущей схеме, эти графы показывают только тот момент, когда кролик чувствует дуновение, и мы таким образом кодируем дуновение как логическое значение. Помимо этого мы вычисляем, срабатывает ли второй нейрон, основываясь на значении веса. Если он равен 1, то сенсорный нейрон срабатывает, мы моргаем; если вес меньше 1, мы не моргаем: у второго нейрона предел — 1.
Введем еще один элемент — безопасный звуковой сигнал:
Мы можем смоделировать заинтересованность кролика так:
Основное отличие в том, что сейчас вес равен нулю, поэтому моргающего кролика мы не получили, ну, пока, по крайней мере. Теперь научим кролика моргать по команде, смешивая
раздражители (звуковой сигнал и дуновение):
Важно, что эти события происходят в разные временные эпохи, в графах это будет выглядеть так:
Сам по себе звук ничего не делает, но воздушный поток по-прежнему заставляет кролика моргать, и мы показываем это через веса, умноженные на раздражители (красным).
Обучение сложному поведению можно упрощённо выразить как постепенное изменение веса между связанными нейронами с течением времени.
Чтобы обучить кролика, повторим действия:
Для первых трех попыток схемы будут выглядеть так:
Обратите внимание, что вес для звукового раздражителя растет после каждого повтора (выделено красным), это значение сейчас произвольное — мы выбрали 0.30, но число может быть каким угодно, даже отрицательным. После третьего повтора вы не заметите изменения в поведении кролика, но после четвертого повтора произойдет нечто удивительное — поведение изменится.
Мы убрали воздействие воздухом, но кролик все еще моргает, услышав звуковой сигнал! Объяснить это поведение может наша последняя схемка:
Мы обучили кролика реагировать на звук морганием.
В условиях реального эксперимента такого рода может потребоваться более 60 повторений для достижения результата.
Теперь мы оставим биологический мир мозга и кроликов и попробуем адаптировать всё, что
узнали, для создания искусственной нейросети. Для начала попробуем сделать простую задачу.
Допустим, у нас есть машина с четырьмя кнопками, которая выдает еду при нажатии правильной
кнопки (ну, или энергию, если вы робот). Задача — узнать, какая кнопка выдает вознаграждение:
Мы можем изобразить (схематично), что делает кнопка при нажатии следующим образом:
Такую задачу лучше решать целиком, поэтому давайте посмотрим на все возможные результаты, включая правильный:
Нажмите на 3-ю кнопку, чтобы получить свой ужин.
Чтобы воспроизвести нейронную сеть в коде, нам для начала нужно сделать модель или график, с которым можно сопоставить сеть. Вот один подходящий под задачу график, к тому же он хорошо отображает свой биологический аналог:
Эта нейронная сеть просто получает входящую информацию — в данном случае это будет восприятие того, какую кнопку нажали. Далее сеть заменяет входящую информацию на веса и делает вывод на основе добавления слоя. Звучит немного запутанно, но давайте посмотрим, как в нашей модели представлена кнопка:
Обратите внимание, что все веса равны 0, поэтому нейронная сеть, как младенец, совершенно пуста, но полностью взаимосвязана.
Таким образом мы сопоставляем внешнее событие с входным слоем нейронной сети и вычисляем значение на ее выходе. Оно может совпадать или не совпадать с реальностью, но это мы пока проигнорируем и начнем описывать задачу понятным компьютеру способом. Начнем с ввода весов (будем использовать JavaScript):
Следующий шаг — создание функции, которая собирает входные значения и веса и рассчитывает значение на выходе:
Как и ожидалось, если мы запустим этот код, то получим такой же результат, как в нашей модели или графике…
Следующим шагом в усовершенствовании нашей нейросети будет способ проверки её собственных выходных или результирующих значений сопоставимо реальной ситуации,
давайте сначала закодируем эту конкретную реальность в переменную:
Чтобы обнаружить несоответствия (и сколько их), мы добавим функцию ошибки:
С ней мы можем оценивать работу нашей нейронной сети:
Но что более важно — как насчет ситуаций, когда реальность дает положительный результат?
Теперь мы знаем, что наша модель нейронной сети не работает (и знаем, насколько), здорово! А здорово это потому, что теперь мы можем использовать функцию ошибки для управления нашим обучением. Но всё это обретет смысл в том случае, если мы переопределим функцию ошибок следующим образом:
Неуловимое, но такое важное расхождение, молчаливо показывающее, что мы будем
использовать ранее полученные результаты для сопоставления с будущими действиями
(и для обучения, как мы потом увидим). Это существует и в реальной жизни, полной
повторяющихся паттернов, поэтому оно может стать эволюционной стратегией (ну, в
большинстве случаев).
Далее в наш пример кода мы добавим новую переменную:
Подведем промежуточный итог. Мы начали с задачи, сделали её простую модель в виде биологической нейронной сети и получили способ измерения её производительности по сравнению с реальностью или желаемым результатом. Теперь нам нужно найти способ исправления несоответствия — процесс, который как и для компьютеров, так и для людей можно рассматривать как обучение.
Как обучать нейронную сеть?
Основа обучения как биологической, так и искусственной нейронной сети — это повторение
и алгоритмы обучения, поэтому мы будем работать с ними по отдельности. Начнем с
обучающих алгоритмов.
В природе под алгоритмами обучения понимаются изменения физических или химических
характеристик нейронов после проведения экспериментов:
Драматическая иллюстрация того, как два нейрона меняются по прошествии времени в коде и нашей модели «алгоритм обучения» означает, что мы просто будем что-то менять в течение какого-то времени, чтобы облегчить свою жизнь. Поэтому давайте добавим переменную для обозначения степени облегчения жизни:
Это изменит веса (прям как у кролика!), особенно вес вывода, который мы хотим получить:
Как кодировать такой алгоритм — ваш выбор, я для простоты добавляю коэффициент обучения к весу, вот он в виде функции:
При использовании эта обучающая функция просто добавит наш коэффициент обучения к вектору веса активного нейрона, до и после круга обучения (или повтора) результаты будут такими:
Окей, теперь, когда мы движемся в верном направлении, последней деталью этой головоломки будет внедрение повторов.
Это не так уж и сложно, в природе мы просто делаем одно и то же снова и снова, а в коде мы просто указываем количество повторов:
И внедрение в нашу обучающую нейросеть функции количества повторов будет выглядеть так:
Ну и наш окончательный отчет:
Теперь у нас есть вектор веса, который даст только один результат (курицу на ужин), если входной вектор соответствует реальности (нажатие на третью кнопку).
Так что же такое классное мы только что сделали?
В этом конкретном случае наша нейронная сеть (после обучения) может распознавать входные данные и говорить, что приведет к желаемому результату (нам всё равно нужно будет программировать конкретные ситуации):
Кроме того, это масштабируемая модель, игрушка и инструмент для нашего с вами обучения. Мы смогли узнать что-то новое о машинном обучении, нейронных сетях и искусственном интеллекте.
Заметки и список литературы для дальнейшего чтения
Я пытался избежать математики и строгих терминов, но если вам интересно, то мы построили перцептрон, который определяется как алгоритм контролируемого обучения (обучение с учителем) двойных классификаторов — тяжелая штука.
Биологическое строение мозга — тема не простая, отчасти из-за неточности, отчасти из-за его сложности. Лучше начинать с Neuroscience (Purves) и Cognitive Neuroscience (Gazzaniga). Я изменил и адаптировал пример с кроликом из Gateway to Memory (Gluck), которая также является прекрасным проводником в мир графов.
Еще один шикарный ресурс An Introduction to Neural Networks (Gurney), подойдет для всех ваших нужд, связанных с ИИ.
А теперь на Python! Спасибо Илье Андшмидту за предоставленную версию на Python:
А теперь на GO! За эту версию благодарю Кирана Мэхера.



