Таинственный код нашего генома
Расшифровка генетического код стала важным научным событием двадцатого века. Сейчас перед учеными появляются новые загадки о функционировании нашего генома.
Автор
Редакторы
Последовательность ДНК определяет строение белка с помощью триплетного генетического кода, в котором каждой аминокислоте соответствует три нуклеотида. Случайные мутации приводят к изменению последовательности нуклеотидов, в результате чего появляются новые варианты белков. Именно так до недавнего времени представляли себе ученые эволюцию белков. Но благодаря исследованиям последних лет оказалось, что помимо генетического кода есть и другие «коды», которые диктуют эволюции белков свои правила.
Одним из важных свойств генетического кода является его избыточность — каждая аминокислота, как правило, кодируется не одним, а 2–6 кодонами. Интересно, что при этом частота использования разных кодонов, отвечающих за одну и ту же аминокислоту, различается как в прокариотических, так и в эукариотических геномах [1]. У организмов с коротким жизненным циклом предпочтения одних кодонов другим связывают с необходимостью в увеличении эффективности транскрипции и стабильности мРНК [2], [3]. Однако в случае геномов млекопитающих такое объяснение подходит лишь для небольшого количества случаев, поэтому в последние годы ученые активно занимаются изучением особенностей геномов млекопитающих и причин предпочтительного использования тех или иных кодонов.
Важное значение в частоте использования кодонов играют транскрипционные факторы — к такому выводу пришла группа ученых из Университета Вашингтона под руководством Джона Стаматояннопоулоса (John A. Stamatoyannopoulos). В опубликованной в журнале Science статье обсуждается, как транскрипционные факторы могут управлять эволюцией белков посредством влияния на частоту использования кодонов [4].
Транскрипционные факторы (ТФ) — это белки, регулирующие транскрипцию генов при связывании с ДНК. ТФ могут повышать транскрипцию или снижать ее, влияя, таким образом, на количество мРНК и белка, соответствующих определенному гену. Долгое время считалось, что ТФ связываются только в некодирующей (не содержащей генов) части ДНК. В своем новом исследовании группа Стаматояннопоулоса выяснила, что на самом деле во многих генах человека ТФ связываются с кодирующими последовательностями ДНК (т.е. с теми, которые являются частью генов). Так как эффективность связывания ТФ с ДНК зависит от того, какие именно нуклеотиды находятся в сайте связывания, ТФ могут снижать возможное разнообразие кодонов в местах своей посадки (рис. 1). При этом даже нейтральные с точки зрения белка мутации (те, при которых последовательность аминокислот не меняется благодаря избыточности генетического кода) могут изменять эффективность связывания ТФ с ДНК и становиться материалом для естественного отбора. Получается, что эволюция белков определяется не только хорошо изученным генетическим кодом, но и другим особенным кодом — «кодом связывания ТФ». Ранее были описаны и некоторые другие «регуляторные» коды, которые контролируют организацию хроматина [5], пространственную структуру и сплайсинг мРНК [5], [6], эффективность трансляции [7], ко-трансляционный фолдинг белков [8] (рис. 2). Все они могут влиять на предпочтительное использование тех или иных кодонов.
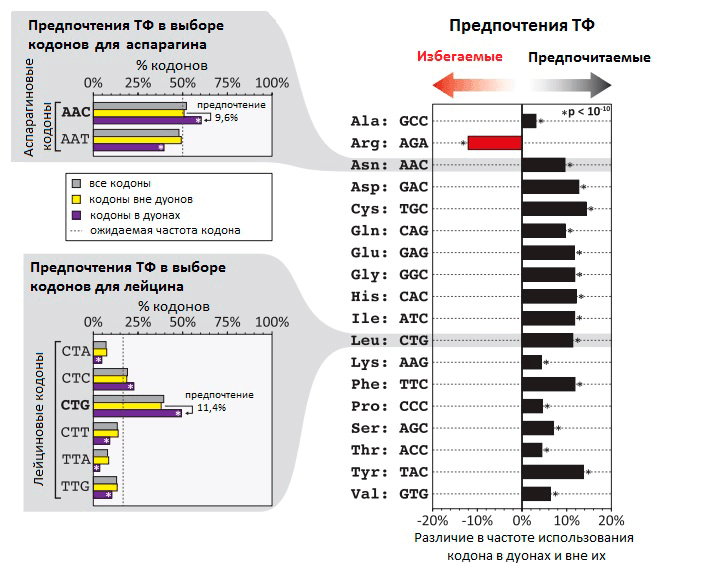
Рисунок 1. Неслучайная частота использования кодов в дуонах в местах связывания ТФ с ДНК. На гистограмме видно, что частота использования некоторых кодонов на 5–15% выше в дуонах, чем вне дуонов. В случае аргинина кодон AGA, напротив, гораздо реже встречается в дуонах, чем в других участках генома. В левой части рисунка — распределение частоты использования разных кодонов на примере кодонов для аспарагина и лейцина.
Насколько в геноме распространено применение дополнительных «регуляторных» кодов, которые перекрывают генетический код, и какое влияние они оказывают на эволюцию белков? Сотрудники лаборатории Стаматояннопоулоса попытались ответить на этот вопрос при исследовании «кода связывания ТФ». Чтобы выявить участки ДНК, связывающиеся с ТФ, они применили метод картирования с помощью дезоксирибонуклеазы I. Этот фермент разрушает одноцепочечные участки ДНК — если только они в этот момент не связаны с ТФ (в таком случае они сохранятся). Ученые исследовали 81 тип человеческих клеток, определив точные нуклеотидные последовательности связанных с ТФ участков генов. Оказалось, что приблизительно 14% кодонов в 86,9% генов человека связаны с различными транскрипционными факторами. В своей статье исследователи предлагают называть эти участки генов «дуонами», т.к. они кодируют два типа информации — информацию о белковой последовательности в виде генетического кода и информацию об экспрессии гена с помощью связывания ТФ. Для нормальной экспрессии гена необходимо связывание ДНК с ТФ, поэтому существуют определенные ограничения на использование различных кодонов, обусловленные строением ДНК-связывающего участка ТФ.
В геноме человека широко распространены однонуклеотидные полиморфизмы (single nucleotide polymorphisms, SNP) — различия последовательности гомологичных генов разных людей на один нуклеотид. Могут ли такие однонуклеотидные различия повлиять на эффективность связывания ТФ с ДНК? Чтобы узнать это, ученые из лаборатории Стаматояннопоулоса нашли на полученной ими карте дуонов почти 600 тыс. известных сайтов SNP, связанных с развитием какого-либо заболевания или проявлением определенного фенотипического признака. Оказалось, что 17,4% сайтов полиморфизма изменяют результаты картирования с помощью дезоксирибонуклеазы I, т.е. они, вероятно, снижают эффективность связывания ТФ с ДНК. Это изменение не зависит от того, является ли данный полиморфизм синонимичным или несинонимичным (т.е. влияет ли замена нуклеотида на замену аминокислоты в белке). Интересно, что значительная часть несинонимичных замен, хотя и приводит к изменению последовательности белка, не приводит к нарушению его функций. В этих случаях изменения нуклеотидной последовательности приводят только к нарушению связывания ТФ с ДНК. Эта находка поддерживает гипотезу о том, что SNP в кодирующей ДНК могут приводить к развитию заболеваний без влияния на функцию белка [9], [10]. Поэтому при изучении роли SNP в различных заболеваниях и при исследовании экзома необходимо учитывать весь спектр «регуляторных кодов», взаимодействующих с последовательностью гена.
«Регуляторные коды» далеко не всегда мирно и гармонично сосуществуют. В генах плодовой мушки Drosophila melanogaster ближе к концу экзонов наблюдается резкое снижение частоты использования оптимальных для трансляции кодонов и повышение частоты использования кодонов, которые облегчают сплайсинг мРНК [11]. Это показывает, что в ходе эволюции потребность в точном сплайсинге была выше, чем потребность в более эффективной трансляции. Также при исследовании дуонов и других ТФ-связывающих участков ДНК оказалось, что среди этих последовательностей нет стоп-кодонов.
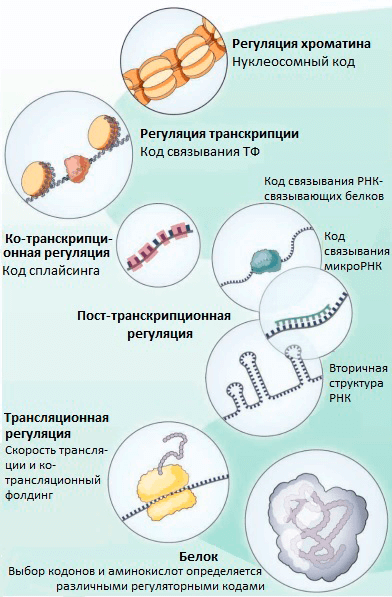
Рисунок 2. «Тайные коды» нашего генома, которые определяют частоту использования кодонов и выбор аминокислот в эволюции белков, независимо от выполнения белком его функций
Что же может обеспечить взаимовыгодное соседство «регуляторных» и генетического кодов? Одним из ключевых ограничений для белок-кодирующих генов является то, что последовательность гена должна обеспечивать нормальный фолдинг кодируемого белка. Мутации, нарушающие правильную укладку, с большой вероятностью будут отсеяны как вредные. Можно предположить, что когда необходимость правильного фолдинга отсутствует (например, в неструктурированных белках [12]), белок-кодирующая последовательность может содержать большее количество регуляторных элементов для различных «регуляторных кодов». Действительно ли это так, помогут узнать дальнейшие исследования.
Несмотря на то, что в работе Стаматояннопоулоса и его коллег было сделано много интересных наблюдений о функционировании «кода связывания ТФ», некоторые вопросы остаются открытыми. Например, авторы статьи отмечают, что ТФ гораздо реже связываются с генами с высокой экспрессией, но не ясно, как ТФ при связывании с белок-кодирующими участками ДНК могут воздействовать на транскрипцию этих генов. Возможно, что связывание ТФ в данном случае вызывает активацию альтернативного промотора или соседнего гена, снижая таким образом экспрессию гена с ТФ-связывающей последовательностью. С другой стороны, этот эффект может быть связан с перестройкой хроматина, которая приводит к снижению экспрессии ряда генов.
Новые исследования помогут ученым лучше понять, как различные «регуляторные коды» взаимодействуют друг с другом и с генетическим кодом. Интересно узнать, всегда ли природа могла найти оптимальное решение при сочетании разных кодов, или иногда возникали противоречия, приводящие к неоптимальным или вредным последствиям. Например, может оказаться, что белок-кодирующие последовательности ДНК, которым «трудно справиться» с обилием и разнообразием регуляторных элементов, активно используются патогенами при инфицировании хозяина. Обнаружение перекрывающихся «регуляторных кодов» в нашем геноме открывает новые перспективы для интерпретации различий и особенностей в последовательностях ДНК и указывает на то, что исследование генетического кода еще не подошло к концу.
Перевод редакционной колонки журнала Science [13].
Переписать код жизни: 12 важных вопросов о редактировании генома
Теперь у нас есть точный способ корректировать, заменять или даже удалять дефектные ДНК. Научный редактор The Guardian Ян Сэмпл объясняет научную сторону редактирования генома и риски, которые могут возникнуть в будущем.
Так что же такое редактирование генома?
Учёные сравнивают это с программами в компьютере, которые находят и заменяют ошибки в тексте. Только вместо исправления слов, редактор генома исправляет ДНК – биологический код, который является своеобразной «инструкцией» к живым организмам. С помощью редактирования генома исследователи могут деактивировать отдельные гены, корректировать вредоносные мутации и изменять активность специфичных генов у растений и животных – в том числе и у людей.
В чем смысл?
Энтузиазм вокруг темы редактирования генома объясняется возможностью лечить или предотвращать заболевания. Существуют тысячи генетических нарушений, которые передаются от поколения к поколению; многие из них – серьёзные и разрушительные. И они не редки: один ребёнок из двадцати пяти рождается с генетическим заболеванием. Среди самых распространённых – муковисцидоз (заболевание, которое характеризуется поражением желез внешней секреции – прим.), серповидноклеточная анемия (изменение строения белка гемоглобина, ведущее к тяжёлой форме анемии – прим.) и мышечная дистрофия.
Редактирование генома вселяет надежду на то, что эти болезни могут быть побеждены путём «переписывания» повреждённых генов в клетках пациента. Однако починка дефектных генов – это ещё не все возможности; уже есть опыт модифицирования иммунных клеток человека для борьбы с раком или для повышения их устойчивости к ВИЧ-инфекции. Также возможно исправление дефектных генов у человеческого эмбриона – таким образом можно предотвратить наследование серьёзных заболеваний. Но эта технология неоднозначна, так как генетические изменения могут распространиться на сперму или яйцеклетки пациента, то есть все внесённые генетические корректировки и любые побочные эффекты могут быть переданы следующим поколениям.
В каких ещё сферах применяется редактирование генома?
Некоторые отрасли медицины также воспользовались потенциалом новой технологии. Компании, работающие над производством антибиотиков нового поколения, разработали вирусы, которые сами по себе безопасны, но умеют находить и атаковать специфичные, вызывающие опасные инфекции штаммы бактерий. Также учёные используют редактор генома, чтобы обезопасить пересадку органов свиньи человеку. Помимо этого, редактирование генома повлияло на фундаментальные исследования, позволив учёным более точно понимать, как работают те или иные гены.
Так как это работает?
Есть множество способов редактировать гены, но настоящим прорывом в последние годы стал молекулярный инструмент Crispr-Cas9. Он использует особый участок бактериальной ДНК – CRISPR (буквально: короткие палиндромные повторы, регулярно расположенные группами) – чтобы найти специфическую область в генетическом коде организма, например, мутировавший ген. Эта область в дальнейшем отсекается с помощью фермента Cas9. В попытках восстановить повреждения клетка часто «отключает» этот ген. Этот способ очень полезен для работы с «вредоносными генами», но возможны и другие способы. Например, чтобы исправить дефектный ген, учёные могут разрезать мутировавшую ДНК и заменить здоровой цепочкой, которая доставляется вместе с молекулами Crispr-Cas9. Вместо Cas9 могут быть использованы другие ферменты, которые могут помочь редактировать ДНК более эффективно — например, Cpf1.
Напомните-ка, что такое гены?
Ген – это биологический шаблон, который организм использует для создания протеинов и ферментов, необходимых для построения и поддержания тканей и органов. Он представляет собой цепочку генетического кода, обозначаемого буквами G, C, T и A. У человека есть около 20 тысяч генов, сгруппированных в 23 пары хромосом, которые, в свою очередь, содержатся в ядре почти каждой клетки тела. Только около 1.5% нашего генетического кода, или генома, состоят из генов. Ещё 10% регулируют их, удостоверяясь, например, что гены включаются и выключаются в нужных клетках в нужное время. Остальная часть ДНК, судя по всему, бесполезна. «Бóльшая часть нашего генома не делает ничего, – говорит Джертон Лантер, генетик из Оксфордского Университета. – Это просто осколок эволюции».
Что за G, C, T и A?
Буквы генетического кода соответствуют молекулам гуанина (G), цитозина (С), тимина (Т) и аденина (А). В ДНК эти молекулы идут попарно: G и С, Т и А. Эти «основные пары» являются ступенями всем знакомой двойной спирали ДНК. Чтобы составить один ген, нужно много таких ступеней. Мутировавший ген, ответственный за муковисцидоз, содержит около 300.000 базовых пар, а за мышечную дистрофию – около 2,5 миллионов пар, это самый длинный ген в человеческом теле. Каждый из нас наследует от наших родителей около 60 новых мутаций, большинство – от отцов.
Но как добраться до нужных клеток?
Это весьма трудная задача. Большинство лекарств – это маленькие молекулы, которые могут путешествовать по телу с потоком крови, именно так они доставляются к органам и тканям. По сравнению с ними, молекулы, используемые в редакторе генома, огромны и доставить их к клеткам сложно. Но возможно. Один способ – добавить молекулы редактора генома в безвредные вирусы, которые инфицируют определённые типы клеток. Миллионы таких вирусов после этого вводятся в кровь или напрямую в поражённые ткани. Оказавшись в теле, вирусы вторгаются в необходимые клетки и высвобождают молекулы редактора генома, чтобы те делали свою работу. В 2017 году учёные из Техаса таким образом вылечили мышей от мышечной дистрофии Дюшена. Следующий шаг – клинические испытания на человеке.
Однако вирусы – не единственный способ доставить молекулы к клеткам. Исследователи использовали жировые наночастицы для переноса молекул Crispr-Cas9 к печени, а также короткие импульсы электричества, чтобы «открыть» поры эмбриона и через них ввести молекулы редактора генома.
Редактирование обязательно делать в самом организме?
Нет. Во время одного из самых первых испытаний редактора генома учёные забирали клетки из крови пациента, выполняли необходимые генетические корректировки и вводили исправленные клетки обратно. Такой метод выглядит многообещающим для лечения для людей, живущих с ВИЧ. Когда вирус попадает в организм, он инфицирует и убивает иммунные клетки. Но чтобы инфицировать иммунную клетку, ВИЧ сначала должен прицепиться к определённым белкам на её поверхности. Учёные выделили иммунные клетки из крови пациента и использовали редактор генома, чтобы вырезать ту ДНК, которая нужна клеткам для образования этих поверхностных белков. Без них ВИЧ не может получить доступ к клеткам.
Подобный способ может использоваться для борьбы с некоторыми типами рака: иммунные клетки выделяются из крови пациента и редактируются так, что они больше не могут синтезировать поверхностные белки, к которым цепляются раковые клетки. Отредактировав иммунные клетки и сделав из них «убийц рака», учёные размножают их и вводят обратно в организм пациента. Прелесть модифицирования клеток вне организма в том, что всё можно перепроверить до того, как вводить обратно, чтобы убедиться, что процесс редактирования проведён верно.
А что может пойти не так?
Современное редактирование генома довольно точное, но не идеальное. Процедура похожа на прицельную стрельбу – надо попасть по нужным клеткам, а по остальным – промахнуться. Даже если Crispr попадает куда нужно, изменения могут отличаться от клетки к клетке, например, в одной нужно исправить две копии мутировавшего гена, а в другой – только одну. Для некоторых генетических заболеваний это не столь важно, но становится проблемой, если заболевание возникает из-за единственного мутировавшего гена. Другая трудность возникает, когда изменения были произведены в неправильном участке генома. Таких «выстрелов не по мишени» может быть сотни, и они могут быть опасны, если разрушают здоровые гены или критически важные регуляторы ДНК.
Приведёт ли это всё к «редактированию» будущих детей?
Огромные усилия в медицине направлены на то, чтобы исправить дефектные гены у детей и взрослых. Но некоторые исследования показали, что есть возможность редактировать гены у эмбрионов. В 2017 году учёные, созванные Национальной Академией Наук и Национальной Академией Медицины США, сдержанно поддержали редактирование генома у человеческих эмбрионов для предотвращения самых серьёзных заболеваний, но только один такой опыт оказался безопасным.
Любые изменения на эмбриональной стадии повлияют на все клетки человека и будут переданы его детям, поэтому очень важно избегать вредоносных ошибок и побочных эффектов. Проектирование человеческих эмбрионов также поднимает вопрос непростой перспективы «дизайна» детей, когда эмбрионы редактируются больше по социальным, чем по медицинским причинам; например, чтобы сделать человека выше или умнее. Однако такие черты могут контролироваться тысячами генов, большинство из которых ещё неизвестны. Поэтому на данный момент перспектива редактирования генома будущего потомства весьма отдалённая.
Когда редактирование будет доступно простым пациентам?
Открытие клиникам доступа к редактированию генома – практически на финишной прямой. Около десятка испытаний Crispr-Cas9 запланированы или проводятся прямо сейчас. Большинство из них ведётся китайскими исследователями с целью борьбы с разными формами рака. Одно из первых исследований было запущено в 2016 году, когда учёные из провинции Сычуань вводили отредактированные иммунные клетки пациентам с поздней стадией рака лёгких. Большинство американских и европейских исследований ожидают своего начала в течение следующих нескольких лет.
Что дальше?
Базовое редактирование
Более мягкая форма редактирования генома – без разрезания ДНК на кусочки – использует химические реакции, чтобы изменить буквы генетического кода. Пока что это выглядит неплохо. В 2017 году исследователи в Китае использовали базовое редактирование для исправления мутаций, которые вызывают серьёзные нарушения кровеносной системы: как, например, гемолитическая анемия у человеческих эмбрионов.
Перемещение генов
Спроектированное перемещение генов может доставить определённые гены целым популяциям организмов. Например, таким образом можно сделать москитов бесплодными и сократить количество заболеваний, которые они распространяют. Но эта технология очень противоречива, так как может иметь широкомасштабные непреднамеренные экологические последствия.
Редактирование эпигенома
Иногда нет цели полностью удалить или заменить ген – необходимо просто ослабить или усилить его активность. Сейчас учёные работают над способностью Crispr выполнять такие задачи, предоставляя его молекулам больше возможностей, чем раньше.
Перевод: Кира Луппова.
Подписывайтесь на страницу СПИД.ЦЕНТРа в фейсбуке
ДНК и гены
ДНК ПРОКАРИОТ И ЭУКАРИОТ

Справа крупнейшая спираль ДНК человека, выстроенная из людей на пляже в Варне (Болгария), вошедшая в книгу рекордов Гиннесса 23 апреля 2016 года
Дезоксирибонуклеиновая кислота. Общие сведения
Дезоксирибонуклеи́новая кислота (ДНК) — макромолекула (одна из трёх основных, две другие — РНК и белки), обеспечивающая хранение, передачу из поколения в поколение и реализацию генетической программы развития и функционирования живых организмов. ДНК содержит информацию о структуре различных видов РНК и белков.
В клетках эукариот (животных, растений и грибов) ДНК находится в ядре клетки в составе хромосом, а также в некоторых клеточных органоидах (митохондриях и пластидах). В клетках прокариотических организмов (бактерий и архей) кольцевая или линейная молекула ДНК, так называемый нуклеоид, прикреплена изнутри к клеточной мембране. У них и у низших эукариот (например, дрожжей) встречаются также небольшие автономные, преимущественно кольцевые молекулы ДНК, называемые плазмидами.
С химической точки зрения ДНК — это длинная полимерная молекула, состоящая из повторяющихся блоков — нуклеотидов. Каждый нуклеотид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы. Связи между нуклеотидами в цепи образуются за счёт дезоксирибозы (С) и фосфатной (Ф) группы (фосфодиэфирные связи).

Рис. 2. Нуклертид состоит из азотистого основания, сахара (дезоксирибозы) и фосфатной группы
В подавляющем большинстве случаев (кроме некоторых вирусов, содержащих одноцепочечную ДНК) макромолекула ДНК состоит из двух цепей, ориентированных азотистыми основаниями друг к другу. Эта двухцепочечная молекула закручена по винтовой линии.
В ДНК встречается четыре вида азотистых оснований (аденин, гуанин, тимин и цитозин). Азотистые основания одной из цепей соединены с азотистыми основаниями другой цепи водородными связями согласно принципу комплементарности: аденин соединяется только с тимином (А-Т), гуанин — только с цитозином (Г-Ц). Именно эти пары и составляют «перекладины» винтовой «лестницы» ДНК (см.: рис. 2, 3 и 4).

Рис. 2. Азотистые основания
Последовательность нуклеотидов позволяет «кодировать» информацию о различных типах РНК, наиболее важными из которых являются информационные, или матричные (мРНК), рибосомальные (рРНК) и транспортные (тРНК). Все эти типы РНК синтезируются на матрице ДНК за счёт копирования последовательности ДНК в последовательность РНК, синтезируемой в процессе транскрипции, и принимают участие в биосинтезе белков (процессе трансляции). Помимо кодирующих последовательностей, ДНК клеток содержит последовательности, выполняющие регуляторные и структурные функции.

Рис. 3. Репликация ДНК
Расположение базовых комбинаций химических соединений ДНК и количественные соотношения между этими комбинациями обеспечивают кодирование наследственной информации.
Образование новой ДНК (репликация)
По завершении дупликации образуются две самостоятельные спирали, созданные из химических соединений родительской ДНК и имеющие с ней одинаковый генетический код. Таким путем ДНК способна перерывать информацию от клетки к клетке.
Более подробная информация:
СТРОЕНИЕ НУКЛЕИНОВЫХ КИСЛОТ

Дезоксирибонуклеиновая кислота (ДНК) относится к нуклеиновым кислотам. Нуклеиновые кислоты – это класс нерегулярных биополимеров, мономерами которых являются нуклеотиды.
НУКЛЕОТИДЫ состоят из азотистого основания, соединенного с пятиуглеродным углеводом (пентозой) – дезоксирибозой (в случае ДНК) или рибозой (в случае РНК), который соединяется с остатком фосфорной кислоты (H2PO3–).
Азотистые основания бывают двух типов: пиримидиновые основания – урацил (только в РНК), цитозин и тимин, пуриновые основания – аденин и гуанин.

Рис. 5. Структура нуклеотидов (слева), расположение нуклеотида в ДНК (снизу) и типы азотистых оснований (справа): пиримидиновые и пуриновые

Атомы углерода в молекуле пентозы нумеруются числами от 1 до 5. Фосфат соединяется с третьим и пятым атомами углерода. Так нуклеинотиды соединяются в цепь нуклеиновой кислоты. Таким образом, мы можем выделить 3’ и 5’-концы цепи ДНК:

Рис. 6. Выделение 3’ и 5’-концов цепи ДНК
Две цепи ДНК образуют двойную спираль. Эти цепи в спирали сориентированы в противоположных направлениях. В разных цепях ДНК азотистые основания соединены между собой с помощью водородных связей. Аденин всегда соединяется с тимином, а цитозин – с гуанином. Это называется правилом комплементарности (см. принцип комплементарности ).
Правило комплементарности:
| A–T G–C |
Например, если нам дана цепь ДНК, имеющая последовательность
3’– ATGTCCTAGCTGCTCG – 5’,
то вторая ей цепь будет комплементарна и направлена в противоположном направлении – от 5’-конца к 3’-концу:
5’– TACAGGATCGACGAGC– 3’.

Рис. 7. Направленность цепей молекулы ДНК и соединение азотистых оснований с помощью водородных связей
РЕПЛИКАЦИЯ ДНК
Репликация ДНК – это процесс удвоения молекулы ДНК путем матричного синтеза. В большинстве случаев естественной репликации ДНК праймером для синтеза ДНК является короткий фрагмент РНК (создаваемый заново). Такой рибонуклеотидный праймер создается ферментом праймазой (ДНК-праймаза у прокариот, ДНК-полимераза у эукариот), и впоследствии заменяется дезоксирибонуклеотидами полимеразой, выполняющей в норме функции репарации (исправления химических повреждений и разрывов в молекле ДНК).
Репликация происходит по полуконсервативному механизму. Это значит, что двойная спираль ДНК расплетается и на каждой из ее цепей по принципу комплементарности достраивается новая цепь. Дочерняя молекула ДНК, таким образом, содержит в себе одну цепь от материнской молекулы и одну вновь синтезированную. Репликация происходит в направлении от 3’ к 5’ концу материнской цепи.

Рис. 8. Репликация (удвоение) молекулы ДНК
ДНК-синтез – это не такой сложный процесс, как может показаться на первый взгляд. Если подумать, то для начала нужно разобраться, что же такое синтез. Это процесс объединения чего-либо в одно целое. Образование новой молекулы ДНК проходит в несколько этапов:

Рис. 9. Схематическое изображение процесса репликации ДНК: (1) Отстающая цепь (запаздывающая нить), (2) Ведущая цепь (лидирующая нить), (3) ДНК-полимераза α ( Polα ), (4) ДНК-лигаза, (5) РНК-праймер, (6) Праймаза, (7) Фрагмент Оказаки, (8) ДНК-полимераза δ ( Polδ ), (9) Хеликаза, (10) Однонитевые ДНК-связывающие белки, (11) Топоизомераза.
Далее описан синтез отстающей цепи дочерней ДНК (см. Схему репликативной вилки и функции ферментов репликации)
Нагляднее о репликации ДНК см. видео →
5) Непосредственно сразу после расплетания и стабилизации другой нити материнской молекулы к ней присоединяется ДНК-полимераза α (альфа) и в направлении 5’→3′ синтезирует праймер (РНК-затравку) – последовательность РНК на матрице ДНК длиной от 10 до 200 нуклеотидов. После этого фермент удаляется с нити ДНК.
СТРОЕНИЕ РНК
Рибонуклеиновая кислота (РНК) — одна из трёх основных макромолекул (две другие — ДНК и белки), которые содержатся в клетках всех живых организмов.
Последовательность нуклеотидов позволяет РНК кодировать генетическую информацию. Все клеточные организмы используют РНК (мРНК) для программирования синтеза белков.
Затем матричные РНК (мРНК) принимают участие в процессе, называемом трансляцией, т.е. синтеза белка на матрице мРНК при участии рибосом. Другие РНК после транскрипции подвергаются химическим модификациям, и после образования вторичной и третичной структур выполняют функции, зависящие от типа РНК.

Рис. 10. Отличие ДНК от РНК по азотистому основанию: вместо тимина (Т) в РНК представлен урацил (U), который также комплементарен аденину.
ТРАНСКРИПЦИЯ
Транскрипция – это процесс синтеза РНК на матрице ДНК. ДНК раскручивается на одном из участков. На одной из цепей содержится информация, которую необходимо скопировать на молекулу РНК – эта цепь называется кодирующей. Вторая цепь ДНК, комплементарная кодирующей, называется матричной. В процессе транскрипции на матричной цепи в направлении 3’ – 5’ (по цепи ДНК) синтезируется комплементарная ей цепь РНК. Таким образом, создается РНК-копия кодирующей цепи.
![]()
Рис. 11. Схематическое изображение транскрипции
Например, если нам дана последовательность кодирующей цепи
3’– ATGTCCTAGCTGCTCG – 5’,
то, по правилу комплементарности, матричная цепь будет нести последовательность
5’– TACAGGATCGACGAGC– 3’,
а синтезируемая с нее РНК – последовательность
3’– AUGUCCUAGCUGCUCG – 5’.
ТРАНСЛЯЦИЯ
Рассмотрим механизм синтеза белка на матрице РНК, а также генетический код и его свойства. Также для наглядности по ниже приведенной ссылке рекомендуем посмотреть небольшое видео о процессах транскрипции и трансляции, происходящих в живой клетке:


Рис. 12. Процесс синтеза белка: ДНК кодирует РНК, РНК кодирует белок
ГЕНЕТИЧЕСКИЙ КОД
Генетический код, общий для большинства про- и эукариот. В таблице приведены все 64 кодона и указаны соответствующие аминокислоты. Порядок оснований — от 5′ к 3′ концу мРНК.
Таблица 1. Стандартный генетический код
Среди триплетов есть 4 специальных последовательности, выполняющих функции «знаков препинания»:
Свойства генетического кода
1. Триплетность. Каждая аминокислота кодируется последовательностью из трех нуклеотидов – триплетом или кодоном.

2. Непрерывность. Между триплетами нет никаких дополнительных нуклеотидов, информация считывается непрерывно.

3. Неперекрываемость. Один нуклеотид не может входить одновременно в два триплета.

4. Однозначность. Один кодон может кодировать только одну аминокислоту.

5. Вырожденность. Одна аминокислота может кодироваться несколькими разными кодонами.

6. Универсальность. Генетический код одинаков для всех живых организмов.
Пример. Нам дана последовательность кодирующей цепи:
3’– CCGATTGCACGTCGATCGTATA– 5’.
Матричная цепь будет иметь последовательность:
5’– GGCTAACGTGCAGCTAGCATAT– 3’.
Теперь «синтезируем» с этой цепи информационную РНК:
3’– CCGAUUGCACGUCGAUCGUAUA– 5’.
Синтез белка идет в направлении 5’ → 3’, следовательно, нам нужно перевернуть последовательность, чтобы «прочитать» генетический код:
5’– AUAUGCUAGCUGCACGUUAGCC– 3’.
Теперь найдем старт-кодон AUG:
5’– AU AUG CUAGCUGCACGUUAGCC– 3’.
Разделим последовательность на триплеты:

Найдем стоп-кодон и согласно таблице генетического кода запишем последовательность аминокислот:

Центральная догма молекулярной биологии звучит следующим образом: информация с ДНК передается на РНК (транскрипция), с РНК – на белок (трансляция). ДНК также может удваиваться путем репликации, и также возможен процесс обратной транскрипции, когда по матрице РНК синтезируется ДНК, но такой процесс в основном характерен для вирусов.

Рис. 13. Центральная догма молекулярной биологии
ГЕНОМ: ГЕНЫ и ХРОМОСОМЫ
Термин «геном» был предложен Г. Винклером в 1920 г. для описания совокупности генов, заключенных в гаплоидном наборе хромосом организмов одного биологического вида. Первоначальный смысл этого термина указывал на то, что понятие генома в отличие от генотипа является генетической характеристикой вида в целом, а не отдельной особи. С развитием молекулярной генетики значение данного термина изменилось. Известно, что ДНК, которая является носителем генетической информации у большинства организмов и, следовательно, составляет основу генома, включает в себя не только гены в современном смысле этого слова. Большая часть ДНК эукариотических клеток представлена некодирующими («избыточными») последовательностями нуклеотидов, которые не заключают в себе информации о белках и нуклеиновых кислотах. Таким образом, основную часть генома любого организма составляет вся ДНК его гаплоидного набора хромосом.
Гены — это участки молекул ДНК, кодирующие полипептиды и молекулы РНК
За последнее столетие наше представление о генах существенно изменилось. Ранее геном называли участок хромосомы, кодирующий или определяющий один признак или фенотипическое (видимое) свойство, например цвет глаз.

В 1940 г. Джордж Бидл и Эдвард Тейтем предложили молекулярное определение гена. Ученые обрабатывали споры гриба Neurospora crassa рентгеновским излучением и другими агентами, вызывающими изменения в последовательности ДНК (мутации), и обнаружили мутантные штаммы гриба, утратившие некоторые специфические ферменты, что в некоторых случаях приводило к нарушению целого метаболического пути. Бидл и Тейтем пришли к выводу, что ген — это участок генетического материала, который определяет или кодирует один фермент. Так появилась гипотеза «один ген — один фермент». Позднее эта концепция была расширена до определения «один ген — один полипептид», поскольку многие гены кодируют белки, не являющиеся ферментами, а полипептид может оказаться субъединицей сложного белкового комплекса.
Современное биохимическое определение гена еще более конкретно. Генами называются все участки ДНК, кодирующие первичную последовательность конечных продуктов, к которым относятся полипептиды или РНК, обладающие структурной или каталитической функцией.
Наряду с генами ДНК содержит и другие последовательности, выполняющие исключительно регуляторную функцию. Регуляторные последовательности могут обозначать начало или конец генов, влиять на транскрипцию или указывать место инициации репликации или рекомбинации. Некоторые гены могут экспрессироваться разными путями, при этом один и тот же участок ДНК служит матрицей для образования разных продуктов.
Мы можем приблизительно рассчитать минимальный размер гена, кодирующего средний белок. Каждая аминокислота в полипептидной цепи кодируется последовательностью из трех нуклеотидов; последовательности этих триплетов (кодонов) соответствуют цепочке аминокислот в полипептиде, который кодируется данным геном. Полипептидная цепь из 350 аминокислотных остатков (цепь средней длины) соответствует последовательности из 1050 п.н. (пар нуклеотидов). Однако многие гены эукариот и некоторые гены прокариот прерываются сегментами ДНК, не несущими информации о белке, и поэтому оказываются значительно длиннее, чем показывает простой расчет.
Сколько генов в одной хромосоме?
ДНК прокариот устроена более просто: их клетки не имеют ядра, поэтому ДНК находится непосредственно в цитоплазме в форме нуклеоида.
 Как известно, бактериальные клетки имеют хромосому в виде нити ДНК, уложенной в компактную структуру – нуклеоид. Хромосома прокариота Escherichia coli, чей геном полностью расшифрован, представляет собой кольцевую молекулу ДНК (на самом деле, это не правильный круг, а скорее петля без начала и конца), состоящую из 4 639 675 п.н. В этой последовательности содержится примерно 4300 генов белков и еще 157 генов стабильных молекул РНК. В геноме человека примерно 3,1 млрд пар нуклеотидов, соответствующих почти 29 000 генам, расположенным на 24 разных хромосомах.
Как известно, бактериальные клетки имеют хромосому в виде нити ДНК, уложенной в компактную структуру – нуклеоид. Хромосома прокариота Escherichia coli, чей геном полностью расшифрован, представляет собой кольцевую молекулу ДНК (на самом деле, это не правильный круг, а скорее петля без начала и конца), состоящую из 4 639 675 п.н. В этой последовательности содержится примерно 4300 генов белков и еще 157 генов стабильных молекул РНК. В геноме человека примерно 3,1 млрд пар нуклеотидов, соответствующих почти 29 000 генам, расположенным на 24 разных хромосомах.
Прокариоты (Бактерии).
 Бактерия E. coli имеет одну двухцепочечную кольцевую молекулу ДНК. Она состоит из 4 639 675 п.н. и достигает в длину примерно 1,7 мм, что превышает длину самой клетки E. coli приблизительно в 850 раз. Помимо крупной кольцевой хромосомы в составе нуклеоида многие бактерии содержат одну или несколько маленьких кольцевых молекул ДНК, свободно располагающихся в цитозоле. Такие внехромосомные элементы называют плазмидами (рис. 16).
Бактерия E. coli имеет одну двухцепочечную кольцевую молекулу ДНК. Она состоит из 4 639 675 п.н. и достигает в длину примерно 1,7 мм, что превышает длину самой клетки E. coli приблизительно в 850 раз. Помимо крупной кольцевой хромосомы в составе нуклеоида многие бактерии содержат одну или несколько маленьких кольцевых молекул ДНК, свободно располагающихся в цитозоле. Такие внехромосомные элементы называют плазмидами (рис. 16).
Большинство плазмид состоит всего из нескольких тысяч пар нуклеотидов, некоторые содержат более 10000 п. н. Они несут генетическую информацию и реплицируются с образованием дочерних плазмид, которые попадают в дочерние клетки в процессе деления родительской клетки. Плазмиды обнаружены не только в бактериях, но также в дрожжах и других грибах. Во многих случаях плазмиды не дают никаких преимуществ клеткам-хозяевам, и их единственная задача — независимое воспроизведение. Однако некоторые плазмиды несут полезные для хозяина гены. Например, содержащиеся в плазмидах гены могут придавать клеткам бактерий устойчивость к антибактериальным агентам. Плазмиды, несущие ген β-лактамазы, обеспечивают устойчивость к β-лактамным антибиотикам, таким как пенициллин и амоксициллин. Плазмиды могут переходить от клеток, устойчивых к антибиотикам, к другим клеткам того же или другого вида бактерий, в результате чего эти клетки также становятся резистентными. Интенсивное применение антибиотиков является мощным селективным фактором, способствующим распространению плазмид, кодирующих устойчивость к антибиотикам (а также транспозонов, которые кодируют аналогичные гены) среди болезнетворных бактерий, и приводит к появлению бактериальных штаммов с устойчивостью к нескольким антибиотикам. Врачи начинают понимать опасность широкого использования антибиотиков и назначают их только в случае острой необходимости. По аналогичным причинам ограничивается широкое использование антибиотиков для лечения сельскохозяйственных животных.
Эукариоты.
Таблица 2. ДНК, гены и хромосомы некоторых организмов



