Нужны ли графические ядра Nvidia CUDA для игр?

Ядра CUDA являются эквивалентом процессорных ядер Nvidia. Они оптимизированы для одновременного выполнения большого количества вычислений, что очень важно для современной графики. Естественно, на графические настройки больше всего повлияло количество ядер CUDA в видеокарте, и они требуют больше всего от графического процессора, то есть теней и освещения, среди прочего.
CUDA долгое время была одной из самых выдающихся записей в спецификациях любой видеокарты GeForce. Однако не все до конца понимают, что такое ядра CUDA и что конкретно они означают для игр.
В этой статье дан краткий и простой ответ на этот вопрос. Кроме того, мы кратко рассмотрим некоторые другие связанные вопросы, которые могут возникнуть у некоторых пользователей.
Что такое ядра видеокарты CUDA?
CUDA является аббревиатурой от одной из запатентованных технологий Nvidia: Compute Unified Device Architecture. Его цель? Эффективные параллельные вычисления.
Одиночное ядро CUDA аналогично ядру ЦП, основное отличие в том, что оно менее изощренное, но реализовано в большем количестве. Обычный игровой процессор имеет от 2 до 16 ядер, но количество ядер CUDA исчисляется сотнями, даже в самых низких современных видеокартах Nvidia GeForce. Между тем, у высококлассных карт сейчас их тысячи.
Что делают ядра CUDA в играх?
Обработка графики требует одновременного выполнения множества сложных вычислений, поэтому такое огромное количество ядер CUDA реализовано в видеокартах. И учитывая, как графические процессоры разрабатываются и оптимизируются специально для этой цели, их ядра могут быть намного меньше, чем у гораздо более универсального CPU.
И как ядра CUDA влияют на производительность в игре?
По сути, любые графические настройки, которые требуют одновременного выполнения вычислений, значительно выиграют от большего количества ядер CUDA. Наиболее очевидными из них считается освещение и тени, но также включены физика, а также некоторые типы сглаживания и окклюзии окружающей среды.
Ядра CUDA или потоковые процессоры?
Там, где у Nvidia GeForce есть ядра CUDA, у их основного конкурента AMD Radeon есть потоковые процессоры.
Ядра CUDA лучше оптимизированы, поскольку аппаратное обеспечение Nvidia обычно сравнивают с AMD, но нет никаких явных различий в производительности или качестве графики, о которых вам следует беспокоиться, если вы разрываетесь между приобретением Nvidia или AMD GPU.
Сколько ядер CUDA вам нужно?
И вот сложный вопрос. Как часто бывает с бумажными спецификациями, они просто не являются хорошим индикатором того, какую производительность вы можете ожидать от аппаратного обеспечения.
Многие другие спецификации, такие как пропускная способность VRAM, более важны для рассмотрения, чем количество ядер CUDA, а также вопрос оптимизации программного обеспечения.
Для общего представления о том, насколько мощен графический процессор, мы рекомендуем проверить UserBenchmark. Однако, если вы хотите увидеть детальное и всестороннее тестирование, есть несколько надежных сайтов, таких как GamersNexus, TrustedReviews, Tom’s Hardware, AnandTech и ряд других.
Вывод
Надеемся, что это помогло пролить некоторый свет на то, чем на самом деле являются ядра CUDA, что они делают и насколько они важны. Прежде всего, мы надеемся, что помогли развеять любые ваши заблуждения по этому поводу.
CUDA: Как работает GPU
Внутренняя модель nVidia GPU – ключевой момент в понимании GPGPU с использованием CUDA. В этот раз я постараюсь наиболее детально рассказать о программном устройстве GPUs. Я расскажу о ключевых моментах компилятора CUDA, интерфейсе CUDA runtime API, ну, и в заключение, приведу пример использования CUDA для несложных математических вычислений.
Вычислительная модель GPU:
При использовании GPU вы можете задействовать грид необходимого размера и сконфигурировать блоки под нужды вашей задачи.
CUDA и язык C:
Дополнительные типы переменных и их спецификаторы будут рассмотрены непосредственно в примерах работы с памятью.
CUDA host API:
Перед тем, как приступить к непосредственному использованию CUDA для вычислений, необходимо ознакомиться с так называемым CUDA host API, который является связующим звеном между CPU и GPU. CUDA host API в свою очередь можно разделить на низкоуровневое API под названием CUDA driver API, который предоставляет доступ к драйверу пользовательского режима CUDA, и высокоуровневое API – CUDA runtime API. В своих примерах я буду использовать CUDA runtime API.
Понимаем работу GPU:
Как было сказано, нить – непосредственный исполнитель вычислений. Каким же тогда образом происходит распараллеливание вычислений между нитями? Рассмотрим работу отдельно взятого блока.
Задача. Требуется вычислить сумму двух векторов размерностью N элементов.
Нам известна максимальные размеры нашего блока: 512*512*64 нитей. Так как вектор у нас одномерный, то пока ограничимся использованием x-измерения нашего блока, то есть задействуем только одну полосу нитей из блока (рис. 3). 
Рис. 3. Наша полоса нитей из используемого блока.
Заметим, что x-размерность блока 512, то есть, мы можем сложить за один раз векторы, длина которых N // Функция сложения двух векторов
__global__ void addVector( float * left, float * right, float * result)
<
//Получаем id текущей нити.
int idx = threadIdx.x;
Таким образом, распараллеливание будет выполнено автоматически при запуске ядра. В этой функции так же используется встроенная переменная threadIdx и её поле x, которая позволяет задать соответствие между расчетом элемента вектора и нитью в блоке. Делаем расчет каждого элемента вектора в отдельной нити.
Пишем код, которые отвечает за 1 и 2 пункт в программе:
#define SIZE 512
__host__ int main()
<
//Выделяем память под вектора
float * vec1 = new float [SIZE];
float * vec2 = new float [SIZE];
float * vec3 = new float [SIZE];
//Инициализируем значения векторов
for ( int i = 0; i //Указатели на память видеокарте
float * devVec1;
float * devVec2;
float * devVec3;
…
dim3 gridSize = dim3(1, 1, 1); //Размер используемого грида
dim3 blockSize = dim3(SIZE, 1, 1); //Размер используемого блока
Теперь нам остаеться скопировать результат расчета из видеопамяти в память хоста. Но у функций ядра при этом есть особенность – асинхронное исполнение, то есть, если после вызова ядра начал работать следующий участок кода, то это ещё не значит, что GPU выполнил расчеты. Для завершения работы заданной функции ядра необходимо использовать средства синхронизации, например event’ы. Поэтому, перед копированием результатов на хост выполняем синхронизацию нитей GPU через event.
Код после вызова ядра:
//Выполняем вызов функции ядра
addVector >>(devVec1, devVec2, devVec3);
//Хендл event’а
cudaEvent_t syncEvent;
cudaEventCreate(&syncEvent); //Создаем event
cudaEventRecord(syncEvent, 0); //Записываем event
cudaEventSynchronize(syncEvent); //Синхронизируем event
Рассмотрим более подробно функции из Event Managment API.
Рис. 4. Синхронизация работы основоной и GPU прграмм.
На рисунке 4 блок «Ожидание прохождения Event’а» и есть вызов функции cudaEventSynchronize.
Ну и в заключении выводим результат на экран и чистим выделенные ресурсы.
cudaFree(devVec1);
cudaFree(devVec2);
cudaFree(devVec3);
Думаю, что описывать функции высвобождения ресурсов нет необходимости. Разве что, можно напомнить, что они так же возвращают значения cudaError_t, если есть необходимость проверки их работы.
Заключение
Надеюсь, что этот материал поможет вам понять, как функционирует GPU. Я описал самые главные моменты, которые необходимо знать для работы с CUDA. Попробуйте сами написать сложение двух матриц, но не забывайте об аппаратных ограничениях видеокарты.
О технологии многопотоковых вычислений CUDA в видеокартах компании Nvidia
Видеокарты производства компании Nvidia пользуются заслуженной славой в области проведения надежных высокопроизводительных вычислений. Благодаря наличию аппаратных возможностей технологии CUDA, «зеленые карты» показывают отличные результаты и при майнинге на большинстве алгоритмов консенсуса PoW.
Рассмотрим подробнее некоторые особенности CUDA.
Что такое технология CUDA?
CUDA (Compute Unified Device Architecture) — это технология многопотоковых компьютерных вычислений, созданная компанией NVIDIA. Она позволяет значительно увеличить производительность при проведении сложных расчетов за счет распараллеливания на множестве вычислительных ядер.
Приложения CUDA используются для обработки видео и аудио, моделирования физических эффектов, в процессе разведки месторождений нефти и газа, проектировании различных изделий, медицинской визуализации и научных исследованиях, в разработке вакцин от болезней, в том числе COVID-19, физическом моделировании и других областях.
CUDA ™ — это архитектура параллельных вычислений общего назначения, которая позволяет решать сложные вычислительные задачи с помощью GPU. CUDA поддерживает операционные системы Linux и Windows. Чем больше ядер CUDA имеет видеокарта и чем больше частота их работы, тем большую производительность она может обеспечить.
Каждая дополнительна единица вычислительной мощности требует соответствующего количества потребленной электроэнергии. Чем меньший технологический процесс используется при производстве вычислительных ядер, тем меньшие напряжения используются для их питания и, соответственно снижается потребление. Поэтому, даже если видеокарты разных поколений имеют одинаковую теоретическую вычислительную мощность в TFlops, их эффективность кардинально отличается по КПД, в значительной мере зависящему от потребления полупроводниковых элементов, из которых состоят ядра видеопроцессоров.

Архитектура CUDA упрощенно включает набор исполняемых команд и аппаратный механизм проведения параллельных вычислений внутри графического процессора. Разработчики программного обеспечения, в том числе майнеров, для работы с CUDA обычно используют языки программирования высокого уровня (C, Фортран). В будущем в CUDA планируется добавление полноценной поддержки C ++, Java и Python. Продвинутые программисты дополнительно улучшают эффективность майнеров с помощью оптимизации кода майнеров на языке более низкого (машинного) уровня – Ассемблере. В качестве примера в этом контексте можно привести Клеймор дуал майнер, который показывает высочайшую эффективность на зеленых видеокартах.
В технологии CUDA есть три важных элемента: библиотеки разработчика, среда выполнения и драйвера. Все они прямо влияют на производительность и надежность работы приложений.
Драйвер — это уровень абстракции устройств с поддержкой CUDA, который обеспечивает интерфейс доступа для аппаратных устройств. С помощью среды выполнения через этот уровень реализуется выполнение различных функций по проведению сложных вычислений.
Таблица версий CUDA, поддерживающихся в драйверах NVIDIA разных версий:
| Версия CUDA | Linux x86_64 | Windows x86_64 |
|---|---|---|
| CUDA 11.1 | >=455.23 | >=456.38 |
| CUDA 11.0.3 Update 1 | >= 450.51.06 | >= 451.82 |
| CUDA 11.0.2 GA | >= 450.51.05 | >= 451.48 |
| CUDA 11.0.1 RC | >= 450.36.06 | >= 451.22 |
| CUDA 10.2.89 | >= 440.33 | >= 441.22 |
| CUDA 10.1 (10.1.105) | >= 418.39 | >= 418.96 |
| CUDA 10.0.130 | >= 410.48 | >= 411.31 |
| CUDA 9.2 (9.2.148 Update 1) | >= 396.37 | >= 398.26 |
| CUDA 9.2 (9.2.88) | >= 396.26 | >= 397.44 |
| CUDA 9.1 (9.1.85) | >= 390.46 | >= 391.29 |
| CUDA 9.0 (9.0.76) | >= 384.81 | >= 385.54 |
| CUDA 8.0 (8.0.61 GA2) | >= 375.26 | >= 376.51 |
| CUDA 8.0 (8.0.44) | >= 367.48 | >= 369.30 |
| CUDA 7.5 (7.5.16) | >= 352.31 | >= 353.66 |
| CUDA 7.0 (7.0.28) | >= 346.46 | >= 347.62 |
Для CUDA 6.5 нужны драйвера 340.0+, для CUDA 6.0 — 331.00, для CUDA 5.5 — не ниже 319.00.
При установке новых драйверов на видеокарты со старой версией compute capability вычисления производиться не будут.
Например, на большинство видеокарт с архитектурой Kepler (GeForce 640 — 780Ti, 910M, GTX TITAN, compute capability 3.5) нет смысла ставить драйвера новее 441.22 (Windows) или 440.33 (Linux), так как в них отсутствует поддержка compute capability 3.x.
Информация, которую нужно учитывать при установке драйверов для видеокарт Nvidia на предмет соответствия версии compute capability CUDA:
Библиотеки разработки (CUDA SDK) на практике реализуют выполнение математических операций и крупномасштабных задач параллельных вычислений.

Среда выполнения CUDA — это интерфейс разработчика плюс компоненты выполнения программного кода. Она определяет основные типы данных и функций для проведения вычислений, преобразований, управления памятью, позволяет реализовать доступ к устройствам и спланировать выполнение команд.
Программный код CUDA на практике обычно состоит из двух частей, одна из которых выполняется на CPU, а другая на GPU.
Ядро CUDA имеет три важных абстрактных понятия:
которые могут быть достаточно легко представлены и использованы на языке программирования Си.
Программный стек CUDA состоит из нескольких уровней, аппаратного драйвера, интерфейса прикладного программирования (API) и среды его выполнения, а также двух расширенных математических библиотек общего назначения, CUFFT и CUBLAS.
Теоретически каждое новое поколение CUDA должно демонстрировать более высокую производительность за счет устранения выявленных ошибок, оптимизации кода, добавления новых алгоритмов и прочих новшеств. К сожалению, на практике это не всегда соответствует реалиям. В особенности это связано с постоянным ростом аппетита программ по отношению аппаратным ресурсам. Это касается не только программных пакетов CUDA, но затрагивает даже такие, казалось бы, независимые операционные системы, как Linux.
Влияет ли на хешрейт версия CUDA, установленная на компьютере?
Практические опыты с майнерами на разных версиях CUDA показывают, что новые версии особого прироста в хешрейте не дают.
Использование новых драйверов Nvidia обычно сопряжено с увеличением требований к аппаратному обеспечению и часто влечет рост потребления видеопамяти, что не всегда положительно сказываются на производительности видеокарт при майнинге.
Это особенно проявляется в быстродействии и потреблении видеопамяти при майнинге на алгоритме Ethash/DaggerHashimoto. Как правило, старые версии драйверов потребляют меньше видеопамяти при одинаковой производительности на Ethash.
Для обычных пользователей нет необходимости заботиться о версии CUDA, если только этого не требуют последние версии майнеров с новыми поддерживающимися алгоритмами.
Тем не менее, нужно учитывать, что технология CUDA постоянно совершенствуется, в нее добавляются новые возможности, которые требуют адаптации программ-майнеров. Поэтому современные майнеры иногда имеют разные версии, которые поддерживают работу с разными версиями CUDA 8.0, 9.1/9.2, а также 10.0, 10.1 и 10.2.
FAQ по видеокартам GeForce: что следует знать о графических картах?
Страница 4: GPU
Что скрывается за потоковым процессором, блоком шейдеров или ядром CUDA?
Потоковый процессор обрабатывает непрерывный поток данных, которых насчитываются многие сотни, причем они выполняются параллельно на множестве потоковых процессоров. Современные GPU оснащаются несколькими тысячами потоковых процессоров, они отлично подходят для задач с высокой степенью параллельности. Это и рендеринг графики, и научные расчеты. Что, кстати, позволило GPU закрепиться в серверном сегменте в качестве вычислительных ускорителей.

Еще одним шагом дальше можно назвать интеграцию ядер Tensor в архитектуру NVIDIA Ampere, которые способны эффективно вычислять менее сложные числа INT8 и INT4, но об этом мы поговорим чуть позже.
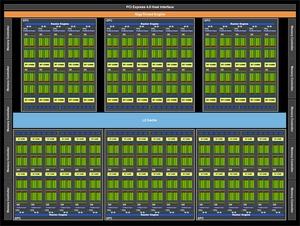
В составе GPU GA102 имеются семь кластеров Graphics Processing Clusters (GPC) с 12 потоковыми мультипроцессорами Streaming Multiprocessors (SM) каждый. Но на видеокартах GeForce RTX 3090 и GeForce RTX 3080 активны не все SM. GA102 GPU теоретически содержит 10.752 блоков FP32 (7 GPC x 12 SM x 128 блоков FP32). Но у GeForce RTX 3090 два SM отключены, поэтому видеокарта предлагает «всего» 10.496 блоков FP32. Такой подход повышает выход годных чипов NVIDIA, поскольку наличие одного-двух дефектных SM не приводит к отбраковке кристалла.
В случае GeForce RTX 3080 один кластер GPC полностью отключен, поэтому на GA102 GPU остаются шесть GPC, но только четыре из них содержат полные 12 SM, два ограничены десятью SM. Что дает в сумме 8.704 блока FP32 в составе 68 SM.
NVIDIA масштабирует архитектуру Ampere с видеокарты GeForce RTX 3060 вплоть до GeForce RTX 3090. Ниже представлен обзор видеокарт GeForce RTX 30:
| GeForce RTX 3090 | GeForce RTX 3080 Ti | GeForce RTX 3080 | GeForce RTX 3070 Ti | |
| GPU | Ampere (GA102) | Ampere (GA102) | Ampere (GA102) | Ampere (GA104) |
| Число транзисторов | 28 млрд. | 28 млрд. | 28 млрд. | 17,4 млрд. |
| Техпроцесс | 8 нм | 8 нм | 8 нм | 8 нм |
| Площадь кристалла | 628,4 мм² | 628,4 мм² | 628,4 мм² | 392,5 мм² |
| Число FP32 ALU | 10.496 | 10.240 | 8.704 | 6.144 |
| Число INT32 ALU | 5.248 | 5.120 | 4.352 | 3.072 |
| Число SM | 82 | 80 | 68 | 48 |
| Ядра Tensor | 328 | 320 | 272 | 192 |
| Ядра RT | 82 | 80 | 68 | 48 |
| Базовая частота | 1.400 МГц | 1.365 МГц | 1.440 МГц | 1.580 МГц |
| Частота Boost | 1.700 МГц | 1.665 МГц | 1.710 МГц | 1.770 МГц |
| Емкость памяти | 24 GB | 12 GB | 10 GB | 8 GB |
| Тип памяти | GDDR6X | GDDR6X | GDDR6X | GDDR6X |
| Частота памяти | 1.219 МГц | 1.188 МГц | 1.188 МГц | 1.188 МГц |
| Ширина шины памяти | 384 бит | 384 бит | 320 бит | 256 бит |
| Пропускная способность памяти | 936 Гбайт/с | 912 Гбайт/с | 760 Гбайт/с | 608 Гбайт/с |
| TDP | 350 Вт | 350 Вт | 320 Вт | 290 Вт |
| GeForce RTX 3070 | GeForce RTX 3060 Ti | GeForce RTX 3060 | |
| GPU | Ampere (GA104) | Ampere (GA104) | Ampere (GA106) |
| Число транзисторов | 17,4 млрд. | 17,4 млрд. | 12 млрд. |
| Техпроцесс | 8 нм | 8 нм | 8 нм |
| Площадь кристалла | 392,5 мм² | 392,5 мм² | 276 мм² |
| Число FP32 ALU | 5.888 | 4.864 | 3.584 |
| Число INT32 ALU | 2.944 | 2.432 | 1.792 |
| Число SM | 46 | 38 | 28 |
| Ядра Tensor | 184 | 152 | 112 |
| Ядра RT | 46 | 38 | 28 |
| Базовая частота | 1.500 МГц | 1.410 МГц | 1.320 МГц |
| Частота Boost | 1.730 МГц | 1.665 МГц | 1.780 МГц |
| Емкость памяти | 8 GB | 8 GB | 12 GB |
| Тип памяти | GDDR6 | GDDR6 | GDDR6 |
| Частота памяти | 1.725 МГц | 1.750 МГц | 1.875 МГц |
| Ширина шины памяти | 256 бит | 256 бит | 192 бит |
| Пропускная способность памяти | 448 Гбайт/с | 448 Гбайт/с | 360 Гбайт/с |
| TDP | 220 Вт | 200 Вт | 170 Вт |
Одновременное выполнение операций с целыми числами и числами с плавающей запятой
Как мы уже упоминали, вычислительные блоки FP32 могут работать в режиме 2x FP16, то же самое касается INT16. Чтобы увеличить вычислительную производительность и сделать ее более гибкой, в архитектуре NVIDIA Turing появилась возможность одновременного расчета чисел с плавающей запятой и целых чисел. Конечно, подобная возможность сохранилась и в архитектуре Ampere. NVIDIA проанализировала данные вычисления в конвейере рендеринга в десятках игр, обнаружив, что на каждые 100 расчетов FP выполняется примерно треть вычислений INT. Впрочем, значение среднее, на практике оно меняется от 20% до 50%. Конечно, если вычисления FP и INT будут выполняться одновременно, то конвейеру придется иногда «подтормаживать» в случае взаимных связей.

Соотношение 1/3 INT32 и 2/3 FP32 отражено в структуре Ampere Streaming Multiprocessor (SM), составляющем элементе архитектуры Ampere. NVIDIA удвоила число вычислительных блоков FP32 на каждый SM. Вместо 64 блоков FP32 на SM, их теперь насчитывается 128. Плюс 64 блока INT32. Теперь на квадрант SM насчитывается два пути данных, некоторые могут работать параллельно. Один из путей данных содержит 16 блоков FP32, то есть может выполнять 16 вычислений FP32 за такт. Второй путь данных содержит по 16 блоков FP32 и INT32. Каждый из квадрантов SM может выполнять либо 32 операции FP32, либо по 16 операций FP32 и INT32 за такт. Если же брать SM целиком, то возможно выполнение 128 операций FP32 или по 64 операции FP32 и INT32 за такт.
Параллельное выполнение продолжается и на других блоках. Например, ядра RT и Tensor могут работать параллельно в конвейере рендеринга, что снижает время, требующееся на рендеринг кадра.
Под термином «потоковые процессоры» сегодня подразумевают количество вычислительных блоков GPU, хотя следует помнить, что сложность вычислений бывает разной. Поэтому термин используется гибко, но обычно все равно описывает вычислительные блоки.
Текстурные блоки
Действительно, для рендеринга объекта простых текстур уже недостаточно, использование нескольких слоев позволяет, например, получить 3D-эффект вместо плоской текстуры. Раньше объекты приходилось рассчитывать на конвейере несколько раз, и каждый проход текстурный блок накладывал текстуру, сегодня достаточно одного процесса рендеринга, текстурный блок может получать данные объекта для многократной обработки из буфера.
Контроллер памяти
Помимо изменений в SM, новая архитектура NVIDIA получила оптимизированную структуру конвейеров растровых операций (ROP), а также соединения ROP и контроллера памяти. До поколения Turing ROP всегда подключались к интерфейсу памяти. И на каждый 32-битный контроллер памяти приходилось восемь ROP. Если число контроллеров памяти и ширина шины менялись, то же самое касалось и ROP. В архитектуре Ampere ROP перенесены в GPC. Используются два раздела ROP на GPC, каждый раздел содержит восемь ROP.
Что дает иную формулу вычисления ROP на GeForce RTX 3080. Шесть GPC с 2x 8 ROP на каждом дают 96 ROP. У GeForce RTX 3090 работают семь GPC с 2x 8 ROP, что дает 112 ROP. NVIDIA намеренно интегрировала ROP глубже, чтобы задняя часть конвейера рендеринга меньше зависела от интерфейса памяти. Например, видеокарта GeForce RTX 3080 использует 320-битный интерфейс памяти, но содержит 96 ROP, а не 80 ROP.
Интерфейс памяти разделен на 32-битные блоки. В зависимости от желаемой ширины интерфейса памяти или емкости, их можно набирать в произвольном количестве.
Ядра Tensor и RT
Ядра Tensor третьего поколения
С архитектурой Turing NVIDIA представила два новых вычислительных блока, ранее на GPU не использовавшихся. Конечно, ядра Tensor знакомы нам по архитектуре Volta, но там они использовались для научных расчетов. В случае GPU Ampere ядра Tensor перешли уже на третье поколение.
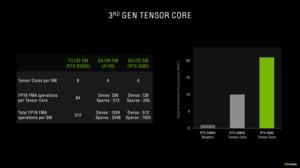
Ядра Tensor ранее использовались только для вычислений INT16 и FP16, но в третьем поколении они могут работать с FP32 и FP64. Что особенно важно для сегмента HPC с высокой точностью. Для игровых GPU GeForce намного важнее меньшая точность.
Ядра Tensor архитектуры Turing могут выполнять 64 операции FP16 Fused Multiply-Add (FMA) каждое. В случае Ampere число операций увеличено до 128 у GA102 GPU и до 256 у GA100 GPU с плотными матрицами. Если же используются разреженные матрицы, число операций FMA FP16 увеличивается до 256 у GA102 GPU и до 512 у GA100 GPU. Ядра Tensor архитектуры Turing разреженные матрицы не поддерживают.
Ядра RT второго поколения
Все они опираются на тот принцип, что удаленные от луча примитивы не могут с ним пересекаться. Следовательно, и смысла их просчитывать нет. Число лучей на сценах растет экспоненциально, поэтому на каждый луч следует обрабатывать как можно меньшее число примитивов, чтобы не увеличивать вычислительную нагрузку.
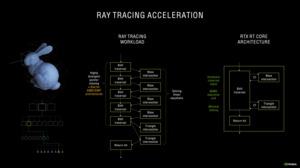
Поскольку NVIDIA не изменила число ядер RT на SM в архитектуре Ampere, количество блоков SM на GPU по-прежнему определяет производительность RT. Но в ядрах RT есть другие оптимизации.
Одна из проблем с расчетом пересечений при трассировке лучей связана с движущимися объектами, особенно если используется эффект размытия движения (motion blur). Для ядер RT в архитектуре Turing такой сценарий является «узким местом». Но второе поколение ядер RT уже лучше справляется с интерполяцией эффекта размытия движения. Пересечения просчитываются с упреждением, в итоге трассировка лучей рассчитываются только для тех областей, где она необходима.
Кэши L1 и L2
Между функциональными блоками (потоковые процессоры, ядра RT и Tensor) и видеопамятью располагаются еще два уровня хранения данных, без которых GPU не смог бы выдавать высокий уровень производительности. Цель этих кэшей заключается в том, чтобы хранить информацию как можно ближе к функциональным блокам. Данные передаются из видеопамяти сначала в кэш L2, а затем и в кэш L1.
NVIDIA с архитектурой Ampere вновь увеличила кэш L1 с 96 до 128 кбайт. Скорость работы L1 была вновь удвоена. NVIDIA реализовала такую же меру ранее при переходе с Pascal на Turing. Число 32-битных регистров не изменилось и осталось на уровне 16.384. То же самое касается числа блоков чтения/записи.



