На проде что означает

Это IT-сленг, который используют настолько часто, что он стал практически термином. Прод – это «боевой сервер», где приложение работает непосредственно для пользователей, клиентов, потребителей. Говоря о проде, подразумевают стабильную версию веб-приложения. Почему прод? Потому что такой сервер по-английски называют Production, а в русифицированном варианте – продакшн, сокращенно прод.
Мемов про прод в IT-среде немеряно. Главным образом они про кошмар программиста – «уронить прод». Как это бывает? Уронить прод может, например, джун по неопытности или KISA. KISA – это Knight in the Shining Armor, «рыцарь в сияющих доспехах». Так называется один из антипаттернов программирования. Это такой программист, который в попытке что-то пофиксить деплоит изменения сразу на прод, минуя код-ревью и тесты. Хуже только сделать это в пятницу вечером.
Вообще, мемы со словами «льем на прод», «без теста», «пятница», «вечер» и «отпуск» – «бородатые», но все равно обаятельные. Потому что дают пространство для воображения: ясно, чем команда программистов будет заниматься все выходные и что компания узнает о себе от потребителей в случае серьезного бага на проде.
На телеграм-каналах про юмор программистов можно, к примеру, встретить такой мем: мужчина в костюме стоит под водой, которая бьет из мостовой высоким фонтаном и что-то разбирает, долбит, закручивает. Вода постепенно перестает фонтанировать. Подпись: «Синьор фиксит баг сразу на проде».
Экстренное исправление ошибок в реальном времени на проде называется хотфиксами. Это то, чего надо всеми силами избегать, особенно, когда продукт коммерческий и с большой клиентской аудиторией. Как избегать? Сначала тестировать обновления, причем не на «боевоем сервере» и не на «боевых базах данных». Их так называют, это тоже IT-сленг.
Есть масса нюансов «раскатывания на прод». Так что допуск к проду считается вехой в профессиональном прогрессе джуна.
QA на проде. Почему это круто
Многие считают тестирование на production окружении вредной практикой: оно не помогает предотвратить попадание проблем к конечным пользователям, а больше констатирует их наличие. Кроме этого, тестировщик отрывается от стандартного рабочего процесса и методик, применяемых на тестовом окружении. Меня зовут Оля Михальчук, я QA-инженер в финтех-компании ID Finance. В этом посте я расскажу почему тестирование на проде может существенно помочь вашему проекту.

Зачем нужно QA на проде, если есть пре-продакшн окружение
В процессе разработки ПО всегда есть несколько окружений, на которых развёрнуто приложение. Среда, которой пользуются конечные пользователи, как вы знаете, называется production. Обычно предполагается, что тестирование нужно проводить на отдельном окружении, чаще на QA environment или Staging (пре-прод), чтобы предотвратить попадание ошибок к пользователям. Но есть такая методика, как QA на проде, которая отлично помогает решить задачи, которые на тестовом окружении решить физически невозможно.

В каких задачах помогает QA на проде
1. Проблема различия Staging и Production окружений.
Например, на нашем проекте пре-прод используется больше для функционального тестирования на сделанных вручную тестовых сценариях. Он не обладает техническими ресурсами, сравнимыми с продакшн средой. Также мы обычно не делаем полную синхронизацию конфигураций и БД с продакшн средой, что никак не мешает проводить функциональные тесты. Почему мы не копируем прод среду? Представьте, сколько ресурсов бы ушло, чтобы создать копию, допустим, Facebook, с такими же супермощными серверами, сервисами, базой данных и конфигурациями как на production. Это фактически как развернуть ещё одно такое же приложение.
Кроме того, при интеграции со сторонними сервисами вы всегда имеете разные настройки для тестового и боевого окружения (то же самое API). Я не утверждаю, что тестовая и staging среды бессмысленны. Просто нельзя на 100% гарантировать, что при успешном прохождении определённых тестов на одной среде сервисы не упадут на другой. Помочь в решении этой проблемы как раз и может дополнительное тестирование на production.
2. Реальные уровни многозадачности и нагрузки.
Некоторые ошибки можно обнаружить только под продолжительным и реальным уровнем многозадачности и нагрузки. Это касается утечек памяти, стабильности, быстродействия и устойчивости системы. Например, у нас была ситуация, когда возникла проблема быстродействия системы из-за того, что две ресурсоемкие задачи выполнялись в один промежуток времени. Разработчики оптимизировали работу задач, команда сделала тесты на пре-прод окружении, изменения доставили, затем сделали проверку на production.
3. Ошибки развёртывания
Из определения развёртывание (deployment) — это установка рабочей группой новой версии программного кода сервиса в инфраструктуру продакшна. Соответственно лучший способ увидеть ошибки развёртывания — это тестирование в процессе самого развёртывания.
4. Недостаток мониторинга на пре-проде
Один из лучших и незаменимых способов контроля того, что приложение работает так, как мы ожидаем – это ведение мониторинга по определённым метрикам. Например, из простых и наиболее критичных примеров: ведение мониторинга на количество регистраций новых пользователей в час, на конверсию от одного целевого действия к другому, на количество выданных кредитов. Конечно, такой мониторинг имеет смысл только на боевом окружении.
5. Возможность анализа сценариев использования системы, которые осуществляют конечные пользователи
Продакшн – кладезь тест-кейсов для тестировщика. При возможности у тестировщика видеть и обрабатывать сценарии, которыми пользуются конечные пользователи, тестировщик может выявить наиболее критичные сценарии, или выяснить причину появившегося дефекта, или обратить внимание на нетривиальные кейсы при тестировании на пре-проде.
6. Возможность ведения более достоверной статистики и метрик качества ПО.
Например, количество ошибок в логах приложения или компонента, баг-репорты и другая отчётность, которую может делать прод-тестировщик, более реально демонстрирует качество ПО по сравнению с теми же отчётами из тестового окружения.
7. Всегда лучше, если ошибку на проде заметит «свой» тестировщик, чем конечный пользователь.
Обычно после доставки задачи тестировщик делает базовые проверки новой или изменившейся функциональности на проде. Кроме того у нас в компании есть отдельно выделенный человек – тестировщик на проде. Хочу ещё раз отметить, что я не позиционирую QA на проде как замену тестированию на пре-продакшне, и, конечно предотвращать появление багов и проводить превентивные меры обязательно нужно. Но такое тестирование может стать отличной дополнительной техникой в процессе обеспечения качества на вашем проекте.

Полезные практики QA на production, которые эффективно работают у нас на проекте
1. Проверка доставленных задач с целью убедиться, что они хорошо задеплоились и работают на новом окружении.
Например, когда мы вводим интеграцию с новым партнёром, кроме тестов на пре-проде мы обязательно проверяем интеграцию после доставки, т.к существуют очень много настроек, зависящих от среды (API, урлы, компоненты). Также имеют место 3rd party issues – ошибки не на нашей стороне, а на стороне интегрируемых сервисов.
2. Логирование и аудит.
Хорошее логирование помогает разработчикам и тестировщикам заметить проблему ещё до того, как о ней догадается конечный пользователь, а также заметить места, нуждающиеся в оптимизации. Аудит действий и изменений позволяет всегда без проблем выяснить причины того или иного поведения. Например, если компонент кредитной политики не может выдать решение по кредиту, для анализа, почему это произошло, мы в первую очередь обращаемся к логам. Этот пункт касается как prodcution, так и pre-production сред.
3. Мониторинг и система оповещений
Как я упоминала выше, ведение мониторинга по определённым метрикам — один из лучших способов контроля того, что с нашим приложением всё «ok». Причём при возникновении какой-либо проблемы, надо обязательно слать об этом оповещение заинтересованным лицам (например, количество заявок по кредиту на 20% меньше ожидаемого – шлём оповещение IT и бизнес-отделам, нагрузка на CPU выше нормы – оповещение админам и девам). Нужно следить, чтобы оповещения о проблемах были своевременными и актуальными, а также реально указывали на проблему.
4. Регрессия и проверка стабильности
Классной практикой является периодическое прохождение регрессионных тестов, с целью убедиться, что нигде ничего не вышло из строя. Может помочь в каких-то узких и специфичных случаях, когда мониторинг не видит проблем.
5. Отчётность и ведение статистики
Как и в любом тестировании, отчётность и ведение статистики о результатах прод-тестирования делает процесс прозрачнее, качество ПО и причины возникновения дефектов более обозримыми.
Все ошибки невозможно выявить на пре-проде, поэтому они будут попадать в боевую среду. Если их обнаружат пользователи, это скажется на репутации компании и, в конечном счете, на потере денег. Тестирование на проде поможет это предотвратить.
Как выкатить обновление, если оно затрагивает все ваши сервисы
Обновления могут происходить каждый день, но иногда нужно выкатить фичу такого масштаба, что потенциальные ошибки поаффектят все ваши сервисы и пользователей. В статье расскажем, как сделать выкатку обновлений любой сложности в запланированный и анонсированный срок даунтайма без последствий для продакшен.
Что такое выкатка
Любой айтишник легко ответит, что такое выкатка: ставишь CI/CD, и автоматом все доставляется на прод.
Конечно, это верно. Сложность в том, что при современных инструментах автоматизации доставки кода теряется понимание самой выкатки. Как забываешь об эпичности изобретения колеса, глядя на современный транспорт. Все так автоматизировано, что выкатку часто проводят без осознания всей картины.
А вся картинка такова. Выкатка состоит из четырех больших аспектов:
Все эти аспекты необходимо учесть для успешной выкатки. Обычно оценивают только первый, в лучшем случае второй пункт, и тогда выкатка считается успешной.
Но третий и четвертый даже более важны. Какому пользователю понравится, если выкатка займет три часа вместо минуты? Или если на выкатке зааффектится что-то лишнее? Или даунтайм одного сервиса приведет к непредсказуемым последствиям?
Можно составить диаграмму Ганта или как-либо отобразить карту предстоящих событий для всей команды: сколько времени занимает каждое действие, что идет последовательно, что производится параллельно.

Пример диаграммы Ганта выкатки: из статьи о том, как команда платформы VK Cloud Solutions (бывш. MCS) выкатывала IAM (Identity and Access Management)
Хорошие практики для хорошей выкатки
Есть правила, которыми стоит руководствоваться, если вы выкатываете что-то сложное. Вообще говоря, их полезно соблюдать при любой выкатке. При этом чем выкатка сложнее, тем большую роль они играют.
Влияние выкатки на пользователей. Это первое, что надо понять: как выкатка может повлиять или повлияет на пользователей. Будет ли даунтайм? Если будет, то даунтайм чего? Как это отразится на пользователях? Какие возможны наилучшие и наихудшие сценарии? И закрывать риски. Например, заранее подготовить все, что можно подготовить прозрачно для пользователей. Или выкатывать фичу в то время, когда большинство пользователей не активны.
Четкий план. На каждом этапе нужно понимать все аспекты выкатки:
Репетиция сценариев. Проиграть сценарии до тех пор, пока не станут очевидны все этапы выкатки, а также риски на каждом из них. Если в чем-то есть сомнения, можно взять паузу и исследовать сомнительный этап отдельно.
Улучшения. Каждый этап можно и нужно улучшить, если это поможет нашим пользователям. Например, уменьшит даунтайм или уберет какие-то риски.
Тесты. Тестирование отката гораздо важнее, чем тестирование доставки кода. Нужно обязательно проверить, что в результате отката система вернется в первоначальное состояние, подтвердить это тестами.
Автоматизация. Все, что может быть автоматизировано, должно быть автоматизировано. Все, что не может быть автоматизировано, должно быть заранее написано на шпаргалке.
Результат. Нужно зафиксировать критерий успешности. Какой функционал должен быть доступен и в какое время? Если этого не происходит, запускайте план отката.
Действия команды. Самое главное — люди. Каждый должен быть в курсе, что делает, для чего и что от его действий зависит в процессе выкатки.
Если сказать одной фразой, то с хорошим планированием и проработкой можно что угодно выкатить без последствий для продакшен. Даже то, что аффектит все ваши сервисы.
Словарик айтишника или Что? Где? Куда? Часть 1
«Привет! Добро пожаловать! Спасибо, что приняла наш оффер. Пойдем знакомиться с твоей командой. У них как раз сейчас дейли. Ты вышла под конец спринта, поэтому пока работы для тебя не запланировали. Как стендап закончится, можешь почитать спеки, командные окиары и просмотреть бэклог на следующий спринт. По всем вопросам обращайся к своему пио.»
Язык айтишников
Каждый, кто работает в IT, непременно сталкивался с профессиональным жаргоном и компьютерным сленгом. Его можно любить или ненавидеть, принимать или терпеть, но непреложным остается факт — IT-жаргон существует и от него никуда не деться.
Когда приходишь в новую компанию, на тебя наваливается куча незнакомых слов. Кажется, их так много, что потребуется немало времени, чтобы понять и выучить их все. Многие слова ты уже знаешь, о смысле других догадываешься, часть из них является англицизмами, поэтому догадаться об их значении несложно Первая реакция — неприятие: «Зачем использовать английские слова в русский речи, когда есть достаточно русских альтернатив?» Потом ты пытаешься сохранить чистоту языка. В итоге, начинаешь говорить так же, как и все. Это неизбежно.
Профессиональный жаргон существует не для того, чтобы испортить русский язык. Он позволяет ускорить устное общение IT-специалистов и наладить их взаимопонимание. Обычно слова получаются короткими и емкими. Иногда одно слово заключает в себе целую фразу. Поэтому польза в них, на мой взгляд, есть.
Я послушала, как говорят разработчики в Wrike, и составила словарик из самых распространенных слов. Слова собраны по тематическим группам.
Scrum-терминология
Scrum — это методология по управлению проектами. Набор принципов, ценностей, политик, ритуалов для организации работы. В скраме полно терминов, но в ежедневный обиход попала и закрепилась только часть из них.
Бэклог
От англ. backlog (дословно — очередь работ) — еще не запланированный объем работы, который требуется выполнить команде. Каждая созданная задача вначале попадает в бэклог, а потом уже в спринт.
Как и в случае со спринтом, термин используется и в отрыве от скрама. Часто бэклогом называют отложенные задачи. Которые сделать нужно, но не сейчас.
Гол, голевой
От англ. goal (дословно — цель) — цель спринта (бывает одна или несколько), которую команда берется сделать. Цель состоит из ряда задач, которые нужно выполнить, чтобы его достигнуть.
Слово употребляется и как существительное, и как прилагательное. Может быть множественного числа.
Дейли
От англ. daily (дословно — ежедневно) — ежедневные короткие (от 5 до 30 минут) встречи команды с целью поделиться прогрессом по выполненным задачам за предыдущий день и озвучить план работ на текущий день. Также дейли могут называть стендапом (от daily standup), потому что обычно такие встречи происходят стоя — для большей эффективности.
Коммититься
Глагол от англ. существительного commitment (дословно — ответственность). Коммититься — значит обещать выполнить определенный объем работы в оговоренные сроки. Это не просто обещание, это сознательное обязательство перед собой и командой. Человек, который закоммитился, обязан сделать всё возможное, чтобы выполнить то, что сам и пообещал реализовать.
Спринт
От англ. sprint (дословно — бег на короткую дистанцию) — заданный отрезок времени, за который нужно выполнить запланированный объем работы, чтобы в конце этого отрезка был ожидаемый результат.
Термин используют не только те, кто работает по скраму, но и те, кто просто хочет организовать свою работу и сформировать ясные рамки, во время которых должны быть выполнены задачи.
Инструменты для работы
Технические, информационные и вспомогательные средства и приложения для работы.
Ветка
От англ. branch (дословно — ветка) — тот редкий случай, когда в ходу русский перевод термина. Веткой (термин git) называют полную копию проекта, в которой ведется разработка. В проекте может быть создано много веток, что позволяет работать одновременно с разными частями кода. Потом все ветки загружаются в мастер. Процесс «ответвления» иногда называют «бранчеванием», уже как раз от branch.
От англ. mock-up (дословно — эскиз) — макет с UX-дизайном для разработки. Несмотря на то, что слово дословно переводится как «эскиз» или «прототип», в Wrike моками называют готовые проработанные макеты с дизайном.
От англ. production (дословно — промышленная среда) — ветка с рабочей версией продукта, которую видят пользователи. Это окончательная точка куда попадает результат разработки. Иногда так же называют мастер.
От англ. reference (дословно — пример) — схожий функционал или внешний вид, который используется для ориентира. Он служит для сравнения.
Спека
От англ. specification (дословно — спецификация) — документ с подробным описанием требований, условий и технических характеристик, как должен работать разрабатываемый функционал.
Таска
От англ. task (дословно — задача) — задача, заведенная или планируемая на любого работника.
Разработка
Термины, употребляющиеся разработчиками при работе над задачами.
От англ. boost (дословно — ускорение) — процесс повышения производительности, ускорение загрузки.
Катить
Отправлять готовую работу в деплой, предпринимать шаги для подготовки ветки к мерджу в продуктовую ветку.
Комплитить
От англ. complete (дословно — заканчивать) — завершать задачу, закрывать задачу, когда она полностью готова.
Консистентность
От англ. consistency (дословно — системность) — общее единообразие во всех частях продукта.
Матчится
От англ. match (дословно — совпадать) — полное соответствие чего-либо с чем-либо. Процесс приведения к единообразию.
Пинать
Термин, подобный глаголу «пинать», который также имеет значение «делать» и «работать». Конкретное значение определяется по приставке. Подопнуть — сделать немного, допинать — доделать.
Ручка
От англ. handler (дословно — обработчик) — бэкэнд-термин, означающий ответ от сервера, в котором приходят данные.
Скоуп
От англ. scope (дословно — объем) — набор фич и частей продукта, закрепленных за отдельной командой.
От англ. feature (дословно — характеристика) — определенная часть или деталь от общего продукта, которая разрабатывается изолированно.
От англ. flow (дословно — течение) — порядок действий при работе над задачей. Например, вначале задача берётся в разработку, потом проходит ревью, далее тестируется и т.д.
Должности
Некоторые должности, названия которых вошли в обиход в виде сокращений с английского.
Девопс
От англ. DevOps, сокращенно от Developer Operations (дословно — интеграция разработки и эксплуатации) — специалист, занимающийся внедрением DevOps-методологии. Полное название должности — DevOps-инженер, но в речи вторую часть всегда отбрасывают.
От англ. PO, сокращенно от Product Owner (дословно — владелец продукта) — роль по скрам-методологии, человек, ответственный за проработку продукта и распределение бэклога. Он знает о требованиях пользователя и возможностях команды.
От англ. PM, сокращенно от Product Manager (дословно — менеджер продукта) — менеджер, который отвечает за продукт, его обязанности совпадают с обязанностями пио, отличие только в том, что это название должности, а не роли в скраме. Так же, как пио, пиэмов могут называть продакт.
Организационное
Термины, относящиеся к организации работы, а также термины, употребляющиеся в неформальной речи при обсуждении чего-либо.
Дейоф
От англ. day-off (дословно — выходной) — просто выходной.
Драйвер
От англ. driver (дословно — водитель) — человек, который берет на себя инициативу управления проектом/процессом/задачей. В его обязанности входит следить за тем, как протекает созданный им процесс, и руководить им. Он мотивирует других людей выполнять работу для достижения поставленных целей.
Консёрн
От англ. concern (дословно — тревога, участие) — в английском языке слово «консёрн» имеет много различных значений, при этом очень часто употребляется в русской речи. Какое именно значение вкладывает в него автор, известно только ему самому. Иногда — это смесь многих значений, таких как: особый интерес, беспокойство, цель, настороженность, опасение и т.д.
Окиары
От англ. OKR, сокращенно от Objectives and Key Results (дословно — цели и ключевые результаты) — система по постановке и достижению целей. Она нужна для синхронизации работы всех участников компании/отдела/команды, чтобы все двигались в одном направлении, с понятными приоритетами и постоянным ритмом. В отличие от KPI, это амбициозное целеполагание, достижение окиаров (окров) на 70-80% — отличный результат.
Оффер
От англ. offer (дословно — предложение) — предложение о работе / приглашение на работу.
Поинт
От англ. point (дословно — точка) — чаще всего употребляется в значении «точка зрения», сокращенно от point of view. Также в значениях: «суть», «смысл», «довод».
На проде что означает








Что пишут в блогах
Заказать — https://shop.testbase.ru/buy/book. Пока самовывоз (см ниже где и когда!!). С почтой разберемся чуть позже.
Где: Кострома / онлайн
2 декабря буду выступать в Костроме. Приходите увидеться очно, или подключайтесь онлайн.

Онлайн-тренинги
Что пишут в блогах (EN)
Blogposts:
Разделы портала
Про инструменты

Автор: Ольга Михальчук, QA инженер ID Finance
Многие считают тестирование на production окружении вредной практикой: оно не помогает предотвратить попадание проблем к конечным пользователям, а больше констатирует их наличие. Кроме этого, тестировщик отрывается от стандартного рабочего процесса и методик, применяемых на тестовом окружении. Меня зовут Оля Михальчук, я QA-инженер в финтех-компании ID Finance. В этом посте я расскажу почему тестирование на проде может существенно помочь вашему проекту.
Зачем нужно QA на проде, если есть пре-продакшн окружение
В процессе разработки ПО всегда есть несколько окружений, на которых развёрнуто приложение. Среда, которой пользуются конечные пользователи, как вы знаете, называется production. Обычно предполагается, что тестирование нужно проводить на отдельном окружении, чаще на QA environment или Staging (пре-прод), чтобы предотвратить попадание ошибок к пользователям. Но есть такая методика, как QA на проде, которая отлично помогает решить задачи, которые на тестовом окружении решить физически невозможно.
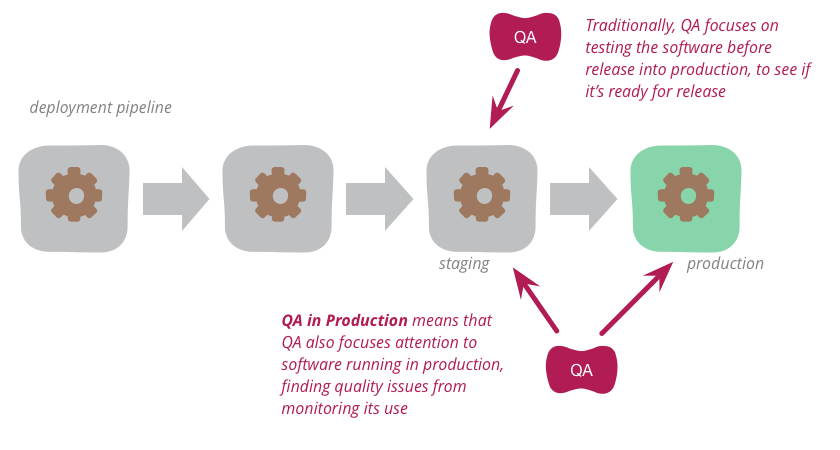
В каких задачах помогает QA на проде
1. Проблема различия Staging и Production окружений.
Например, на нашем проекте пре-прод используется больше для функционального тестирования на сделанных вручную тестовых сценариях. Он не обладает техническими ресурсами, сравнимыми с продакшн средой. Также мы обычно не делаем полную синхронизацию конфигураций и БД с продакшн средой, что никак не мешает проводить функциональные тесты. Почему мы не копируем прод среду? Представьте, сколько ресурсов бы ушло, чтобы создать копию, допустим, Facebook, с такими же супермощными серверами, сервисами, базой данных и конфигурациями как на production. Это фактически как развернуть ещё одно такое же приложение.
Кроме того, при интеграции со сторонними сервисами вы всегда имеете разные настройки для тестового и боевого окружения (то же самое API). Я не утверждаю, что тестовая и staging среды бессмысленны. Просто нельзя на 100% гарантировать, что при успешном прохождении определённых тестов на одной среде сервисы не упадут на другой. Помочь в решении этой проблемы как раз и может дополнительное тестирование на production.
2. Реальные уровни многозадачности и нагрузки.
Некоторые ошибки можно обнаружить только под продолжительным и реальным уровнем многозадачности и нагрузки. Это касается утечек памяти, стабильности, быстродействия и устойчивости системы. Например, у нас была ситуация, когда возникла проблема быстродействия системы из-за того, что две ресурсоемкие задачи выполнялись в один промежуток времени. Разработчики оптимизировали работу задач, команда сделала тесты на пре-прод окружении, изменения доставили, затем сделали проверку на production.
3. Ошибки развёртывания
Из определения развёртывание (deployment) — это установка рабочей группой новой версии программного кода сервиса в инфраструктуру продакшна. Соответственно лучший способ увидеть ошибки развёртывания — это тестирование в процессе самого развёртывания.
4. Недостаток мониторинга на пре-проде
Один из лучших и незаменимых способов контроля того, что приложение работает так, как мы ожидаем – это ведение мониторинга по определённым метрикам. Например, из простых и наиболее критичных примеров: ведение мониторинга на количество регистраций новых пользователей в час, на конверсию от одного целевого действия к другому, на количество выданных кредитов. Конечно, такой мониторинг имеет смысл только на боевом окружении.
5. Возможность анализа сценариев использования системы, которые осуществляют конечные пользователи
Продакшн – кладезь тест-кейсов для тестировщика. При возможности у тестировщика видеть и обрабатывать сценарии, которыми пользуются конечные пользователи, тестировщик может выявить наиболее критичные сценарии, или выяснить причину появившегося дефекта, или обратить внимание на нетривиальные кейсы при тестировании на пре-проде.
6. Возможность ведения более достоверной статистики и метрик качества ПО.
Например, количество ошибок в логах приложения или компонента, баг-репорты и другая отчётность, которую может делать прод-тестировщик, более реально демонстрирует качество ПО по сравнению с теми же отчётами из тестового окружения.
7. Всегда лучше, если ошибку на проде заметит «свой» тестировщик, чем конечный пользователь.
Обычно после доставки задачи тестировщик делает базовые проверки новой или изменившейся функциональности на проде. Кроме того у нас в компании есть отдельно выделенный человек – тестировщик на проде. Хочу ещё раз отметить, что я не позиционирую QA на проде как замену тестированию на пре-продакшне, и, конечно предотвращать появление багов и проводить превентивные меры обязательно нужно. Но такое тестирование может стать отличной дополнительной техникой в процессе обеспечения качества на вашем проекте.

Полезные практики QA на production, которые эффективно работают у нас на проекте
1. Проверка доставленных задач с целью убедиться, что они хорошо задеплоились и работают на новом окружении.
Например, когда мы вводим интеграцию с новым партнёром, кроме тестов на пре-проде мы обязательно проверяем интеграцию после доставки, т.к существуют очень много настроек, зависящих от среды (API, урлы, компоненты). Также имеют место 3rd party issues – ошибки не на нашей стороне, а на стороне интегрируемых сервисов.
2. Логирование и аудит.
Хорошее логирование помогает разработчикам и тестировщикам заметить проблему ещё до того, как о ней догадается конечный пользователь, а также заметить места, нуждающиеся в оптимизации. Аудит действий и изменений позволяет всегда без проблем выяснить причины того или иного поведения. Например, если компонент кредитной политики не может выдать решение по кредиту, для анализа, почему это произошло, мы в первую очередь обращаемся к логам. Этот пункт касается как prodcution, так и pre-production сред.
3. Мониторинг и система оповещений
Как я упоминала выше, ведение мониторинга по определённым метрикам — один из лучших способов контроля того, что с нашим приложением всё «ok». Причём при возникновении какой-либо проблемы, надо обязательно слать об этом оповещение заинтересованным лицам (например, количество заявок по кредиту на 20% меньше ожидаемого – шлём оповещение IT и бизнес-отделам, нагрузка на CPU выше нормы – оповещение админам и девам). Нужно следить, чтобы оповещения о проблемах были своевременными и актуальными, а также реально указывали на проблему.
4. Регрессия и проверка стабильности
Классной практикой является периодическое прохождение регрессионных тестов, с целью убедиться, что нигде ничего не вышло из строя. Может помочь в каких-то узких и специфичных случаях, когда мониторинг не видит проблем.
5. Отчётность и ведение статистики
Как и в любом тестировании, отчётность и ведение статистики о результатах прод-тестирования делает процесс прозрачнее, качество ПО и причины возникновения дефектов более обозримыми.
Все ошибки невозможно выявить на пре-проде, поэтому они будут попадать в боевую среду. Если их обнаружат пользователи, это скажется на репутации компании и, в конечном счете, на потере денег. Тестирование на проде поможет это предотвратить.



