Нетранзакционные данные что это
Производители СУБД и корпоративных платформ активно соревнуются в разработке новых функциональных возможностей своих продуктов. Однако многие проблемы, такие как совместная обработка данных или управление их жизненным циклом, могут быть решены проще и эффективнее посредством технологий управления данными.
Увеличение объема информации и развитие информационных систем – два взаимосвязанных процесса: рост объемов данных требует развития средств их обработки, совершенствование которых стимулирует обработку все больших массивов данных. Сегодня практически в каждой более-менее крупной организации деятельность строится вокруг корпоративной информационной системы (а зачастую и нескольких систем), большинство из которых построены на основе реляционных систем управления базами данных по трехзвенной архитектуре: клиентские приложения – серверы приложений – серверы баз данных. При разработке каждой такой системы приходится решать ряд проблем, связанных с управлением данными.
Проблема отслеживания изменений
Решение же проблемы неповторяющегося чтения (состоящей в отличии результатов первичного и последующего чтения данных одним клиентом, не изменявшим их), а также проблемы потерянного обновления (возникающей при одновременном изменении различными клиентами одного и того же значения элемента, при котором более раннее изменение теряется) средствами транзакций на уровне только сервера баз данных и/или сервера приложений эффективно лишь в отношении серверных задач обработки данных, которые выполняются на сервере приложений или сервере баз данных в фоновом режиме по заранее заданному алгоритму и без активного участия пользователя.
Однако защиту от аналогичных проблем требуется обеспечивать и при ручной обработке данных пользователями с использованием их клиентских приложений. Основное отличие здесь заключается в том, что каждый пользователь работает не напрямую с данными, содержащимися в СУБД, а с некоторой их локальной копией, загруженной в клиентское приложение. Зачастую это приводит к тому, что когда два пользователя сохраняют изменения в одном и том же элементе данных (причем их исправления могли касаться разных его свойств), более раннее изменение теряется, причем клиент, чье изменение потеряно, может некоторое время этого даже не видеть.
Считается, что защита от подобного рода проблем должна обеспечиваться логикой приложения за счет более активного использования транзакций. Но не все проблемы конкурентного доступа можно обойти программно за счет дополнительных проверок и транзакций. И ключевой фактор здесь – человек. Невозможно выделить программным образом последовательность чтений и записей пользователем данных, составляющих атомарную операцию. Следовательно, нельзя и откатить такую транзакцию при изменении данных чтения – система просто не в состоянии определить, какое количество последних действий пользователя образуют единое целое, да и какие из прочитанных им данных учел пользователь при принятии решения. Что же остается делать?
Как и во всех случаях, когда предотвратить проблему невозможно, все усилия должны быть сконцентрированы на ее отслеживании. Причем в корпоративных системах управление конкурентным доступом – далеко не единственное направление, где требуется решение задачи отслеживания изменений. Другой очень важной проблемой является сложность выявления данных, на основе которых сформированы другие, как правило, обобщенные данные. В качестве характерного примера можно привести различного рода отчеты, формируемые на основании данных из системы и не сохраняющиеся в ней. Определить в будущем источники формирования каждого сводного показателя отчета можно лишь при условии неизменности исходных данных.
В качестве одного из решений здесь возможно введение административного запрета редактирования данных, по которым сформированы отчеты, однако это далеко не всегда возможно, да и не слишком удобно. А с другой стороны, вполне обычным является процесс, когда после сдачи первичного отчета в последующем, при выявлении неточностей, эти неточности исправляются, а на основании исправленных данных формируется уточненный отчет (таков, к примеру, порядок в отношении налоговой отчетности).
В общем виде целью отслеживания изменений является возможность получения данных, существовавших в системе (локальной копии данных) на момент принятия пользователем решения об изменении данных, формирования отчета и т.п. Кроме того, зачастую также требуется наличие информации об авторстве изменений и исправлений. Причем сведения нужны относительно всех модификаций, а не только последних, так как ошибки в данных (умышленные или неумышленные) могли быть внесены ранее, а другие пользователи в дальнейшем основывались на них.
Особенно актуальной данная задача выглядит в свете повсеместного перехода от бумажных информационных ресурсов к электронным ресурсам, в которых требуется придание данным юридической значимости (посредством ЭЦП). Отдельно следует отметить, что речь здесь идет не о придании юридической значимости отдельным документам, передаваемым между организациями, а о формировании полностью юридически значимого массива данных, любая выборка из которого также имеет официальный статус. Естественно, что при этом должна обеспечиваться персональная ответственность лиц, формирующих данный информационный массив. Особенно это важно для государственных систем, где каждый служащий имеет свои полномочия и несет соответствующую ответственность.
Задача отслеживания модификаций данных также крайне важна для обеспечения их синхронизации при совместной обработке данных в нескольких информационных системах. Если системы работают последовательно (то есть данные из первой системы служат сырьем для второй), то все относительно просто. Сложнее дело обстоит с организацией параллельной обработки данных, например, при управлении мастер-данными. Здесь широко применяется централизованная модель, при которой все мастер-данные хранятся в выделенной системе, однако это не всегда удобно и возможно, особенно при взаимодействии информационных систем различных организаций. Кроме того, такая модель не основана на технологии управления данными, а представляет собой лишь архитектурное решение.
Если вернуться к государственным информационным системам, то организация параллельной обработки данных в электронных информационных ресурсах, каждый из которых содержит юридически значимую информацию, является одним из основных инфраструктурных элементов подхода к построению электронного правительства.
Транзакционные и нетранзакционные данные
Но важнее другое – реляционная модель данных предоставляет весьма широкие средства, которые вполне могут быть использованы для решения перечисленных выше проблем. Может быть, и не стоит искусственно расширять эту модель дополнительной временной размерностью?
Данные, обрабатываемые в каждой информационной системе, можно разделить на транзакционные и нетранзакционные. Транзакционные данные – это данные, каждая запись которых относится к фиксированному моменту времени и содержит сведения, фиксированные на данный момент времени, не изменяющиеся в будущем. Соответственно, нетранзакционными являются все остальные данные.
Транзакционные данные обычно представляют собой повторяющиеся примеры событий, явлений, происшествий одного и того же типа. Сюда относятся все заявки, счета, накладные – да и вообще все документы (как сущности), так как все они зафиксированы (это уже оформленные документы) и привязаны к некоторому моменту времени (времени их составления или регистрации).
Нетранзакционные данные, которые часто называют справочными или базовыми данными, представляют собой списки однотипных объектов: сущностей, предметов и абстрактных категорий. Как правило, это разнообразного рода справочники и классификаторы, другими словами – мастер-данные или, как частный случай, нормативно-справочная информация.
Нетрудно заметить, что связь между этими двумя категориями данных, как правило, односторонняя: при описании транзакционных схем могут использоваться как транзакционные, так и нетранзакционные данные, а при описании же нетранзакционных данных, как правило, используются только нетранзакционные данные. Например, при составлении накладной используются несколько справочников (контрагентов, номенклатуры), а основанием для накладной может служить, например, счет.
С другой стороны, если не принимать во внимание конкретное информационное представление данных и процедуры их архивации и утилизации, то можно утверждать, что количество информационных объектов транзакционных данных постоянно увеличивается, так как регистрация каждого нового события вызывает появление новой записи. В то же время, количество информационных объектов нетранзакционных данных является относительно постоянным.
Значение каждой записи транзакционных данных, как правило, остается неизменным с момента ее фиксации. Исключения составляют случаи коррекции записи по причине неточностей или ошибок, что, кстати, в информационной системе обычно рассматривается как не совсем корректное действие – коррекция должна проводится отдельной операцией. Нетранзакционные данные не привязаны к конкретному моменту времени, но в течение своего жизненного цикла они могут определяться, а значения атрибутов каждого элемента таких данных могут изменяться.
Таким образом, проблема отслеживания модификаций, в основном, актуальна для нетранзакционных данных. Для транзакционных данных она имеет смысл лишь в части отслеживания исправлений.
Одной из основных причин появления проблем, связанных с представлением нетранзакционных данных, является то, что нетранзакционные данные часто воспринимаются как условно-постоянные и, как следствие, имеющие статичное представление в базах данных. Для записи данных в SQL используются операторы вставки (insert), изменения (update) и удаления (delete). Как правило, эти операторы используются весьма прямолинейно: появился новый объект – вставили новую запись, изменились его характеристики – обновили их, исчез объект – удалили запись. Справедливости ради, следует отметить, что для повышения ссылочной целостности вместо операции удаления в настоящее время все больше используется обновление дополнительного атрибута (статуса) записи.
Однако операция обновления тоже не безобидна. Прекращение существования объекта – это новая информация, и результатом должно быть не общее сокращение информации в базе данных, а наоборот, ее увеличение. Аналогично, при изменении характеристик одного из объектов поступает новая информация, и общий объем информации в базе данных также должен увеличиваться. То же самое можно сказать и про исправления. Другими словами, информационные элементы должны хранить информацию о жизненном цикле реальных объектов, а не повторять его.
Используя термины SQL, можно говорить, что для прекращения существования объектов и изменения их характеристик недопустимо использование операторов delete и update. Эти операторы являются служебными и должны использоваться исключительно в служебных целях: для перемещения, архивации и утилизации массивов данных. Таким образом, можно сделать вывод, что все данные, циркулирующие в базе данных, должны быть транзакционными; нетранзакционные данные должны представляться в виде цепочки транзакционных данных.
Темпоральность в реляционной СУБД
Двойная темпоральность позволяет не просто более точно описать модель системы, но и определить операцию исправления. Для этого в дополнение к существующей записи с неправильным значением вносится корректирующая запись с тем же действительным временем, текущим транзакционным временем и исправленными значениями.
Кроме расширения возможностей представления данных в информационной системе, использование битемпоральной модели позволяет обеспечить управление конкурентным доступом в части защиты от проблем неповторяющегося чтения. Это достигается за счет того, что в рамках одной операции (транзакции) при обработке данных используется ограничение на выборку данных: используются только записи, внесенные в информационную систему до начала транзакции.
Двойная темпоральность данных в сочетании с управлением данных в режиме «только вставка» позволяет обеспечивать хранение вместе с данными сведений о пользователе, внесшем изменения, а также его электронную цифровую подпись, рассчитанную на основании внесенных данных. Это позволяет организовать юридически значимое хранилище данных с разделением персональной ответственности за их содержание.
Кроме того, данная технология позволяет обеспечить возможность отслеживания данных, которые существовали в системе до внесения пользователем изменений. Аналогичным же образом можно отследить первичные данные, находившиеся в системе при формировании вторичных данных, при условии сохранения вместе с вторичными данными штампа времени, по состоянию на которое они сформированы.
При этом следует отметить, что в трехзвенной архитектуре здесь возможны конфликтные ситуации, связанные с тем, что между временем чтения данных и моментом внесения изменений в данные могут быть внесены изменения другим пользователем. Чтобы защититься от этого, имеет смысл использовать два транзакционных времени: основное транзакционное время – транзакционное время внесения изменений; и транзакционное время чтения данных – для отслеживания основного транзакционного времени данных, на основе которых производилась обработка.
В данной модели в чистом виде невозможно отобразить исчезновение (удаление) объекта. Однако, кроме появления, исчезновения элементов данных и изменения их атрибутов, с ними могут происходить также такие события, как объединение, присоединение, разделение, выделение, реорганизация. Для реализации требуемых операций необходимо использовать дополнительную таблицу, причем соответствующее событие должно отображаться в ней в виде перехода (вектора) с указанием предшествующего идентификатора (null при появлении элемента) и нового идентификатора (null при исчезновении элемента). Используя подобный подход, несколькими взаимосвязанными записями можно отразить в состоянии базы данных любую из перечисленных выше операций.
Существенной проблемой является обеспечение мягкой модернизации информационных систем вместе с соответствующими взаимосвязями между ними. В первую очередь, сложность составляет необходимость модернизации метаданных и обеспечение работы с данными прошлых периодов в соответствующей схеме данных. Важное значение имеет также сохранение связанности систем при изменении структур данных без дополнительной разработки, а лишь за счет соответствующей перенастройки связей.
По сути, кроме жизненного цикла элемента данных и жизненного цикла его атрибутов, имеет смысл рассматривать еще два жизненных цикла метаданных: жизненный цикл классов (таблиц) и жизненный цикл атрибутов классов (столбцов таблиц). Для их описания требуются дополнительные таблицы, в которых так же, как и для отражения в состоянии базы данных операций над элементами данных, используются переходы.
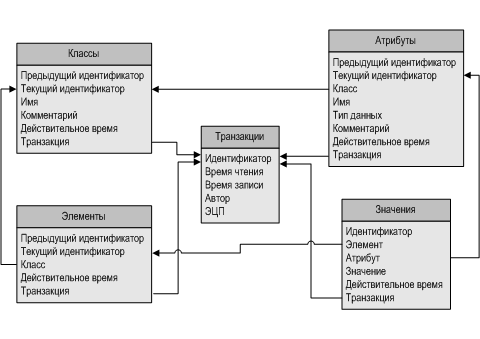
На рисунке изображена структура для представления данных по описанной технологии. Для связи записей выделена дополнительная таблица транзакций, в которой хранятся транзакционное время чтения, транзакционное время записи, сведения об авторе и его электронная цифровая подпись. Это дополнительно позволяет осуществлять ручной откат транзакций, а также в некоторой степени сократить объем памяти, требуемой для хранения информации о пользователях и ЭЦП. Все таблицы элементов объединены в единую таблицу, которая содержит поле, указывающее на класс элемента. Также в одну таблицу объединены и все таблицы значений, и эта таблица содержит поля ссылок на таблицу элементов и таблицу атрибутов.
Заключение
Темпоральная организация данных позволяет значительно упростить их совместное редактирование в нескольких информационных системах, а темпоральная организация метаданных – предоставить возможность мягкой модернизации структур данных и обеспечение работы с данными прошлых периодов в соответствующей схеме данных.
Описанный подход может быть применим при построении систем самого различного назначения, в первую очередь, систем (подсистем) управления мастер-данными или нормативно-справочной информацией. В частности, использование описанной технологии может решить множество проблем при построении одного из основных компонентов электронного правительства – Системы реестров государственных услуг.
Что такое Мастер-Данные и зачем они нужны
Введение

(клик по картинке ведёт внутрь публикации)
Развиваясь, организации внедряют всё больше и больше информационных систем совершенно различных направлений: бухгалтерский учет, управление персоналом, управление складом etc. Системы живут и развиваются независимо друг от друга до того самого момента, как компании не потребуется взглянуть на свои данные целиком. Объемы данных уже достигают критической точки и выясняется, что сопоставить и сравнить данные вручную становится просто невозможно. Решения основанные на противоречивых и невыверенных данных ведут к управленческим ошибкам, а дубли и неактуальность данных к неверным бизнес решениям.
Конечно же проблема описанная выше не нова и сегодня мы обсудим классический способ решения — систему управления мастер-данными.
Что такое MDM
Master Data Management (сокращенно: MDM, МДМ, НСИ; варианты перевода: управление мастер-данными, нормативно-справочная информация) система — комплекс процессов, систем управления, стандартов и программ позволяющих единообразно работать с данными. Проще говоря, МДМ-система предоставляет целостный взгляд на все составляющие бизнеса, в том числе на источники данных, авторство, качество, полноту и на потенциальное использование данных. (Подробнее: Задачи управления мастер-данными)
(кликабельно)
Типы корпоративных данных: что такое справочные и транзакционные данные
Чтобы разобраться, чем являются и не являются мастер-данные разберем основные типы корпоративных данных.
(взято отсюда)
Неструктурированные данные — текст, почта, и другие данные, у которых нет формально определенной и описанной структуры.
Полуструктурированные — данные не имеющие определенной схемы (или имеющие переменную структуру), но тем не менее имеющие формальное описание в виде тегов и\или определенных маркеров. XML — пример, полуструктурированных данных.
Структурированные (транзакционные) данные — данные имеющие формально определенную схему.
Метаданные — это данные описывающие другие данные, например, схема базы данных клиентов, конфигурационный файл или шаблон отчета.
Мастер-данные — это данные, содержащие ключевую информацию о бизнесе, в том числе о клиентах, о продуктах, о работниках, о технологиях и материалах. Каждая из этих групп может разделяться на несколько предметных областей: в категорию люди входят клиент, продавец, поставщик. Так же может иметь набор правил валидации, которым должны удовлетворять данные.
Иногда в отдельную категорию выделяют иерархические данные — это данные, в которых хранятся отношения и взаимодействия между данными. Подробнее.
Пример, общей структуры мастер-данных и валидационных правил (кликабельно)
Зачем оно нужно?
Исторически многие системы хранения, анализа и визуализации данных развивались параллельно и не совместимы между собой. По мере роста компании интеграция данных становится всё более важной и во многих случаях критической задачей, согласно Microsoft уже компании среднего размера ощущают на себе последствия работы с разнородными данными.
Таким образом одной из задач МДМ-систем является синхронизация данных, что упрощает решение сопутствующих задач, как подготовка финансовой отчетности.
МДМ-система — это один из краеугольных камней в архитектуре бизнеса вместе с ERP и BI системами, позволяющий системам аналитики и ведения бизнеса иметь единое преставление о данных, независимо от источника и формы.
Рассмотрим несколько классических случаев, где необходимо использовать и внедрять систему управления мастер-данными.
Зоопарк ИТ-систем и консолидированная отчетность
Пусть в компании больше трех систем хранения-анализа данных. Заполняются они и развиваются независимо друг от друга. В какой-то момент появляется необходимость собрать консолидированную отчетность и необходимо синхронизировать нормативно-справочную информацию. Например, существуют компания Ромашка с оборотом в 1М и имеются две записи «Общ.огр. Ромашка» и «ООО Ромашка» в разных системах с оборотом 400к и 600к, без инструментов синхронизации, система создания отчетности не сумеет объединить записи.
Интеграция систем
Пусть имеется несколько 1С систем в отделениях компании и счета, выставленные ООО «Ромашка» необходимо выгрузить и проанализировать в CRM. Если в CRM заведены несколько дублей, например Ромашка и Общ. Огр. Ромашка, то встает вопрос к какой Ромашке в CRM эти счета привязать и есть ли среди этих Ромашек нужная?
Единая база контрагентов
Прежде всего создание единой базы необходимо, для качественной и достоверной информацию о контрагентах. Если клиент, уже подписавший контракт, получает дополнительные N звонков о необходимости выслать уже отправленные документы (т.к. «Общ.огр. Ромашка» и «ООО Ромашка» — синтаксически разные компании), то это негативно отражается на отношениях компании.
Очистка и нормализации данных
Описанные выше случаи — это задачи по очистке и нормализации данных (data cleaning and data quality).
Очистка и нормализация данных — это безусловно инструменты, цель — это повышение лояльности клиента (e.g. избегаем повторных звонков), создание отчетности (уверенность в корректности аналитики) и увеличение скорости выполнения задач (быстрее проходим цикл продаж).
Как правило, клиент приходит к необходимости внедрения системы управления НСИ. Например необходимость оперативного контроля над деятельностью предприятия может потребовать сбора консолидированной отчетности, что в свою очередь приведет к необходимости синхронизации НСИ в ИТ-система, что в свою очередь потребует внедрения системы управления НСИ.
Случаи из жизни
Четырнадцать 1С-ок
У одной компании N было четырнадцать 1С систем в филиалах и вот однажды им пришлось срочно предоставить отчетность о своей деятельности в какую-то там палату. Отсутствие единой отчетности грозило существенными проблемами и вот M сотрудников несколько недель вместе сводили и выверяли данные. А могли бы просто физически не успеть.
Клиент из Астрахани отправил фуры заказчику в другой регион, а обеспечение в пути оказывала компания Х, у которой не было МДМ-системы и единой базы контрагентов. Во время путешествия фуры проходили обслуживание в двух регионах — и по окончанию поездки компания Х выставила счет клиенту по этим регионам по стандартному прейскуранту без положенной скидки за объем, так как клиент был записан в этих двух регионах под чуть-чуть по-разному и система не сопоставила имена. Итог — дополнительные разбирательства и ухудшение деловых отношений.
Повторные звонки
Однажды клиенту позвонили шесть (!) раз после того, как контракт был подписан. Из-за подобной некомпетентности лояльность клиента и контракт были под угрозой.
Методы решения
Рассмотрим два наиболее популярных метода решения проблем, описанных выше.
Административное решение
Административный подход — сначала вычистить уже имеющиеся дубли в ИТ-системах, разработать систему кодировок, по которым можно сопоставить записи в справочниках разных ИТ-систем, и регламенты. Такой метод относительно прост, но имеет ряд недостатков – он не предотвратит рассинхронизацию НСИ в разных системах, а регламенты всегда можно обойти.
Внедрение MDM-системы
Технологический подход — использование системы обеспечивающей синхронизацию и единое представление данных. Как правило большинство крупных компаний внедряют различные версии MDM, когда ручная консолидация справочной информации и отчетности становится невозможной, а внедрение любой новой системы вынуждает изменять регламент и кодировки, только усиливая хаос.
Безусловно, единовременное введение МДМ-системы не решит все проблемы и по мере развития бизнеса, должна развиваться и МДМ-система, может даже измениться и сам тип МДМ системы (основные типы освещены ниже), однако, как показывает практика MDM является оптимальным бизнес решением в подобных случаях.
Типы МДМ-систем
Мы рассмотрим три основных типа MDM-систем — подробнее можно прочитать тут.
Централизованная система
Выбирается одна IT система, это может быть как уже имеющаяся IT-система, так и отдельная система управления НСИ. Справочные данные в этой системе будут считаться эталонными, вестись в ней и рассылаться в другие системы. При этом создание и редактирование справочных данных в других IT системах запрещается. Преимуществами такого подхода являются:
Аналитическая система
В аналитической системе НСИ все элементы НСИ создаются в клиентских системах, откуда отправляются в систему НСИ, где из этих элементов формируется запись справочника НСИ. Это позволяет быстро внедрять систему, внося минимальные изменения в клиентские системы.
Но так как НСИ в отдельно взятой IT-системе ни с чем не синхронизируется, то в самой IT-системе могут быть дубли и отчетность может расплыться, поэтому построение оперативной отчетности затруднено (про локальную отчетность также говорят, что она «грязная» — локальные записи НСИ могут не соответствовать записям в системе НСИ).
Гармонизированная система
Эта система вобрала в себя лучшее из централизованной и аналитической систем. Она позволяет заводить данные в IT-системах, и затем сопоставлять с уже заведенными, умеет искать потенциальные дубли, разрешать конфликты, связанные с одновременным изменением одних и тех же данных в разных IT-системах, синхронизировать НСИ в IT-системах. Таким образом не меняются и не нарушаются бизнес-процессы, минимизируются ручная работа по подготовке отчетности — то есть просто строиться локальная отчетность. Однако данные подход является наиболее дорогим, трудоёмким и требуют серьезной экспертизы для построения, а так же может потребовать модификации клиентских приложений.
Примеры реализации MDM-систем
Примером аналитической системы управления НСИ является Navicon SalesOut, а примером централизованной и гармонизированной – разные конфигурации Navicon MDM.
Индикаторы необходимости внедрения МДМ-систем
Ключевые: необходима интеграция различных систем и единая отчетность на основе этих данных.
Частные предпосылки внедрения на примере с одним из клиентов



