Агрегирование портов. LACP.
Агрегирование порта
Что делать, если одного соединения пропускной способности в 100M/1G/10G/100G недостаточно для ваших нужд? Теоретическим, мы можем соединить оборудование несколькими линками, но без агрегирования мы получим только петлю на оборудовании, в результате чего положим сеть, если, конечно, не будет включен протокол Spanning Tree, который воспримет эти соединения как петли и не выключит лишние линки. Почему образуется петля? Это связано с работой коммутаторов, подробнее можно прочитать тут
Давайте рассмотрим, что такое агрегация и агрегированные порты и зачем это надо.
В терминологии CISCO это Etherchannel, Brocade — LAG, Extreme — sharing… Стандартизированное решение — LACP(Link Aggregation Control Protocol) — протокол, который не зависит от вендора (производителя) оборудования. Все реализации объединения/агрегирования портов выполняют одну функцию, а именно, объединение физических портов в 1 логический с суммарной пропускной способностью.

В данное время практически все провайдеры, цоды, дата-центры, контент-генераторы использую агрегацию для увеличения пропускной способности линии,так как ее плюсы очевидны: увеличение пропускной способности и резервирование линков (при падении одного, трафик равномерно распределяется между другими). Однако, находятся и те, которые не используют лаг, например, всем известная социальная сеть Вконтакте. Если вам придется с ними работать, то, возможно, вас удивит их заявление, что они не агрегируют линки. Вконтакте заставят вас настроить протокол динамической маршрутизации через каждый линк ( BGP), будь у вас там их хоть 16.
Протокол LACP
Рассмотрим, как работает агрегация на примере протокола LACP.
1. Пассивный режим, при котором оборудование ждет от соседа LACPDU пакеты и только тогда начинает высылать свои.
2. Активный режим, при котором оборудование постоянно шлет LACPDU пакеты.
Для того, чтобы LACP заработал, требуется одинаковая скорость и емкость каналов.
В результате установления работы протокола LACP коммутаторы обмениваются:
• System Identifier (priority + MAC)
• Port Identifier (priority + номер порта)
• Operational Key (параметры порта)
Это требуется для того, чтобы лаг не собрался как-нибудь не так, например как показано на рисунке 2.

Балансировка трафика в лаге
Балансировка трафика осуществляется посредством выбора физического канала отправителем фрейма посредством выбранного алгоритма. К основным и часто используемым можно отнести следующие алгоритмы :


Соответственно, если в лаге будет 3 линка, то как можно догадаться при использовании данного метода равномерной балансировки добиться будет сложно и пойдет перекос по трафику на какой-либо линк. Поэтому следует относиться внимательно к выбору метода балансировки.
Основы компьютерных сетей. Тема №8. Протокол агрегирования каналов: Etherchannel
P.S. Возможно, со временем список дополнится.
Итак, начнем с простого.
Etherchannel — это технология, позволяющая объединять (агрегировать) несколько физических проводов (каналов, портов) в единый логический интерфейс. Как правило, это используется для повышения отказоустойчивости и увеличения пропускной способности канала. Обычно, для соединения критически важных узлов (коммутатор-коммутатор, коммутатор-сервер и др.). Само слово Etherchannel введено компанией Cisco и все, что связано с агрегированием, она включает в него. Другие вендоры агрегирование называют по-разному. Huawei называет это Link Aggregation, D-Link называет LAG и так далее. Но суть от этого не меняется.
Разберем работу агрегирования подробнее. 
Есть 2 коммутатора, соединенных между собой одним проводом. К обоим коммутаторам подключаются сети отделов, групп (не важен размер). Главное, что за коммутаторами сидят некоторое количество пользователей. Эти пользователи активно работают и обмениваются данными между собой. Соответственно им ни в коем случае нельзя оставаться без связи. Встает 2 вопроса:
Теперь об их отличии. Первые 2 позволяют динамически согласоваться и в случае отказа какого-то из линков уведомить об этом.
Ручное агрегирование делается на страх и риск администратора. Коммутаторы не будут ничего согласовывать и будут полагаться на то, что администратор все предусмотрел. Несмотря на это, многие вендоры рекомендуют использовать именно ручное агрегирование, так как в любом случае для правильной работы должны быть соблюдены правила, описанные выше, а коммутаторам не придется генерировать служебные сообщения для согласования LACP или PAgP.
Начну с протокола LACP. Чтобы он заработал, его нужно перевести в режим active или passive. Отличие режимов в том, что режим active сразу включает протокол LACP, а режим passive включит LACP, если обнаружит LACP-сообщение от соседа. Соответственно, чтобы заработало агрегирование с LACP, нужно чтобы оба были в режиме active, либо один в active, а другой в passive. Составлю табличку.
Теперь перейдем к лабораторке и закрепим в практической части. 
Есть 2 коммутатора, соединенные 2 проводами. Как видим, один линк активный (горит зеленым), а второй резервный (горит оранжевым) из-за срабатывания протокола STP. Это хорошо, протокол отрабатывает. Но мы хотим оба линка объединить воедино. Тогда протокол STP будет считать, что это один провод и перестанет блокировать.
Заходим на коммутаторы и агрегируем порты.
На этом настройка на первом коммутаторе закончена. Для достоверности можно набрать команду show etherchannel port-channel:
Видим, что есть такой port-channel и в нем присутствуют оба интерфейса.
Переходим ко второму устройству.
После этого канал согласуется. Посмотреть на это можно командой show etherchannel summary:
Здесь видно группу port-channel, используемый протокол, интерфейсы и их состояние. В данном случае параметр SU говорит о том, что выполнено агрегирование второго уровня и то, что этот интерфейс используется. А параметр P указывает, что интерфейсы в состоянии port-channel.
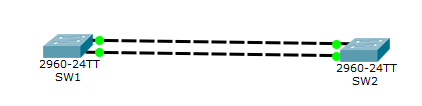
Все линки зеленые и активные. STP на них не срабатывает.
Сразу предупрежу, что в packet tracer есть глюк. Суть в том, что интерфейсы после настройки могут уйти в stand-alone (параметр I) и никак не захотят из него выходить. На момент написания статьи у меня случился этот глюк и решилось пересозданием лабы.
Теперь немного углубимся в работу LACP. Включаем режим симуляции и выбираем только фильтр LACP, чтобы остальные не отвлекали.
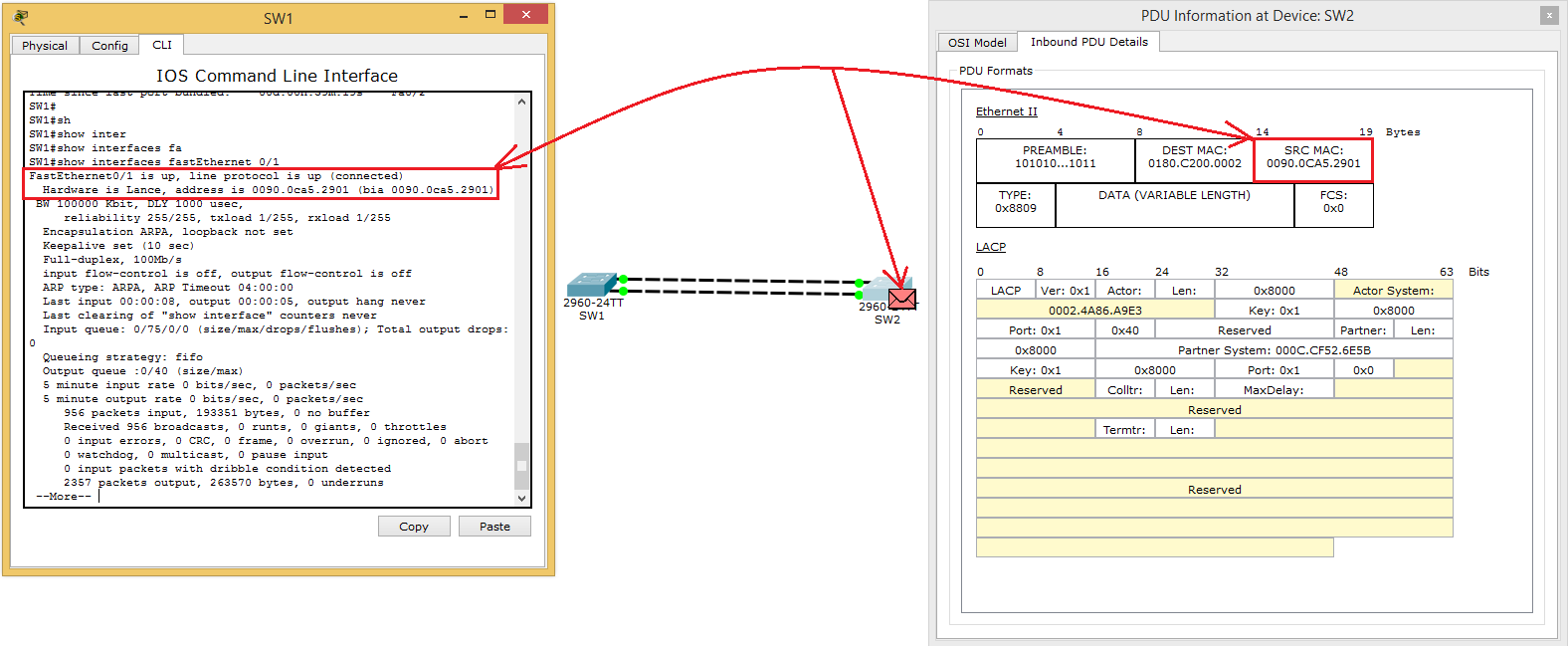
Видим, что SW1 отправляет соседу LACP-сообщение. Смотрим на поле Ethernet. В Source он записывает свой MAC-адрес, а в Destination мультикастовый адрес 0180.C200.0002. Этот адрес слушает протокол LACP. Ну и выше идет «длинная портянка» от LACP. Я не буду останавливаться на каждом поле, а только отмечу те, которые, на мой взгляд, важны. Но перед этим пару слов. Вот это сообщение используется устройствами для многих целей. Это синхронизация, сбор, агрегация, проверка активности и так далее. То есть у него несколько функций. И вот перед тем, как это все начинает работать, они выбирают себе виртуальный MAC-адрес. Обычно это наименьший из имеющихся.
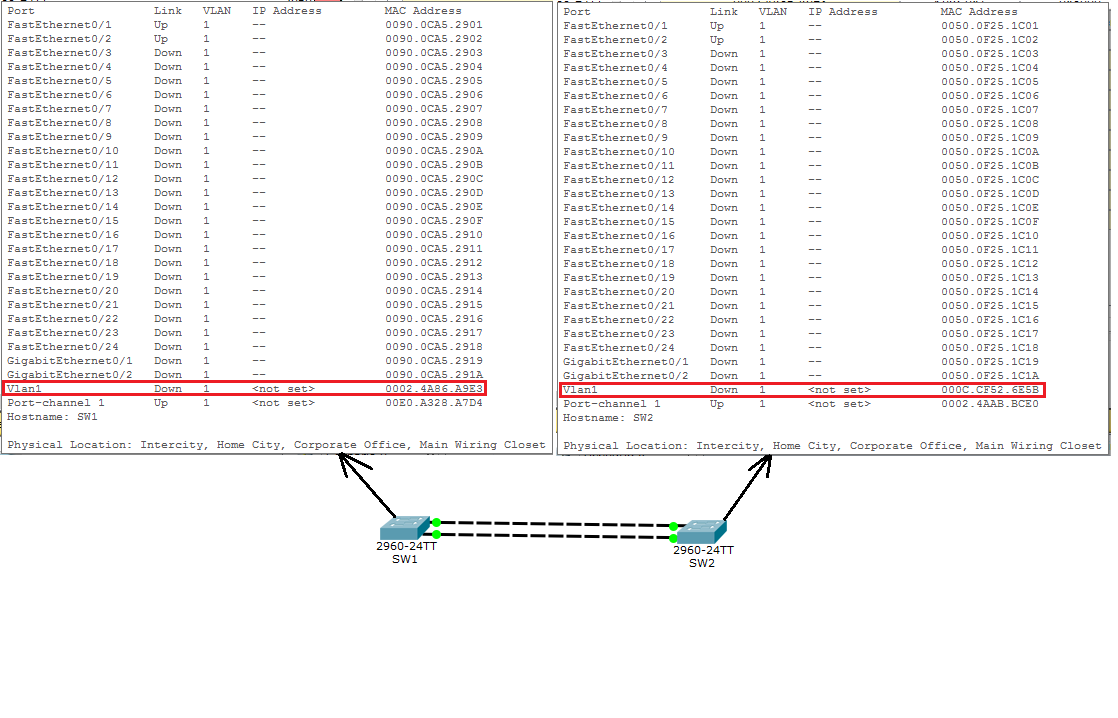
И вот эти адреса они будут записывать в поля LACP.
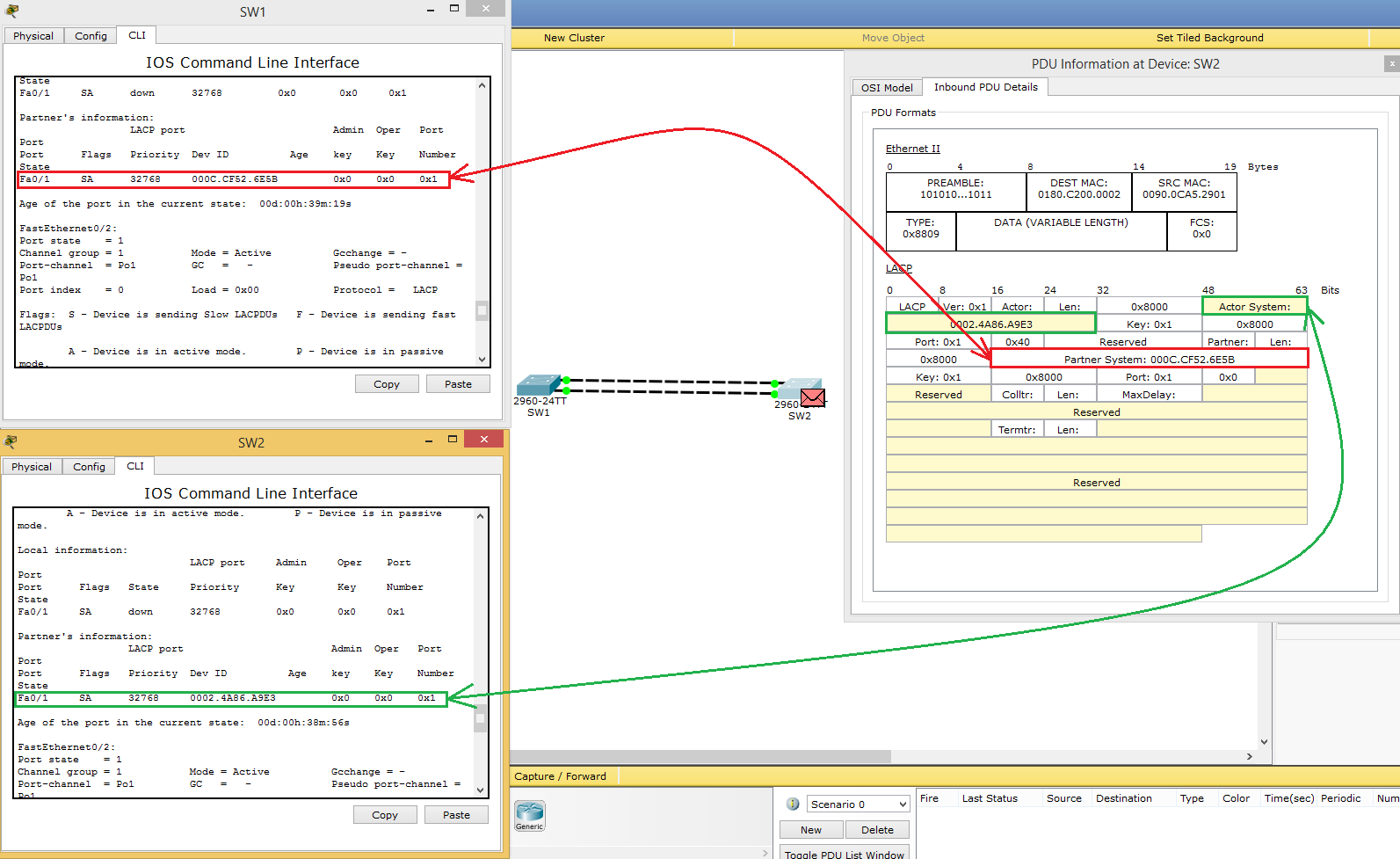
С ходу это может не сразу лезет в голову. С картинками думаю полегче ляжет. В CPT немного кривовато показан формат LACP, поэтому приведу скрин реального дампа.
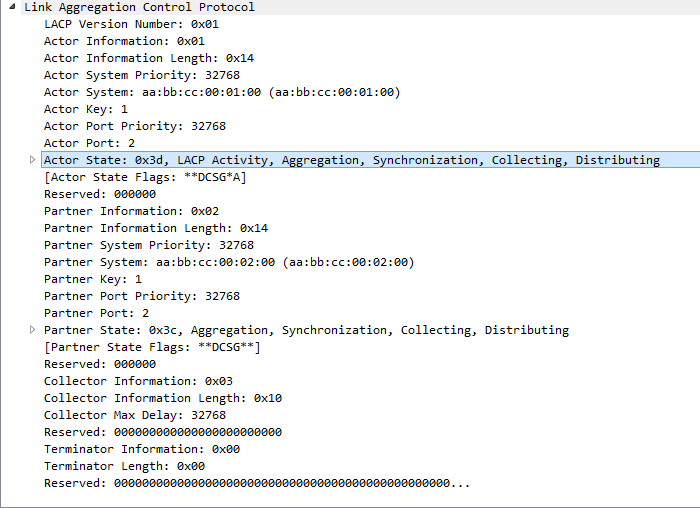
Выделенная строчка показывает для какой именно цели было послано данное сообщение. Вот суть его работы. Теперь это единый логический интерфейс port-channel. Можно зайти на него и убедиться:
И все действия, производимые на данном интерфейсе автоматически будут приводить к изменениям на физических портах. Вот пример:
Стоило перевести port-channel в режим trunk и он автоматически потянул за собой физические интерфейсы. Набираем show running-config:
И действительно это так.
Теперь расскажу про такую технологию, которая заслуживает отдельного внимания, как Load-Balance или на русском «балансировка». При создании агрегированного канала надо не забывать, что внутри него физические интерфейсы и пропускают трафик именно они. Бывают случаи, что вроде канал агрегирован, все работает, но наблюдается ситуация, что весь трафик идет по одному интерфейсу, а остальные простаивают. Как это происходит объясню на обычном примере. Посмотрим, как работает Load-Balance в текущей лабораторной работе.
На данный момент он выполняет балансировку исходя из значения MAC-адреса. По умолчанию балансировка так и выполняется. То есть 1-ый MAC-адрес она пропустит через первый линк, 2-ой MAC-адрес через второй линк, 3-ий MAC-адрес снова через первый линк и так будет чередоваться. Но такой подход не всегда верен. Объясняю почему. 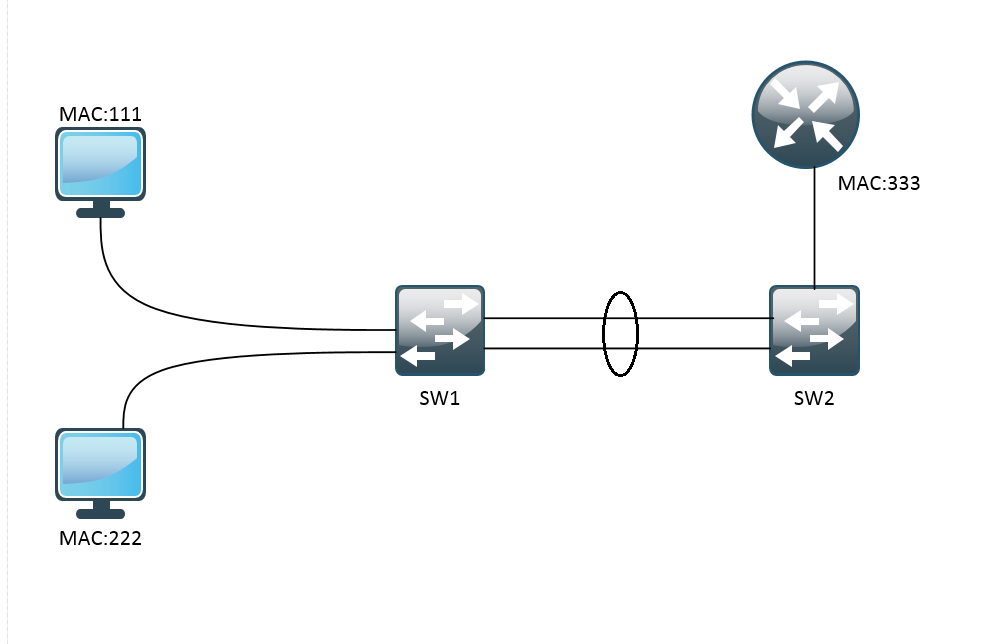
Вот есть некая условная сеть. К SW1 подключены 2 компьютера. Далее этот коммутатор соединяется с SW2 агрегированным каналом. А к SW2 поключается маршрутизатор. По умолчанию Load-Balance настроен на src-mac. И вот что будет происходить. Кадры с MAC-адресом 111 будут передаваться по первому линку, а с MAC-адресом 222 по второму линку. Здесь верно. Переходим к SW2. К нему подключен всего один маршрутизатор с MAC-адресом 333. И все кадры от маршрутизатора будут отправляться на SW1 по первому линку. Соответственно второй будет всегда простаивать. Поэтому логичнее здесь настроить балансировку не по Source MAC-адресу, а по Destination MAC-адресу. Тогда, к примеру, все, что отправляется 1-ому компьютеру, будет отправляться по первому линку, а второму по второму линку.
Это очень простой пример, но он отражает суть этой технологии. Меняется он следующим образом:
Здесь думаю понятно. Замечу, что это пример балансировки не только для LACP, но и для остальных методов.
Заканчиваю разговор про LACP. Напоследок скажу только, что данный протокол применяется чаще всего, в силу его открытости и может быть использован на большинстве вендоров.
Тем, кому этого показалось мало, могут добить LACP здесь, здесь и здесь. И вдобавок ссылка на данную лабораторку.
Теперь про коллегу PAgP. Как говорилось выше — это чисто «цисковский» протокол. Его применяют реже (так как сетей, построенных исключительно на оборудовании Cisco меньше, чем гетерогенных). Работает и настраивается он аналогично LACP, но Cisco требует его знать и переходим к рассмотрению.
У PAgP тоже 2 режима:
Теперь переходим к настройке SW2 (не забываем, что на SW1 интерфейсы выключены и следует после к ним вернуться):
Возвращаемся к SW1 и включаем интерфейсы:
Теперь переходим в симуляцию и настраиваемся на фильтр PAgP. Видим, вылетевшее сообщение от SW2. Смотрим.
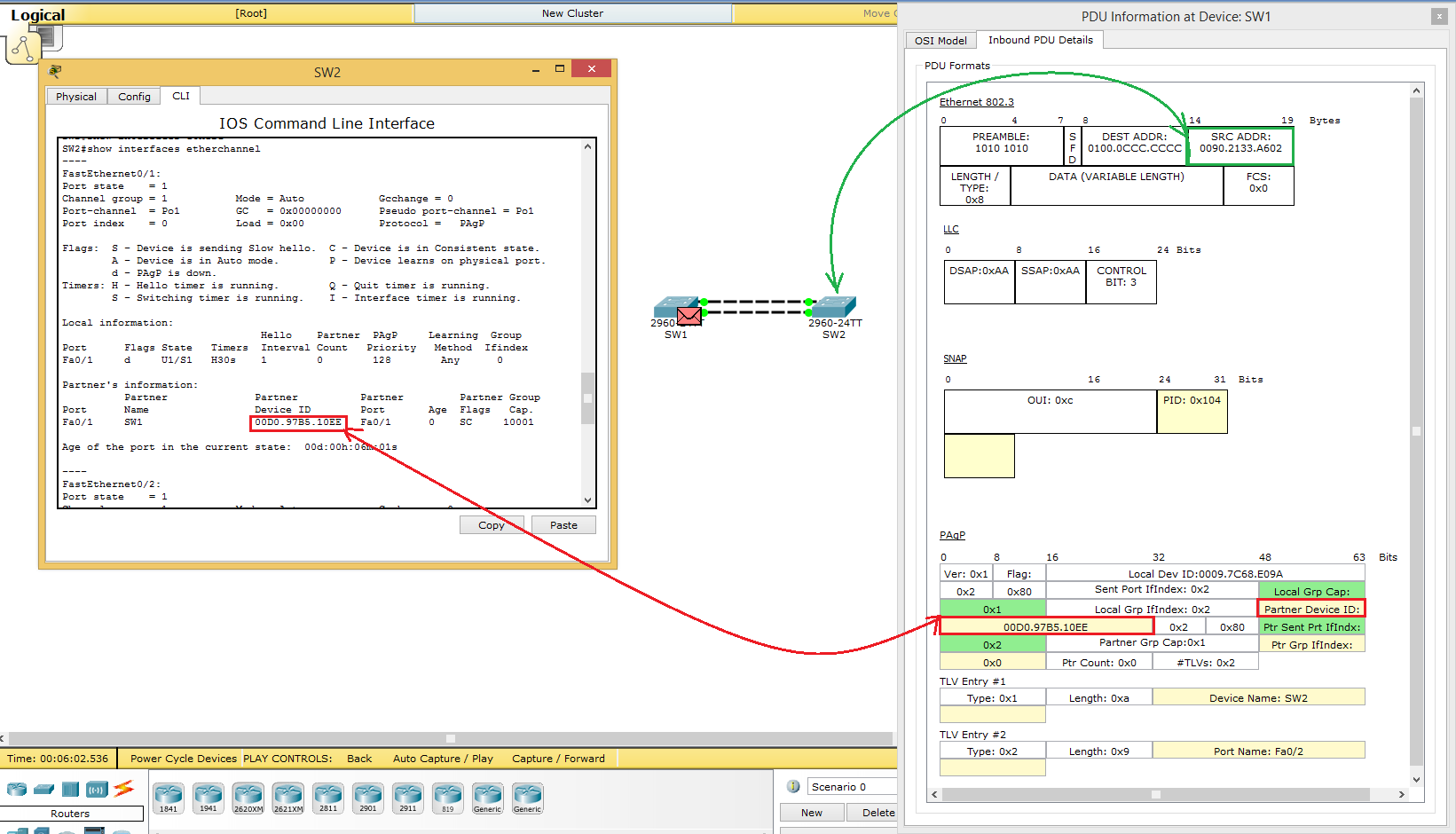
То есть видим в Source MAC-адрес SW2. В Destination мультикастовый адрес для PAgP. Повыше протоколы LLC и SNAP. Они нас в данном случае не интересуют и переходим к PAgP. В одном из полей он пишет виртуальный MAC-адрес SW1 (выбирается он по тому же принципу, что и в LACP), а ниже записывает свое имя и порт, с которого это сообщение вышло.
В принципе отличий от LACP практически никаких, кроме самой структуры. Кто хочет ознакомиться подробнее, ссылка на лабораторную. А вот так он выглядит реально:
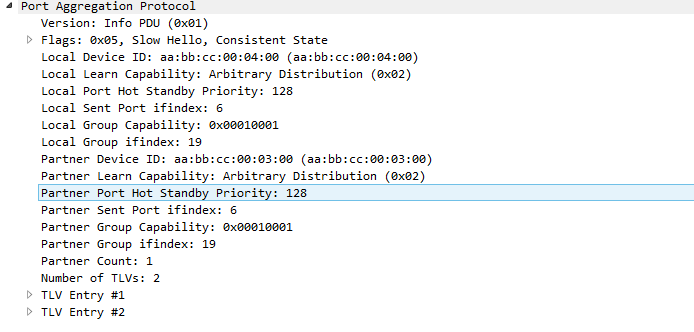
Последнее, что осталось — это ручное агрегирование. У него с агрегированием все просто:
При остальных настройках канал не заработает.
Как говорилось выше, здесь не используется дополнительный протокол согласования, проверки. Поэтому перед агрегированием нужно проверить идентичность настроек интерфейсов. Или сбросить настройки интерфейсов командой:
В созданной лабораторке все изначально по умолчанию. Поэтому я перехожу сразу к настройкам.
И аналогично на SW2:
Настройка закончена. Проверим командой show etherchannel summary:
Порты с нужными параметрами, а в поле протокол «-«. То есть дополнительно ничего не используется.
Как видно все методы настройки агрегирования не вызывают каких-либо сложностей и отличаются только парой команд.
Под завершение статьи приведу небольшой Best Practice по правильному агрегированию. Во всех лабораторках для агрегирования использовались 2 кабеля. На самом деле можно использовать и 3, и 4 (вплоть до 8 интерфейсов в один port-channel). Но лучше использовать 2, 4 или 8 интерфейсов. А все из-за алгоритма хеширования, который придумала Cisco. Алгоритм высчитывает значения хэша от 0 до 7.
| 4 | 2 | 1 | Десятичное значение |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 3 |
| 1 | 0 | 0 | 4 |
| 0 | 0 | 1 | 1 |
| 1 | 0 | 1 | 5 |
| 1 | 1 | 0 | 6 |
| 1 | 1 | 1 | 7 |
Данная таблица отображает 8 значений в двоичном и десятичном виде.
На основании этой величины выбирается порт Etherchannel и присваивается значение. После этого порт получает некую «маску», которая отображает величины, за которые тот порт отвечает. Вот пример. У нас есть 2 физических интерфейса, которые мы объединяем в один port-channel.
Значения раскидаются следующим образом:
1) 0x0 — fa0/1
2) 0x1 — fa0/2
3) 0x2 — fa0/1
4) 0x3 — fa0/2
5) 0x4 — fa0/1
6) 0x5 — fa0/2
7) 0x6 — fa0/1
8) 0x7 — fa0/2
В результате получим, что половину значений или паттернов возьмет на себя fa0/1, а вторую половину fa0/2. То есть получаем 4:4. В таком случае балансировка будет работать правильно (50/50).
Теперь двинемся дальше и объясню, почему не рекомендуется использовать, к примеру 3 интерфейса. Составляем аналогичное сопоставление:
1) 0x0 — fa0/1
2) 0x1 — fa0/2
3) 0x2 — fa0/3
4) 0x3 — fa0/1
5) 0x4 — fa0/2
6) 0x5 — fa0/3
7) 0x6 — fa0/1
8) 0x7 — fa0/2
Здесь получаем, что fa0/1 возьмет на себя 3 паттерна, fa0/2 тоже 3 паттерна, а fa0/3 2 паттерна. Соответственно нагрузка будет распределена не равномерно. Получим 3:3:2. То есть первые два линка будут всегда загруженнее, чем третий.
Все остальные варианты я считать не буду, так как статья растянется на еще больше символов. Можно только прикинуть, что если у нас 8 значений и 8 линков, то каждый линк возьмет себе по паттерну и получится 1:1:1:1:1:1:1:1. Это говорит о том, что все интерфейсы будут загружены одинаково. Еще есть некоторое утверждение, что агрегировать нужно только четное количество проводов, чтобы добиться правильной балансировки. Но это не совсем верно. Например, если объединить 6 проводов, то балансировка будет не равномерной. Попробуйте посчитать сами. Надеюсь алгоритм понятен.
У Cisco на сайте по этому делу есть хорошая статья с табличкой. Можно почитать по данной ссылке. Если все равно останутся вопросы, пишите!
Раз уж так углубились, то расскажу про по увеличение пропускной способности. Я специально затронул эту тему именно в конце. Бывают случаи, что срочно нужно увеличить пропускную способность канала. Денег на оборудование нет, но зато есть свободные порты, которые можно собрать и пустить в один «толстый» поток. Во многих источниках (книги, форумы, сайты) утверждается, что соединяя восемь 100-мегабитных портов, мы получим поток в 800 Мбит/с или восемь гигабитных портов дадут 8 Гбит/с. Вот кусок текста из «цисковской» статьи.

Теоретически это возможно, но на практике почти недостижимо. Я по крайней мере не встречал. Если есть люди, которые смогли этого добиться, я буду рад услышать. То есть, чтобы это получить, нужно учесть кучу формальностей. И вот те, которые я описывал, только часть. Это не значит, что увеличения вообще не будет. Оно, конечно будет, но не настолько максимально.
На этом статья подошла к концу. В рамках данной статьи мы научились агрегировать каналы вручную, а также, при помощи протоколов LACP и PAgP. Узнали, что такое балансировка, как ею можно управлять и как правильно собирать Etherchannel для получения максимального распределения нагрузки. До встречи в следующей статье!
Агрегация интернет-каналов через операторов сотовой связи

Приятно иметь в поездке надежный и быстрый интернет, особенно когда ехать придется не один час! Если путь пролегает в густонаселенном районе — на любом современном телефоне с поддержкой сетей 4G, обычно всё просто работает, мы продолжаем пользоваться интернетом, как привыкли. Естественно, всё меняется, когда выезжаешь за пределы населенных пунктов.
В движущийся транспорт интернет можно подать только двумя путями:
Бюджета на создания своей инфраструктуры для передачи данных никто в здравом уме, конечно же, не выделит, поэтому в распоряжении есть только спутниковый канал и инфраструктура «сотовиков». Выбор еще раз упростился, когда финмодель заказчика не выдержала реализации через спутниковый канал. Поэтому дальше речь пойдет о том, как подать в движущийся транспорт максимально устойчивый канал через операторов сотовой связи.
Суть агрегации каналов передачи данных можно выразить коротко: суммировать емкость, предоставленную разными физическими линиями. Условно, если у нас есть четыре канала емкостью 1 Мбит/с каждый, на выходе мы должны получить один канал емкостью 4 Мбит/с. В нашем случае есть четыре оператора сотовой связи, через каждый из них в пределе можно выжать до 70 Мбит/с, а в сумме, если звезды сойдутся правильно, — 280 Мбит/с.
Кто-то скажет, что 280 Мбит/с никак не хватит на всех пассажиров поезда, коих в среднем 700 человек, и что получить такую скорость за пределами населенных пунктов нельзя. Более того, там, где связи нет совсем, никакой магии не произойдет: в транспорте также связи не будет. Конечно, этот кто-то совершенно прав. Поэтому мы решаем задачу не комфортного канала для всех, а хоть какого-то — там, где обычные смартфоны физически не в состоянии установить связь.
Этот пост о том, как нам пришлось с нуля изобрести велосипед, чтобы добыть интернет в автомобильном и железнодорожном транспорте для одного индийского оператора железнодорожных путей, как мы фиксировали перемещения этого транспорта и качество канала передачи данных в каждой точке пути с последующим хранением в кластере Tarantool.
Суть проекта
Агрегация решает задачу отказоустойчивости и/или суммирования емкости каналов передачи данных, участвующих в агрегации. В зависимости от типа агрегации, топологии сети и оборудования реализация может кардинально отличаться.
Каждый тип агрегации достоин отдельной статьи, но у нас конкретная задача: насколько возможно, обеспечить надежным и максимально «широким» каналом ПД транспортные средства.

Инфраструктура операторов сотовой связи дает основу для задачи:
Технически агрегация очень проста и многократно описана, вы без труда сможете найти информацию любой глубины изложения. Вкратце суть такая.
Со стороны клиентского оборудования:
Необходимость самостоятельно анализировать каналы через разных операторов сотовой связи с мониторингом уровня сигнала оператора, типа связи, информации о загрузке базовой станции, ошибок в сети передачи данных оператора (не путать с L3-тоннелем) и на основе этих метрик распределять поток данных разрешает Google сообщить нам, что придется писать решение самостоятельно.
К слову, есть решения разного уровня приемлемости, в которых агрегация работает. Например, стандартный bonding интерфейсов в Linux. Поднимаем L3-тоннель через любой доступный инструментарий, хоть через VPN-сервер или SSH-тоннель, настраиваем вручную маршрутизацию и добавляем в бондинг виртуальные интерфейсы тоннелей. Всё будет нормально, пока емкость тоннелей в каждый момент времени одинакова. Дело в том, что при такой топологии сети работает только режим агрегации balance-rr, т. е. в каждый тоннель попадает равное количество байтов по очереди. Это значит, что если у нас будет три канала емкостью (Мбит/с) 100, 100 и 1, то результирующая емкость окажется 3 Мбит/с. То есть минимальная ширина канала умножается на количество каналов. Если емкость — 100, 100, 100, то результирующая будет 300.
Есть другое решение: прекрасный opensource-проект Vtrunkd, который после долгого забвения был реанимирован в 2016 году. Там уже есть почти всё, что нужно. Мы честно написали создателям, что готовы заплатить за доработку решения в части мониторинга метрик качества связи сотовых операторов и включить эти метрики в механизм распределения трафика, но ответа, к сожалению, так и не получили, поэтому решили написать свой вариант с нуля.
Qedr Summa
Начали с мониторинга метрик операторов сотовой связи (уровень сигнала, тип сети, ошибки сети и т. д.) Нужно отметить, что модемы выбирались как раз исходя из того, как хорошо они могут отдавать метрики операторов. Мы выбрали модем SIM7100 производства компании Simcom. Все интересующие нас метрики отдаются через обращение в последовательный порт. Этот же модем также отдает GPS/ГЛОНАСС-координаты с хорошей точностью. Также необходимо отслеживать статус метрик компьютера (температуру CPU, SSD, свободное количество оперативной памяти и дискового пространства, S.M.A.R.T. показатели SSD). Отдельно модуль мониторит статистику сетевых интерфейсов (наличие ошибок на прием и отправку, длина очереди на отправку, количество переданных байтов). Поскольку производительность устройства крайне ограничена и пакет передаваемых данных должен быть минимален, а также учитывая простоту мониторинга этих метрик под Linux через /proc/sys, вся подсистема мониторинга также была разработана с нуля.
После того как модуль мониторинга метрик был готов, приступили к сетевой части: программной агрегации каналов. К сожалению, детальный алгоритм — коммерческая тайна, опубликовать его я не могу. Всё же опишу в общих чертах, как работает модуль агрегации, установленный в транспорте:
Серверная часть агрегации работает радикально проще. При старте модуль агрегации обращается к серверу настроек, получает конфигурацию в JSON-формате и на ее основе запускает L3-интерфейсы. В целом всё тривиально.
Отдельно стоит описать систему сбора и визуализации всех метрик проекта. Она поделена на две большие части. Первая часть — мониторинг систем жизнеобеспечения клиентского и серверного оборудования. Вторая — мониторинг бизнес-метрик работы проекта.
Стек технологий проекта стандартный. Визуализация: Grafana, OpenStreetMap, сервер приложений на клиентской и серверной стороне: Go, СУБД Tarantool.
Tarantool
История эволюции СУБД в наших проектах начинается с PostgreSQL в 2009 году. Мы успешно хранили в нем геоданные от бортовых устройств, установленных на спецтранспорте. Модуль PostGIS вполне справлялся с задачами. Со временем очень сильно стало не хватать производительности в обработке данных без схемы хранения. Экспериментировали с MongoDB c версии 2.4 до версии 3.2. Пару раз не смогли восстановить данные после аварийного отключения (полностью дублировать данные не позволял бюджет). Далее обратили внимание на ArangoDB. Если учесть, что бэкенд в то время мы писали на JavaScript, стек технологий выглядел очень приятно. Однако и эта базейка, побыв с нами добрые два года, ушла в прошлое: мы не смогли контролировать потребление оперативной памяти на больших объемах данных. В этом проекте обратили внимание на Tarantool. Ключевым для нас было следующее:
На первый взгляд, всё в ней хорошо, за исключением того, что работает она только на одном ядре процессора. Ради науки провели ряд экспериментов, чтобы понять, будет ли это препятствием. После тестов на целевом железе убедились, что для этого проекта СУБД справляется с обязанностями прекрасно.
У нас всего три основных профиля данных: это финансовые операции, временные ряды (т. е. журналы работы систем) и геоданные.
Финансовые операции — это информация о движении денег по лицевому счету каждого устройства. Любое устройство имеет как минимум три SIM-карты от разных операторов связи, поэтому нужно контролировать баланс лицевого счета у каждого оператора связи и, чтобы не допустить отключения, заранее знать, когда пополнить баланс для каждого оператора каждого устройства.
Временные ряды — просто журналы мониторинга от всех подсистем, включая журнал совокупной пропускной полосы для каждого устройства в транспорте. Это дает нам возможность знать, в какой точке пути какой был канал по каждому оператору. Эти данные используются для аналитики покрытия сетью, что, в свою очередь, нужно для упреждающего переключения и развесовки каналов по операторам связи. Если мы заранее знаем, что в конкретной точке у такого-то оператора худшее качество, мы заранее отключаем этот канал из агрегации.
Геоданные — простой трек транспортного средства по пути следования. Каждую секунду мы опрашиваем GPS-датчик, встроенный в модем, и получаем координаты и высоту над уровнем моря. Трек длительностью 10 минут собирается в пакет и отправляется в ЦОД. По требованию заказчика эти данные должны храниться вечно, что при возрастающем количестве транспортных средств заставляет заранее очень серьезно планировать инфраструктуру. Однако в Tarantool шардинг сделан очень просто, и ломать голову над масштабированием хранилища под самые быстрорастущие данные никакой необходимости нет. Резервная копия данных не пишется, поскольку исторической ценности сейчас в этих данных нет.
Для всех типов данных мы использовали движок Vinyl (хранение данных на диске). Финансовых операций не так много, и нет смысла всегда хранить их в памяти, как и журналы, естественно, и геоданные, пока по ним не будет производиться аналитика. Когда аналитика потребуется, в зависимости от требований к быстродействию, возможно, будет иметь смысл подготовить уже агрегированные данные и хранить их на движке InMemory, а далее анализировать эти данные. Но всё это начнется, когда заказчик сформирует свои требования.
Важно отметить, что Tarantool прекрасно справился с нашей задачей. Он одинаково комфортно себя чувствует на ограниченном в ресурсах устройстве и в ЦОДе на десять шардов. Спецификация устройств, которые стоят в транспорте:
CPU: ARMv8, 4Core, 1.1 Ghz
RAM: 2 Gb
Storage: 32 GB SSD
Спецификация сервера ЦОДа:
СPU x64 Intel Corei7, 8Core, 3.2 Ghz
RAM: 32 Gb
Storage: 2 × 512 Gb (Soft Raid 0)
Как я уже говорил, репликация данных из транспорта в ЦОД налажена средствами самой СУБД. Шардинг данных между десятью шардами — также функционал «из коробки». Вся информация присутствует на сайте Tarantool, и описывать это тут, думаю, не нужно. В настоящий момент система обслуживает всего 866 транспортных средств. Заказчик планирует расширение до 8 тысяч.



