Интерпретатор языка Python, написанный на языке Python
Оригинал: A Python Interpreter Written in Python
Автор: Allison Kaptur
Дата публикации: July 12, 2016
Перевод: Н.Ромоданов
Дата перевода: февраль 2017 г.
Введение
Byterun является интерпретатором языка Python, реализованным на языке Python. Хотя я участвовала в разработке ByteRun, я была удивлена и обрадована, когда обнаружила, что основная структура интерпретатора языка Python достаточно просто соответствует ограничению в 500 строк. В этой главе мы рассмотрим эту структуру интерпретатора и расскажем о ней достаточно подробно с тем, чтобы вы могли изучать ее дальше. Цель главы не в том, чтобы объяснить все, что известно об интерпретаторах – подобно многим другим интересным темам в программировании и информатике, для глубокого понимания этой темы могут потребоваться годы обучения.
Интерпретатор языка Python
Прежде чем мы начнем, давайте сузим понятие того, что мы будем подразумевать под понятием «интерпретатором языка Python». Понятие «интерпретатор» при обсуждении языка Python может использоваться в различных смыслах. Иногда понятие интерпретатор относится к Python REPL, интерактивной командной строке и приглашению, которое вы получите, когда в командной строке наберете команду python. Иногда, когда говорят о выполнении кода на языке Python от самого начала до конца, понятие «интерпретатор языка Python» будет более или менее взаимозаменяемо с понятием «язык Python». В этой главе, понятие «интерпретатор» имеет более узкое значение: это последний шаг в процессе выполнения программы на языке Python.
Перед тем как интерпретатор примет на себя эстафету, необходимо выполнить три других действия: лексический анализ, синтаксический анализ и компиляция. Вместе эти шаги преобразуют исходный код, написанный программистом, из текстовых строк в структурированные объекты кода, содержащий инструкции, которые может понять интерпретатор. Работа интерпретатора заключается в том, что он должен брать эти объекты кода и следовать указанным в них инструкциям.
Вы удивитесь, узнав, что компиляция вообще является одним из шагов в выполнении кода на языке Python. Язык Python часто называют «интерпретируемым» языком точно таким, как язык Ruby или язык Perl, в отличие от таких «компилируемых» языков, как C или Rust. Тем не менее, эта терминология не столь точна, как это может показаться. В наиболее известных интерпретируемых языках, в том числе и в языке Python, действительно, есть стадия компиляции. Причина того, что язык Python называется «интерпретируемым», в том, что на шаге компиляции делается меньше работы (а интерпретатор выполняет больше работы), чем в компилируемом языке. Далее в этой главе будет рассказано о том, компилятор языка Python имеет гораздо меньше информации о поведении программы, чем компилятор языка С.
Интерпретатор языка Python, написанный на языке Python
Byterun является интерпретатором языка Python, который написан на самом языке Python. Это может показаться странным, но это не более странно, чем писать компилятор языка С на языке С. На самом деле широко используемый компилятор gcc для языка С написан на самом языке C. Вы можете написать интерпретатор языка Python практически на любом языке программирования.
Написание интерпретатора языка Python на самом языке Python обладает как преимуществами, так и недостатками. Самым большим недостатком будет скорость выполнения программы: выполнение кода с помощью интерпретатора Byterun происходит гораздо медленнее, чем его выполнение с помощью интерпретатора CPython, который написан на языке C и тщательно оптимизирован. Но интерпретатор Byterun был разработан первоначально как учебное упражнение, так что для нас скорость не так важна. Самым большим преимуществом использования языка Python является то, что гораздо проще реализовывать лишь интерпретатор, а не весь остальной контекст времени выполнения, в частности, реализовывать систему объектов. Например, в случае, когда необходимо создать класс, интерпретатор Byterun может воспользоваться «реальным» языком Python. Еще одним преимуществом является то, что интерпретатор Byterun понять проще, отчасти потому, что он написан на языке высокого уровня (Python!), который, как многие считают, читается легче. Мы также убрали из интерпретатора Byterun всю оптимизацию периода интерпретации, отдав предпочтение ясности и простоты над скоростью.
Краткая история Python
Сейчас язык Python похож на классический гамбургер: он есть везде и все о нём знают. Кто бы мог подумать, но вначале был бутерброд… 🍔


Невозможно с нуля создать язык программирования, который получит мировую известность. Вот небольшая часть алгоритма, который может сработать:
Всё перечисленное удалось Гвидо ван Россуму — основателю Python. Сегодня мы поговорим об этом подробнее и рассмотрим события, которые повлияли на один из самых популярных языков программирования в мире.

Автор статей о программировании. Изучает Python, разбирает сложные термины и объясняет их на пальцах новичкам. Если что-то непонятно — возможно, вы ещё не прочли его следующую публикацию.
Язык ABC
В 1982 году Гвидо ван Россум окончил университет и попал в команду разработчиков института CWI, где до 1986 года занимался проектированием языка ABC — прототипа Python. ABC задумывался как инструмент для пользователей, которые до этого не программировали и не разбирались в устройстве компьютеров. Должен был получиться удобный язык с простым синтаксисом, на котором легко учиться писать программы.
В 1987 году проект ABC закрылся. По мнению Гвидо, главная причина заключалась в отсутствии доступного интернета — язык медленно распространялся и не получал оперативной обратной связи от пользователей. Из-за этого команда не добавляла улучшения, которые учитывали бы потребности разработчиков. Сами программисты не могли присоединиться к сообществу и поучаствовать в развитии проекта. Язык ABC опередил своё время и мог стать заменой Python.
После неудачного опыта с ABC Гвидо ван Россум оценил силу сообщества. Он понял, что язык программирования не может развиваться без обратной связи, — нужна система, в которой каждый разработчик будет предлагать улучшения или голосовать за предложения других участников сообщества.
Так в Python появился PEP-индекс — задокументированный регламент по внесению изменений в структуру и синтаксис языка. Любой разработчик может в письменной форме предложить улучшения, аргументировать их ценность и отправить текст на проверку редакторам Python-сообщества.
Если предложение пройдёт предварительную проверку, то оно появится на python.org — официальном сайте сообщества. Все участники смогут изучить его, обсудить будущую ценность и проголосовать за изменения. Если большинство будет «за», внесённое предложение вступит в силу.
Рождество 1989-го
В 1986 году Гвидо оставался сотрудником CWI, но перешёл из ABC в проект Amoeba — там он разрабатывал операционную систему для крупных организаций. Amoeba объединяла сеть пользовательских компьютеров в единую станцию и оптимизировала их совместную работу над производительными задачами.
В 1989 году системе Amoeba не хватало языка сценариев, поэтому Гвидо ван Россум планировал мини-проект: собирался написать язык программирования на основе наработок ABC. В период рождественских праздников Гвидо сделал первые наброски и вскоре показал коллегам прототип будущего Python.
Первый прототип состоял из простой виртуальной машины, парсера и среды выполнения. В нём также присутствовал базовый синтаксис, операторы, словари, списки, строки и небольшое количество других типов данных. Главная фишка заключалась в том, что будущий Python предлагал гибкую модель расширяемости — то есть, помимо стандартных возможностей, каждый программист мог самостоятельно добавить в систему нужные типы объектов.
Прототип Python понравился разработчикам CWI, и многие сразу включились в процесс: начали использовать язык для внутренних проектов и помогли доработать код.
20 февраля 1991 года Гвидо ван Россум создал дистрибутив и опубликовал код языка Python через сеть Usenet. Так появилась версия 0.9.0.
Гвидо ван Россум запускал Python в качестве Skunkworks-проекта — тестовой технологии, которая разрабатывается без бюджета силами энтузиастов. Для финансирования требовался быстрый рабочий прототип, который на практике доказал бы пользу нового языка программирования.
Гвидо работал над прототипом в свободное время и получил результат примерно через три месяца. Для этого ему пришлось придерживаться правил, на основе которых позже опубликовали «Руководство по стилю» и «Дзен Python».
Основная мысль руководства: язык программирования должен быть простым, кратким и достаточно хорошим для того, чтобы справляться с нужными задачами. Не нужно стремиться к максимальной производительности и совершенству — в большинстве случаев перфекционизм приводит к пустой трате времени.
«Цирк Монти Пайтона»
Гвидо ван Россум не мог опубликовать дистрибутив без названия. Для языка ABC название придумывали долго, стремясь подчеркнуть идею проекта. Хотели объяснить, что программирование бывает таким же простым, как чтение азбуки, — учишь букву «А», потом «B», «C» и так далее.
Гвидо же считал нейминг пустой тратой времени и поэтому назвал свой язык в честь комедийного сериала «Летающий цирк Монти Пайтона» — это одно из его любимых шоу и первая ассоциация, которая пришла ему в голову.
Вместе с названием для нового языка нужно было придумать логотип, и Гвидо поступил так же просто: случайно выбрал шрифт и написал слово «Python».
Шрифтовой логотип просуществовал до 2006 года и изменился только потому, что многим пользователям нравилось ассоциировать Python со змеями — они появлялись на обложках книг по программированию, в журналах и на сайтах. Шрифтовым вариантом мало кто пользовался — все рисовали разных питонов. Чтобы избежать путаницы, создали новый логотип, на котором синий и жёлтый питоны соседствуют с обновлённой шрифтовой надписью «Python».
История с неймингом показывает консерватизм, с которым Гвидо ван Россум развивал Python-сообщество. Он не верил в маркетинг и считал, что хороший продукт не нуждается в рекламе. В одном из интервью Гвидо сделал предположение, что если вернуться в прошлое и доверить выбор названия специалистам, то они запросят неприличную сумму, долго будут обсуждать какую-то мудрёную концепцию и вряд ли выберут «Python».
С одной стороны, логотип на коленке и случайное название не помешали Гвидо создать один из самых востребованных языков программирования. Обратная сторона медали заключается в том, что без активного продвижения взрывной интерес к Python начался только после 2004 года — через 13 лет после публикации дистрибутива. Если бы в этот период существовал более мощный и свежий сценарный язык программирования, то Python мог и не стать популярным.
Кроме нейминга и продвижения, консерватизм Гвидо ван Россума повлиял и на техническую часть развития Python-сообщества. В первом разделе мы говорили, что каждый участник может оформить PEP-индекс и предложить улучшения. Нюанс в том, что большинство предложений не принимаются: если что-то работает и программист предлагает не лучшее из решений, то Гвидо рекомендует не переписывать исходный код. Поэтому Python обрастает библиотеками и ограничен в базовых возможностях.
Автобус-убийца
29 июня 1994 года на форуме вышла статья «Если бы Гвидо сбил автобус?». Публикация затронула проблему зависимости Python-сообщества от решений Гвидо ван Россума — автор поделился мнением о том, что крупные компании опасаются использовать технологии, которые привязаны к одному человеку.
К моменту публикации статьи вышло несколько версий Python 1.0. В этот период Гвидо собирал большую часть обратной связи с форумов и из электронных писем, а затем на своё усмотрение выбирал обновления для следующего релиза.
Автором упомянутой статьи был Майкл Маклей из Национального института стандартов и технологий США (NIST). Он пригласил Гвидо для совместной работы, и это привело к появлению в 1995 году Python Software Foundation — некоммерческой организации, которая должна была отвечать за защиту и развитие языка Python. У этой организации появилось несколько руководителей, а Гвидо ван Россум получил шуточный титул великодушного пожизненного диктатора (Benevolent Dictator For Life).
Появление Python Software Foundation стало первым шагом к сильному Python-сообществу, которое не зависит от единоличных действий Гвидо ван Россума. Сейчас все стратегические решения принимаются коллективно, а контроль за соблюдением порядка осуществляет совет руководителей — временный орган, который регулярно переизбирается и состоит из пяти человек. Если с одним руководителем что-то случится, его место займёт кто-то другой. На развитие Python-сообщества это не повлияет.
В 2018 году Гвидо ван Россум отказался от титула BDFL, помог наладить работу совета руководителей и продолжает развивать Python-сообщество в качестве разработчика. В конце 2019 года он просил участников сообщества не поддерживать его кандидатуру и не включать его в совет руководителей. Гвидо поддержал других кандидатов и сделал язык Python полностью независимой технологией, которая больше не нуждается в основателе.
Python 2.6 → Python 3.0
3 декабря 2008 года появилась третья версия Python, которая устраняла критические неисправности и перерабатывала архитектуру языка. Из-за большого количества изменений вторая и третья версии оказались не полностью совместимыми и до 2020 года развивались по отдельности. С конца 2020 года официальное Python-сообщество поддерживает только третью версию.
Вторая версия Python появилась в 2000 году, а третья — в 2008 году. Восемь лет компании создавали программы, библиотеки и приложения, которые после обновления пришлось полностью или частично переводить на Python 3.0.
Чтобы облегчить компаниям переход, Python-сообщество 12 лет выпускало обновления для старой версии. Теперь большая часть кода написана на третьей версии — и разработчики боятся повторения ситуации с Python 4.0.
В старом блоге Гвидо ван Россума есть запись, где он сравнивает дизайн языков программирования с книгами о Гарри Поттере. Заметка написана в 2005 году, и, на мой взгляд, она даёт универсальный ответ на все вопросы, касающиеся целесообразности обновления Python в прошлом или будущем.
Гвидо пишет, что когда Джоан Роулинг создавала первую книгу поттерианы, то не могла сразу проработать детали для остальных шести частей. По этой причине некоторые сюжетные линии стали заложниками истории первой книги.
Например, Гвидо не понравилась анаграмма с именем Том Марволо Реддл, из которого получился «лорд Волан-де-Морт». По его мнению, Том Реддл не звучит как зловещее имя для бессмертного тёмного мага. Просто Джоан использовала имя Волан-де-Морт в первой части и не могла его изменить.
С Python похожая история: язык развивался постепенно и долгое время не обладал мощной поддержкой сообщества и средствами для найма постоянной команды разработчиков. Поэтому некоторые первоначальные решения оказались неверными и, чтобы исправить ситуацию, понадобился Python 3.0.
Гвидо ван Россум уверяет, что разработчикам не стоит опасаться Python 4.0. Пока новой версии нет в планах, но даже если она когда-то появится, то переход будет безболезненным, потому что язык больше не страдает критическими уязвимостями. Разработчики получат всё для быстрой адаптации кода.
Что дальше
В 2021 году языку Python исполнилось 30 лет. За это время он превратился из домашнего прототипа в мировой язык программирования. Самое важное — с 2019 года Python полностью независим от основателя и развивается силами сообщества. А это означает стабильность на протяжении долгого будущего.
Если хотите узнать больше об истории Python — начните с этого:
Как закончите, приходите учиться и присоединяйтесь к Python-сообществу.
Doc Searls / Flickr / dwi putra stock / Olga Popova / Shatterstock / Polina Vari для Skillbox
Разборки в террариуме. Изучаем виды интерпретаторов Python
Содержание статьи
На самом деле Python — это далеко не один конкретный интерпретатор. Действительно, чаще всего мы имеем дело с так называемым CPython, который можно назвать эталонной реализацией (reference implementation) — интерпретатором, на который все остальные должны равняться. Это означает, что CPython максимально полно и быстро реализует те вещи, которые уже прописаны и добавляются с течением времени в стандарт языка, содержащийся во всякого рода спеках и PEP’ах. И именно эта реализация находится под пристальным вниманием «великодушного пожизненного диктатора» (это реально существующий термин, не веришь — глянь в Википедии) и создателя языка Гвидо ван Россума.
Но все сказанное вовсе не значит, что нельзя просто так взять и воплотить свою собственную реализацию описанных стандартов, равно как ничто не мешает написать, к примеру, свой компилятор для C++. Собственно, довольно большое число разработчиков именно так и сделали. О том, что у них получилось, я и хочу рассказать.
Чтобы понять Python, надо понять Python
Одна из самых известных альтернативных реализаций Python — это PyPy (бывший Psyco), который часто называют питоном, написанным на питоне. У всех, кто слышит подобное определение, возникает закономерный вопрос — как то, что написано на том же языке, может быть быстрее, чем сам язык? Но мы выше уже сошлись на том, что Python — это общее название группы стандартов, а не конкретной реализации. В случае с PyPy мы имеем дело не с CPython, а с так называемым RPython — это даже не совсем диалект языка, это, скорее, платформа или фреймворк для написания своих собственных интерпретаторов.
В столкновениях поклонников лагерей Python и Ruby один из аргументов питонистов — это то, что разработчики, которых не устраивала скорость работы языка Ruby, написали якобы более быструю реализацию на RPython. Получился вполне интересный проект под названием Topaz.
RPython привносит немного низкоуровневой магии, которая позволяет при правильном подборе ингредиентов (прямые руки обязательны, глаз тритона — нет) добавить разные полезные плюшки в произвольный интерпретируемый язык (необязательно Python) — например, ускорение за счет JIT. Если хочется больше подробностей об этой штуке, а также если ты сейчас подумал что‑то вроде «а как же LLVM?» — добро пожаловать в FAQ.
Общая мысль заключается в том, что RPython — слишком специфическая реализация для того, чтобы прямо на нем писать боевые программы. Проще и удобнее взять PyPy, даром что он полностью совместим с CPython 2.7 и 3.3 в плане поддерживаемых стандартов. Правда, в силу специфики внутреннего устройства на нем пока что трудновато заставить работать те библиотеки для эталонной реализации, которые используют компилируемые си‑модули. Но, к примеру, Django уже вполне поддерживается, причем во многих случаях бегает быстрее, чем на CPython.
Еще в качестве одной из полезных особенностей PyPy можно назвать его модульность и расширяемость. Например, в него встроена поддержка sandboxing’а — можно запускать «опасный» произвольный код внутри виртуального окружения, даже с эмуляцией файловой системы и запретом на внешние вызовы вроде создания сокетов. А еще в последнее время довольно активно развивается проект PyPy-STM, который позволяет заменить встроенную поддержку многопоточности (ту самую, с GIL и прочими нелюбимыми вещами) на реализацию, работающую через Software Transactional Memory, — то есть с абсолютно другим механизмом разруливания конкурентного доступа.
Это не совсем относится к теме статьи, но если тебя заинтересовала информация об RPython — крайне рекомендую взглянуть еще на один проект по «более скоростному запуску» Python. Он называется Nuitka и позиционирует себя как «компилятор Python в C++». Правда, любопытно?
Нижний уровень
Кроме RPython + PyPy, есть и более простой способ ускорить выполнение кода на Python — выбрать один из оптимизирующих компиляторов, который расширяет стандарты языка, добавляя более строгую статическую типизацию и прочие низкоуровневые вещи. Как я выше упомянул, RPython (даже притом, что названное определение к нему тоже относится) является слишком специфичным инструментом для конкретных задач, но есть проект и более общего применения — cython.
Его подход заключается в добавлении фактически нового языка, являющегося чем‑то промежуточным между C и Python (за основу был взят проект Pyrex, который практически не развивается с 2010 года). Обычно исходные файлы с кодом на этом языке имеют расширение pyx, а при натравлении на них компилятора превращаются во вполне обычные C-модули, которые можно тут же импортировать и использовать.
Код с декларацией типов будет выглядеть как‑то так:
В простейшем варианте для такого модуля пишется setup.py примерно с таким содержанием:
И да, это фактически все, больше ничего в общем случае делать не надо.
Кстати, если кто‑то сейчас начнет возмущаться, что все типы давно уже есть в Numpy и не надо придумывать новый язык, — рекомендую почитать вот эту ссылку. Суть в том, что разработчики проекта активно работают над совместным использованием и того и другого, что позволяет на некоторых задачах получить довольно серьезный прирост производительности.
Змея в коробке
Так уж вышло, что упомянутый автор и BDFL оригинальной реализации Python Гвидо ван Россум сейчас работает в Dropbox, где целая команда под его началом трудится над свежим высокоскоростным интерпретатором Python, который на сей раз называется Pyston. Помимо тысячной версии искажения названия нежно нами любимого языка, он может похвастаться тем, что работает на LLVM с использованием самых современных течений в реализации JIT-компиляции.
Пока что эта реализация находится довольно в зачаточном состоянии, но, по слухам, вполне себе используется для конкретных внутренних проектов в Dropbox, а также, по уверениям разработчиков, должна сделать серьезный шаг вперед с точки зрения производительности (даже по сравнению с CPython). Но главный интерес она может представлять в том, что это своеобразный «лабораторный полигон для испытаний», на котором разработчики играют с различными технологиями — например, там в качестве подключаемого плагина можно использовать альтернативу GIL под названием GRWL или Global Read-Write Lock, которая якобы решает часть старых добрых проблем своего прародителя. Суть в том, что, в отличие от блокирования всего и вся (то есть, грубо говоря, обычного мьютекса, как оно устроено в GIL), он вводит разделение захватных операций на чтение и запись, что позволяет‑таки нескольким потокам получать одновременный доступ к данным, не портя их. Еще можно упомянуть так называемый OSR — On-Stack Replacement, который является своеобразной внутренней магией для запуска «тяжелых» методов (похожая штука используется в JavaScript). Такие дела.
Виртуальная реальность
Jython
Jython — не путать с JPython, похожим проектом, но развивающимся довольно вяло! — реализация Python, позволяющая в коде на Python вовсю и с удовольствием пользоваться почти всеми примитивами Java и ощутить преимущества JVM по максимуму. Выглядит это приблизительно так (пример из стандартной документации):
Устройство CPython. Доклад Яндекса
Мы публикуем конспект вступительной лекции видеокурса «Бэкенд-разработка на Python». В ней Егор Овчаренко egorovcharenko, тимлид в Яндекс.Такси, рассказал о внутреннем устройстве интерпретатора CPython.
Почему Python?

* insights.stackoverflow.com/survey/2019
** очень субъективно
*** интерпретация исследования
**** интерпретация исследования
Давайте начнем. Почему Python? На слайде есть сравнение нескольких языков, которые сейчас используются в бэкенд-разработке. Но если кратко, в чем преимущество Python? На нем можно быстро писать код. Это, конечно, очень субъективно — люди, которые круто пишут на C++ или Go, могут с этим поспорить. Но в среднем писать на Python быстрее.
В чем минусы? Первый и, наверное, основной минус — Python медленнее. Он может быть медленнее других языков в 30 раз, вот исследование на эту тему. Но его скорость зависит от задачи. Есть два класса задач:
— CPU bound, задачи, зависящие от процессора, ограниченные по CPU.
— I/O bound, задачи, ограниченные вводом-выводом: или по сети, или в базах данных.
Если вы решаете задачу CPU bound, то да, Python окажется медленнее. Если I/O bound, а это большой класс задач, то для понимания скорости выполнения вам надо запускать бенчмарки. И, возможно, сравнивая Python с другими языками, вы даже не заметите разницы в производительности.
Кроме того, Python обладает динамической типизацией: интерпретатор в момент компиляции не проверяет типы. В версии 3.5 появились type hints, позволяющие статически указывать типы, но они не очень строгие. То есть некоторые ошибки вы будете отлавливать уже в продакшене, а не на этапе компиляции. У других популярных языков для бэкенда — Java, C#, C++, Go — типизация статическая: если вы в коде передаете не тот объект, который нужно, компилятор вам об этом сообщит.
Если чуть более приземленно, как используется Python в продуктовой разработке Такси? Мы движемся в сторону микросервисной архитектуры. У нас уже 160 микросервисов, именно продуктовых — 35, 15 из них на Python, 20 — на плюсах. То есть мы сейчас пишем или только на Python, или на плюсах.
Как мы выбираем язык? Первое — требования по нагрузке, то есть смотрим, потянет Python или нет. Если он тянет, тогда мы смотрим на компетенцию разработчиков команд.
Сейчас хочется поговорить про интерпретатор. Как работает CPython?
Устройство интерпретатора
Может возникнуть вопрос: зачем нам знать, как работает интерпретатор. Вопрос валидный. Вы вполне можете писать сервисы, не зная, что под капотом. Ответы могут быть такими:
1. Оптимизация под высокую нагрузку. Представьте, что у вас есть сервис на Python. Он работает, нагрузка невысокая. Но однажды вам приходит задача — написать ручку, готовую к высокой нагрузке. От этого не уйти, не переписывать же весь сервис на C++. Итак, вам нужно оптимизировать сервис под высокую нагрузку. Понимание того, как работает интерпретатор, может в этом помочь.
2. Отладка сложных случаев. Допустим, сервис работает, но в нем начинает «утекать» память. У нас в Яндекс.Такси такой случай был буквально недавно. Каждый час сервис выедал 8 ГБ памяти и падал. Надо разбираться. Дело в языке, в Python. Требуется знание, как работает управление памятью в Python.
3. Это пригодится, если вы будете писать сложные библиотеки или сложный код.
4. И вообще — считается хорошим тоном знать инструмент, с которым вы работаете, на более глубоком уровне, а не просто как пользователь. В Яндексе это ценится.
5. Про это задают вопросы на собеседованиях, но дело даже не в этом, а в вашем общем IT-кругозоре.

Давайте кратко вспомним, какие бывают виды трансляторов. У нас бывают компиляторы, а бывают интерпретаторы. Компилятор, как вы, наверное, знаете, — это штука, которая переводит ваш исходный код сразу в машинный. Интерпретатор скорее переводит сначала в байт-код, а потом уже его исполняет. Python — интерпретируемый язык.
Байт-код — некий промежуточный код, который получается из исходного. Он не привязан к платформе и выполняется на некой виртуальной машине. Почему виртуальная? Это не настоящая машина, а некая абстракция.

Каких типов бывают виртуальные машины? Регистровые и стековые. Но здесь надо запомнить не это, а то, что Python — стековая машина. Дальше мы посмотрим, как работает стек.
И еще одна оговорка: здесь мы будем говорить только о CPython. CPython — референсная имплементация Python, написанная, как можно догадаться, на C. Используется как синоним: когда мы говорим о Python, мы обычно говорим о CPython.
Но также есть другие интерпретаторы. Есть PyPy, который использует JIT-компиляцию и ускоряет где-то в пять раз. Используется редко. Я, честно говоря, не встречал. Есть JPython, есть IronPython, который переводит байт-код для Java Virtual Machine и для дотнетовской машины. Это out of scope сегодняшней лекции — честно говоря, я с ним не сталкивался. Поэтому давайте посмотрим на CPython.

Посмотрим, что происходит. У вас есть исходник, строчка, вы хотите ее выполнить. Что делает интерпретатор? Строка — это просто набор символов. Чтобы сделать с ним нечто осмысленное, сначала код переводится в лексемы. Лексема — некий сгруппированный набор символов, идентификатор, число или какая-то итерация. Собственно, интерпретатор переводит код в лексемы.
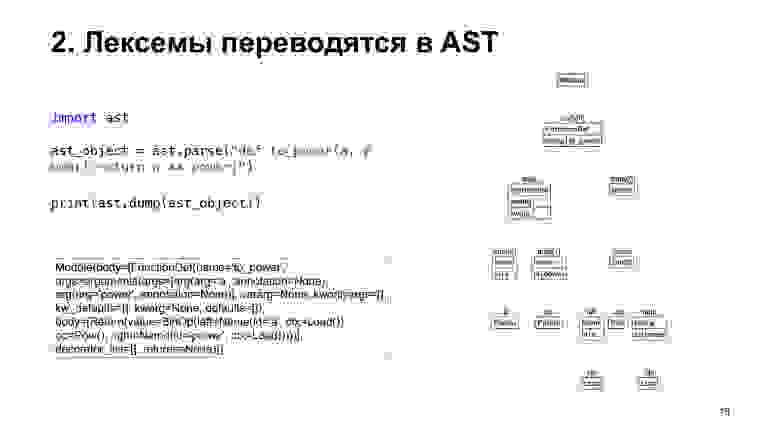
Дальше из этих лексем строится Abstract Syntax Tree, AST. Тоже пока не заморачивайтесь, это просто некие деревья, в узлах которых у вас операции. Допустим, в нашем случае есть BinOp, бинарная операция. Операция — возведение в степень, операнды: число, которое возводим, и степень, в которую возводим.
Дальше по этим деревьям уже можно строить какой-то код. Я пропускаю много шагов, есть шаг оптимизации, другие шаги. Потом эти синтаксические деревья переводятся уже в байт-код.
Здесь посмотрим поподробнее. Байт-код — это, как говорит нам это название, код, состоящий из байтов. А в Python начиная с 3.6 байт-код — это два байта.

Первый байт — это сам оператор, называется opcode. Второй байт — это аргумент oparg. Он выглядит как у нас сверху. То есть какая-то последовательность байт. Но в Python есть модуль dis, от слова Disassembler, с помощью которого мы можем посмотреть более человекочитаемое представление.
Как оно выглядит? Есть номер строчки исходника — самая левая единичка. Вторая колонка — это адрес. Как я говорил, байт-код в Python 3.6 занимает два байта, поэтому у нас все адреса четные и мы видим 0, 2, 4…
Load.name, Load.const — это уже сами опции кода, то есть коды тех операций, которые Python должен выполнить. 0, 0, 1, 1 — это oparg, то есть аргументы этих операций. Дальше посмотрим, как они выполняются.
(. ) Давайте посмотрим, как в Python происходит выполнение байт-кода, какие для этого есть структуры.

Если не знаете С, не страшно. Сноски даны для общего понимания.
В Python есть две структуры, которые нам помогают выполнять байт-код. Первая — CodeObject, вы видите ее краткое содержание. На самом деле структура больше. Это код без контекста. Значит, эта структура содержит, собственно, байт-код, который мы только что видели. Она содержит в себе названия переменных, использующиеся в этой функции, если функция содержит ссылки на константы, названия констант, что-то еще.

Следующая структура — FrameObject. Это уже контекст выполнения, та структура, которая уже содержит в себе значение переменных; ссылки на глобальные переменные; стек выполнения, о котором поговорим чуть позже, и много другой информации. Допустим, номер выполнения инструкции.
Как пример: если вы хотите вызвать функцию несколько раз, то CodeObject у вас будет один и тот же, а FrameObject на каждый вызов будет создаваться новый. У него будут свои аргументы, свой стек. Так они взаимосвязаны.

Что такое основной цикл интерпретатора, как выполняется байт-код? Вы видели, у нас был список этих opcode с oparg. Как это все выполняется? В Python, как в любом интерпретаторе, есть цикл, который выполняет этот байт-код. То есть на вход в него поступает фрейм, и Python просто по порядку идет по байт-коду, смотрит, что это за oparg, и переходит к его обработчику с помощью огромного switch. Здесь для примера приведен только один opcode. Для примера, у нас здесь есть binary subtract, бинарное вычитание, допустим, «A-B» у нас выполнится в этом месте.
Давайте расскажу, как работает binary subtract. Очень просто, это один из самых простых кодов. Функция TOP берет из стека самое верхнее значение, берет тоже с самого верхнего, не просто удаляет его из стека, и потом вызывается функция PyNumber_Subtract. Результат: слэш функция SET_TOP помещается обратно на стек. Если про стек не понятно, дальше будет пример.

Очень кратко о GIL. GIL — это мьютекс, который есть в Python на уровне процесса и который в основной цикл интерпретатора делает take этого мьютекса. И только после этого начинает выполнять байт-код. Это сделано для того, чтобы в один момент времени только один поток выполнял байт-код, чтобы защитить внутреннее устройство интерпретатора.
Допустим, забегая чуть дальше, что у всех объектов в Python есть количество ссылок на них. И если два потока будут менять это количество ссылок, то интерпретатор сломается. Поэтому есть GIL.
Вам об этом будут рассказывать в лекции по асинхронному программированию. Как это для вас может быть важно? Многопоточность не используется, потому что даже если вы сделаете несколько потоков, то в общем случае у вас будет выполняться только один из них, байт-код будет выполняться в одном из потоков. Поэтому либо используйте мультипроцессность, либо сишное расширение, либо что-то еще.

Краткий пример. Вы можете спокойно исследовать этот фрейм из Python. Есть модуль sys, у которого есть функция подчеркивания get_frame. Вы можете получить фрейм и посмотреть, какие переменные есть. Есть инструкция. Это больше для обучения, в реальной жизни я его не применял.
Давайте для понимания попробуем посмотреть, как работает стек виртуальной машины Python. У нас есть некий код, довольно простой, который непонятно что делает.

Слева код. Желтым выделена часть, которую мы сейчас рассматриваем. Во второй колонке у нас байт-код этого кусочка. В третьей колонке — фреймы со стеками. То есть стек выполнения у каждого FrameObject свой.
Что делает Python? Идет просто по порядку, по байт-коду, по средней колонке, выполняет и работает со стеком.

У нас выполнился первый opcode, который называется LOAD_CONST. Он загружает константу. Мы пропустили часть, там создается CodeObject, и у нас где-то в константах был некий CodeObject. Python загрузил его на стек с помощью LOAD_CONST. У нас теперь на стеке в этом фрейме есть объект CodeObject. Можем идти дальше.

Потом Python выполняет opcode MAKE_FUNCTION. MAKE_FUNCTION, очевидно, делает функцию. Он ожидает, что на стеке у вас был CodeObject. Он производит некие действия, создает функцию и кладет функцию обратно на стек. Теперь у вас FUNCTION вместо CodeObject, который был на стеке фрейма. И теперь эту функцию нужно поместить в перемененную to_power, чтобы вы могли к ней обращаться.

Выполняется opcode STORE_NAME, он помещается в переменную to_power. На стеке у нас была функция, теперь это переменная to_power, вы можете к ней обращаться.
Дальше мы хотим напечатать 10 + значение этой функции.

Что делает Python? Это преобразовалось в байт-код. Первый opcode у нас LOAD_CONST. Мы загружаем десятку на стек. На стеке появилась десятка. Теперь надо выполнить to_power.

Функция выполняется следующим образом. Если она с позиционными аргументами — остальное пока не будем смотреть, — то сначала Python кладет саму функцию на стек. Потом он кладет все аргументы и вызывает CALL_FUNCTION с аргументом количества аргументов функции.
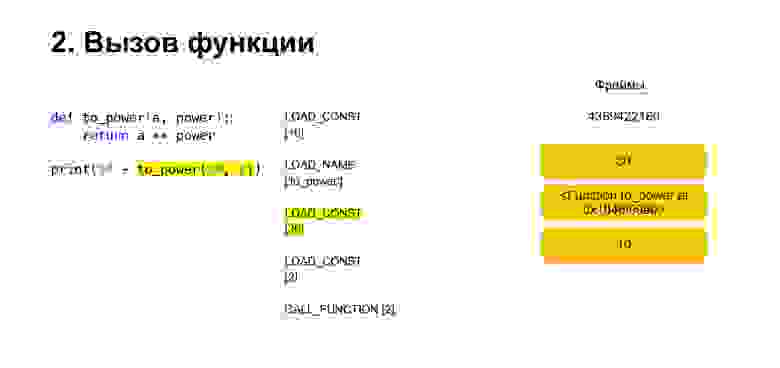
Загрузили на стек первый аргумент, это функция.

Загрузили на стек еще два аргумента — 30 и 2. Теперь у нас на стеке функция и два аргумента. Верхушка стека у нас сверху. CALL_FUNCTION у нас ожидает. Мы говорим: CALL_FUNCTION (2), то есть у нас функция с двумя аргументами. CALL_FUNCTION ожидает, что у нас на стеке будет два аргумента, после них функция. У нас так и есть: 2, 30 и FUNCTION.

У нас, соответственно, тот стек уходит, создается новая функция, в которой сейчас будет происходить выполнение.
Стек у фрейма свой. Создался новый фрейм под свою функцию. Он пока пустой.

Дальше происходит выполнение. Тут уже попроще. Нам нужно возвести A в степень power. Мы загружаем на стек значение переменной A — 30. Значение переменной power — 2.

И выполняется opcode BINARY_POWER.

У нас возводится одно число в степень другого и кладется на стек обратно. Получилось 900 на стеке функции.
Следующий opcode RETURN_VALUE возвратит значение со стека в предыдущий фрейм.

Так происходит выполнение. Функция завершилась, фрейм, скорее всего, очистится, если у него нет ссылок, и на фрейме предыдущей функции будет два числа.
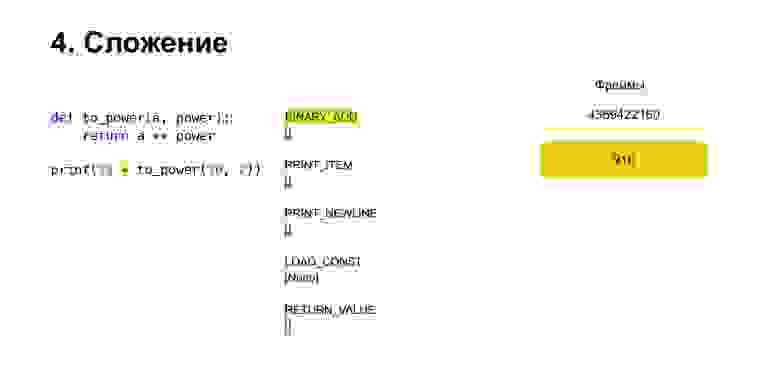
Дальше все примерно так же. Происходит сложение.

(. ) Давайте поговорим про типы и PyObject.
Типизация

Объект — сишная структура, в которой есть два основных поля: первое — количество ссылок на этот объект, второе — тип объекта, естественно, ссылка на тип объекта.
Другие объекты наследуются от PyObject путем включения его в себя. То есть если мы посмотрим на float, число с плавающей точкой, структурка там PyFloatObject, то у него есть HEAD, который является структурой PyObject, и, дополнительно, данные, то есть double ob_fval, где хранится значение самого этого float.

А это уже тип объекта. Мы только что смотрели в PyObject тип, это структура, которая обозначает тип. По сути это тоже сишная структура, которая содержит в себе указатели на функции, реализующие поведение этого объекта. То есть там очень большая структура. У нее указаны функции, которые вызываются, если вы, допустим, хотите сложить два объекта этого типа. Или хотите вычесть, вызвать этот объект или создать его. Все, что вы можете сделать с типами, должно быть указано в этой структуре.

Для примера посмотрим на int, целые числа в Python. Тоже очень сокращенная версия. Что нам может быть интересно? У int есть tp_name. Видно, что есть tp_hash, мы можем получить hash int. Если мы вызовем hash от int, вызовется эта функция. tp_call у нас ноль, не определен, это значит, что мы не можем вызвать int. tp_str — приведение к строке не определено. В Python есть функция str, которая может привести к строке.
На слайд это не попало, но вы все уже знаете, что int все-таки можно напечатать. Почему здесь ноль? Потому что есть еще tp_repr, в Python две функции проведения строки: str и repr. Более подробное приведение к строке. Оно на самом деле определено, просто на слайд не попало, и вызовется оно, если вы, собственно, будете приводить к строке.
В самом конце мы видим tp_new — функцию, которая вызывается при создании этого объекта. tp_init у нас ноль. Все мы знаем, что int — не изменяемый тип, immutable. После создания его изменять, инициализировать смысла нет, поэтому там нолик.

Для примера также посмотрим на Bool. Как кто-то, может быть, из вас знает, Bool в Python на самом деле наследуется от int. То есть вы можете Bool складывать, делить друг с другом. Этого делать, конечно, нельзя, но можно.
Мы видим, что есть tp_base — указатель на базовый объект. Все помимо tp_base — единственные вещи, которые были переопределены. То есть у него свое имя, своя функция представления, где как раз пишется не число, а true или false. Представление в виде Number, там переопределяются некоторые логические функции. Docstring своя и создание свое. Все остальное идет от int.

Очень кратко расскажу про списки. В Python список — это динамический массив. А динамический массив — это массив, который работает так: вы инициализируете область памяти заранее с какой-то размерностью. Туда добавляете элементы. Как только количество элементов превысит этот размер, вы его расширяете с неким запасом, то есть не на единичку, а на какое-то значение больше единички, чтобы была хорошая asin-точка.
В Python размер растет как 0, 4, 8, 16, 25, то есть по какой-то формуле, которая позволяет нам вставку сделать ассимптотически за константу. И можно посмотреть, есть выдержка из сишной функции вставки в список. То есть мы делаем resize. Если у нас не resize, мы выкидываем ошибку и присваиваем элемент. В Python это обычный динамический массив, реализованный на C.
(. ) Давайте кратко поговорим про словари. Они в Python везде.
Словари
Мы все знаем, в объектах весь состав классов содержится в словарях. Очень многие вещи на них основаны. Словари в Python в хеш-таблице.

Если кратко, как работает хеш-таблица? Есть некие ключи: timmy, barry, guido. Мы хотим их положить в словарь, прогоняем каждый ключ через хеш-функцию. Получается хеш. Мы по этому хешу находим бакет. Бакет — это просто номер в массиве элементов. Происходит конечное деление по модулю. Если бакет пустой, мы просто кладем в него нужный элемент. Если не пустой и там уже есть некий элемент, значит, это коллизия и мы выбираем следующий бакет, смотрим, свободный он или нет. И так до тех пор, пока не найдем свободный бакет.
Следовательно, чтобы операция добавления происходила за адекватное время, нам нужно постоянно держать какое-то количество бакетов свободными. Иначе при приближении к размеру этого массива мы будем очень долго искать свободный бакет, и всё будет тормозить.
Поэтому в Python эмпирически принято, что треть элементов массива всегда свободна. Если их количество больше двух третей, массив расширяется. Это не очень хорошо, потому что треть элементов тратится впустую, ничего полезного не хранится.

Ссылка со слайда
Поэтому с версии 3.6 в Python сделали такую штуку. Слева можно посмотреть, как было раньше. У нас есть разреженный массив, где хранятся эти три элемента. С 3.6 они решили сделать такой разреженный массив обычным массивом, но при этом хранить индексы элементов бакета в отдельном массиве indices.
Если мы посмотрим массив индексов, то в первом бакете у нас None, во втором лежит элемент с индексом 1 из этого массива и т. д.
Это позволило, во-первых, сократить использование памяти, во-вторых, мы еще бесплатно получили из коробки упорядоченный массив. То есть мы добавляем элементы в этот массив, условно, обычным сишным append, и массив автоматически упорядочен.
Есть интересная оптимизация, которую Python использует. Чтобы работали эти хеш-таблицы, нам нужно иметь операцию сравнения элементов. Представьте, мы поместили в хеш-таблицу элемент, а потом хотим взять элемент. Берем хеш, идем в бакет. Видим: бакет полный, там что-то есть. Но тот ли это элемент, который нам нужен? Может быть, когда он помещался, возникла коллизия и элемент на самом деле поместился в другой bucket. Поэтому мы должны сравнивать ключи. Если ключ не тот, мы применяем тот же механизм поиска следующего бакета, который используется при разрешении коллизий. И идем дальше.

Ссылка со слайда
Поэтому нам нужно иметь функцию сравнения ключей. В общем случае функция сравнения объектов может быть очень дорогой. Поэтому используется такая оптимизация. Сначала мы сравниваем айдишники элементов. ID в CPython — это, как вы знаете, положение в памяти.
Если айдишники совпадают, значит, это одинаковые объекты и, естественно, они равны. Тогда мы возвращаем True. Если нет, смотрим хеши. Хеш должен быть довольно быстрой операцией, если мы не переопределили как-то. Мы берем хеши от этих двух объектов, сравниваем. Если их хеши не равны, то объекты точно не равны, поэтому мы возвращаем False.
И только в очень маловероятном случае — если у нас хеши равны, но мы не знаем, тот ли это объект, — только тогда мы сравниваем сами объекты.
Небольшая интересная штука: нельзя ничего вставлять в ключи во время итерации. Это ошибка.

Под капотом в словаре есть такая переменная — version, в которой хранится версия словаря. Когда вы изменяете словарь, version меняется, Python это понимает и кидает вам ошибку.

Для чего словари могут использоваться на более практическом примере? У нас в Такси есть заказы, а у заказов — статусы, которые могут меняться. При изменении статуса вы должны выполнять некие действия: отправить смски, записывать заказы.
Эта логика у нас написана на Python. Чтобы не писать огромный if вида «if статус заказа такой-то, сделай то-то», есть некий dict, в котором ключ — это статус заказа. А к VALUE есть tuple, в котором содержатся все обработчики, которые надо выполнить при переходе в данный статус. Это распространенная практика, фактически — замена сишного switch.

Еще несколько вещей по типам. Расскажу про immutable. Это неизменяемые типы данных, а mutable — соответственно, изменяемые типы: дикты, классы, инстансы классов, листы и, может, что-то еще. Практически все остальное — строки, обычные числа — они immutable. Для чего нужны mutable-типы? Первое: они позволяют проще понимать код. То есть если вы в коде видите, что что-то tuple, вы понимаете, что дальше он не изменяется, и вам это позволяет проще читать код? Понимать, что будет дальше. В tuple ds не можете набрать элементы. Вы это будете понимать, и это поможет при чтении вам и всем людям, которые будут читать код за вами.
Поэтому есть правило: если вы что-то не будете менять, лучше используйте неизменяемые типы. Также это приводит к ускорению работы. Есть две константы, которые как раз использует tuple: pit_tuple, tap_tuple, max и СС. В чем смысл? Для всех tuple размера до 20 используется определенный способ выделения памяти, который ускоряет это выделение. И таких объектов каждого типа может быть до двух тысяч, очень много. Это гораздо быстрее, чем листы, поэтому если будете использовать tuple, у вас все будет быстрее.
Также есть проверки во время выполнения. Очевидно, если вы пытаетесь в объект что-то запиндить, а он не поддерживает эту функцию, то будет ошибка, некое понимание того, что вы сделали что-то не то. Ключами в дикте могут быть только объекты, у которых есть хеш, которые не изменяются во время жизни. Этому определению удовлетворяют только immutable-объекты. Только они могут быть ключами дикта.

Как это выглядит в C? Пример. Слева tuple, справа обычный list. Тут, естественно, видны не все отличия, а только те, которые хотел показать. В list в поле tp_hash у нас NotImplemented, то есть хеша у list нет. В tuple некая функция, которая вам действительно вернет хеш. Это как раз то, почему tuple в том числе может быть ключом дикта, а list — не может.
Следующее, что выделено, — это функция присваивания элемента, sq_ass_item. В list она есть, в tuple нолик, то есть вы в tuple, естественно, ничего не можете присвоить.

Еще одна вещь. Python ничего не копирует, пока мы его не попросим. Об этом тоже надо помнить. Если вы что-то хотите скопировать, используйте, допустим, модуль copy, у которого есть функция copy.deepcopy. В чем отличие? copy копирует объект, если это контейнерный объект, типа списка на одном уровне. Все ссылки, которые были в этом объекте, вставляются в новый объект. А deepcopy рекурсивно копирует все объекты внутри этого контейнера и дальше.
Или, если вы хотите быстро скопировать список, можно использовать слайс с одним двоеточием. У вас получится копия, такой шорткат просто.
(. ) Дальше поговорим про менеджмент памяти.
Менеджмент памяти

Возьмем наш модуль sys. В нем есть функция, которая позволяет посмотреть, задействует ли он какую-нибудь память. Если вы запустите интерпретатор и посмотрите на статистику изменения памяти, то увидите, что у вас создано очень много объектов, в том числе маленьких. И это только те объекты, которые в данный момент созданы.
На самом деле во время выполнения Python создает очень много маленьких объектов. И если бы мы для их выделения использовали стандартную сишную функцию malloc, то очень быстро бы уткнулись в то, что у нас память фрагментированная и, соответственно, выделение памяти работает медленно.

Из этого вытекает необходимость использовать свой менеджер памяти. Вкратце, как он работает? Python выделяет себе блоки памяти, которые называются арена, по 256 килобайт. Внутри он себе нарезает пулы по четыре килобайта, это размер страницы памяти. Внутри пулов у нас живут блоки разного размера, от 16 до 512 байт.
Когда мы пытаемся выделить объекту меньше 512 байт, Python выбирает каким-то своим способом блок, который подходит для этого объекта и размещает объект в этом блоке.
Если объект деаллоцируется, удаляется, то этот блок помечается как свободный. Но операционной системе он не отдается, и мы при следующей алокации можем в тот же блок записать этот объект. Это очень сильно ускоряет выделение памяти.

Освобождение памяти. Раньше мы видели структуру PyObject. У нее есть этот refcnt — счетчик ссылок. Работает очень просто. Когда вы берете референс на этот объект, Python увеличивает счетчик ссылок. Как только у вас объект, референс пропадает на него, вы деалоцируете счетчик ссылок.
То, что выделено желтым. Если refcnt не равен нулю, значит, мы там что-то делаем. Если refcnt равен нулю, то мы сразу же деаллоцируем объект. Не ждем никакого сборщика мусора, ничего, а прямо в этот момент очищаем память.
Если вы встретите метод del, он просто удаляет привязку переменной к объекту. А метод __del__, который вы можете определить в классе, вызывается, когда объект уже действительно удаляется из памяти. Вы вызовете del у объекта, но при этом, если у него еще есть ссылки, объект никуда не удалится. И его Finalizer, __del__, не вызовется. Хотя они называются очень похоже.
Краткая демка о том, как можно посмотреть количество ссылок. Есть наш любимый модуль sys, в котором есть функция getrefcount. Вы можете посмотреть количество ссылок на объект.

Расскажу подробнее. Делается объект. От него берется количество ссылок. Интересная деталь: переменная A указывает на TaxiOrder. Вы берете количество ссылок, у вас напечатается «2». Казалось бы, почему? У нас же одна ссылка на объект. Но когда вы вызываете getrefcount, этот объект бандится на аргумент внутри функции. Поэтому у вас уже есть две ссылки на этот объект: первая — переменная, вторая — аргумент функции. Поэтому печатается «2».
Дальше тривиально. Мы присваиваем еще одну переменную объекту, получаем 3. Потом удаляем эту привязку, получаем 2. Потом удаляем все ссылки на этот объект, и при этом вызывается финализатор, который напечатает нашу строчку.

(. ) Есть еще одна интересная особенность CPython, на которую нельзя закладываться и нигде в доках про это, кажется, не сказано. Целые числа используются часто. Было бы расточительно их каждый раз создавать заново. Поэтому самые частоиспользуемые числа, разработчики Python выбрали диапазон от –5 до 255, — они Singleton. То есть они созданы один раз, лежат где-то в интерпретаторе, и когда вы пытаетесь их получить, то получаете ссылку на один и тот же объект. Мы взяли A и B, единички, напечатали их, сравнили их адреса. Получили True. И у нас, допустим, 105 ссылок на этот объект, просто потому что сейчас получилось столько.
Если возьмем какое-то число больше — допустим, 1408, — у нас эти объекты не равны и ссылок на них, соответственно, две. А фактически одна.

Мы чуть-чуть поговорили про выделение памяти, про освобождение. Теперь поговорим про сборщик мусора. Для чего он нужен? Казалось бы, у нас есть число ссылок. Как только никто на объект не ссылается, мы можем его удалять. Но у нас могут быть циклические ссылки. Объект может ссылаться, допустим, сам на себя. Или, как в примере, может быть два объекта, каждый ссылается на соседа. Это называется цикл. И тогд эти объекты никогда могут не отдать ссылку на другой объект. Но при этом они, допустим, недостижимы из другой части программы. Нам надо их удалить, потому что они недоступны, бесполезны, но ссылки у них есть. Ровно для этого существует модуль garbage collector. Он детектит циклы и удаляет эти объекты.
Как он работает? Сначала кратко расскажу про поколения, а потом про алгоритм.
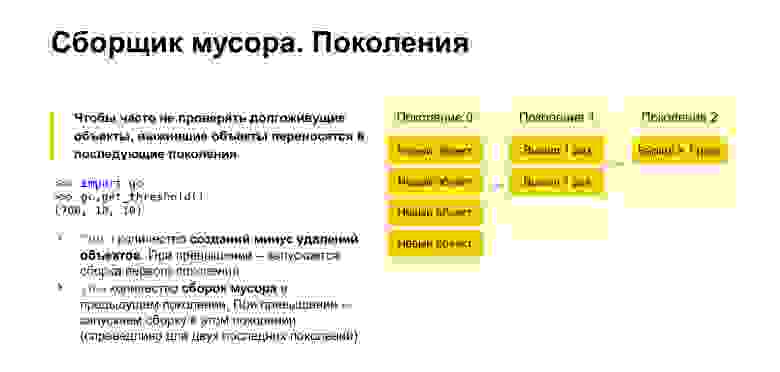
Для оптимизации скорости garbage collector в Python — он generational, то есть работает с помощью поколений. Есть три поколения. Зачем они нужны? Понятно, что те объекты, которые создались совсем недавно, с большей вероятностью нам не нужны, чем долгоживущие объекты. Допустим, в ходе функций у вас что-то создается. Скорее всего, при выходе из функции оно будет не нужно. То же самое с циклами, с временными переменными. Все эти объекты надо чистить чаще, чем те, которые живут давно.
Поэтому в нулевое поколение помещаются все новые объекты. Периодически происходит очистка этого поколения. В Python есть три параметра. На каждое поколение свой параметр. Вы можете их получить, заимпортить garbage collector, вызвать функцию get_threshold, и получить эти пороговые значения.
По дефолту там 700, 10, 10. Что такое 700? Это количество созданий объектов минус количество удалений. Как только оно превышает 700, запускается сборка мусора в новом поколении. А 10, 10 — это количество сборок мусора в предыдущем поколении, после которого нам надо запустить сборку мусора в текущем поколении.
То есть когда мы нулевое поколение очистим 10 раз, то запустим сборку в первом поколении. Очистив первое поколение 10 раз, запустим сборку во втором поколении. Соответственно, объекты перемещаются из поколения в поколение. Если выживают — перемещаются в первое поколение. Если выжили при сборке мусора в первом поколении — перемещаются во второе. Из второго поколения уже никуда не перемещаются, остаются там навсегда.
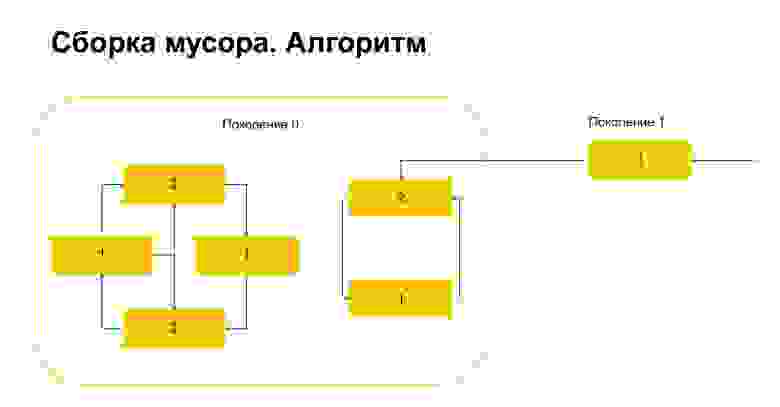
Как работает сборка мусора в Python? Допустим, мы запускаем сборку мусора в поколении 0. У нас есть некие объекты, у них циклы. Есть группа объектов слева, которые друг на друга ссылаются, и группа справа, тоже ссылается друг на друга. Важная деталь — на них также есть ссылка из поколения 1. Как Python детектит циклы? Сначала у каждого объекта создается временная переменная и в нее записывается количество ссылок на этот объект. На слайде это отражено. У нас на объект сверху две ссылки. А вот на объект из поколения 1 кто-то ссылается снаружи. Python это запоминает. Потом (важно!) он проходит по каждому объекту внутри поколения и удаляет, декрементирует счетчик на число ссылок внутри этого поколения.
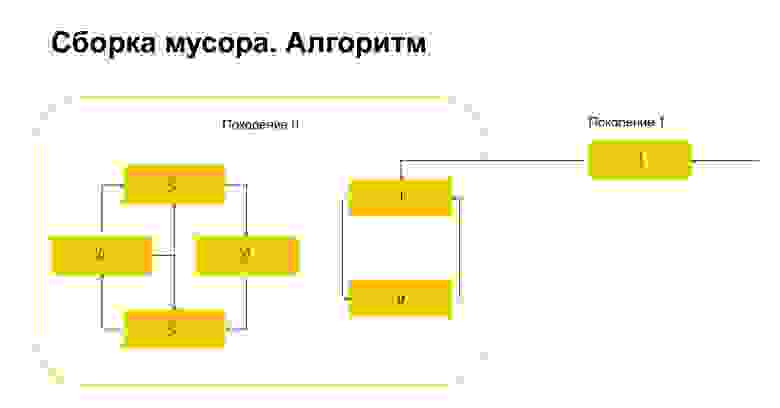
Вот что получилось. У объектов, которые ссылаются только друг на друга внутри поколения, эта переменная автоматически по построению стала равной нулю. Единичка только у объектов, на которые есть ссылки снаружи.
Что делает потом Python? Он, поскольку здесь единичка, понимает, что на эти объекты есть ссылка снаружи. И мы не можем удалить ни этот объект, ни этот, потому что иначе у нас получится невалидная ситуация. Поэтому Python переносит эти объекты в поколение 1, а все, что осталось в поколении 0, он удаляет, очищает. Про garbage collector все.
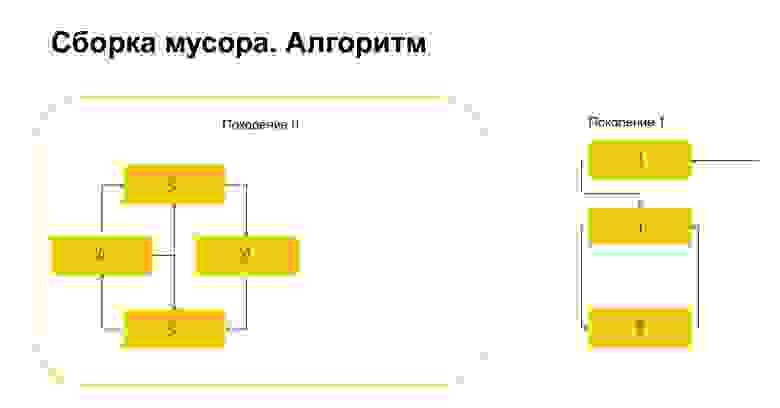
(. ) Идем дальше. Очень кратко расскажу про генераторы.
Генераторы

Здесь, к сожалению, введения в генераторы не будет, но давайте попробую рассказать, что такое генератор. Это некая, условно говоря, функция, которая запоминает контекст своего выполнения с помощью слова yield. На этом месте она возвращает значение и запоминает контекст. Вы можете к ней потом вновь обращаться и получать значение, которое оно выдает.
Что с генераторами можно делать? Можно делать yield генератора, это вам вернет значения, запомнит контекст. Можно делать return для генератора. В этом случае у вас кинется эксепшен StopIteration, value внутри которого будет содержать значение, в данном случае Y.
Менее известный факт: вы можете отправить генератору некие значения. То есть вы вызываете у генератора метод send, и Z — см. пример — будет значением выражения yield, которое вызовет генератор. Если вы хотите генератором управлять, вы можете туда передавать значения.
Также вы можете кидать туда исключения. То же самое: берете generator object, делаете throw. Кидаете туда ошибку. У вас на месте последнего yield зарейзится ошибка. И close — вы можете закрывать генератор. Тогда рейзится эксепшен GeneratorExit, и ожидается, что генератор больше ничего yield’ить не будет.

Здесь я просто хотел рассказать про то, как это устроено в CPython. У вас в генераторе на самом деле хранится фрейм выполнения. И как мы помним, FrameObject содержит весь контекст. Из этого, кажется, понятно, как контекст сохраняется. То есть у вас в генераторе просто есть фрейм.

Когда вы выполняете функцию генератора, как Python понимает, что вам нужно не выполнить ее, а создать генератор? В CodeObject, который мы смотрели, есть флаги. И когда вы вызываете функцию, Python чекает ее флаги. Если есть флаг CO_GENERATOR, он понимает, что функцию не надо выполнять, а надо только создать генератор. И он его создает. Функция PyGen_NewWithQualName.

Как происходит выполнение? Из GENERATOR_FUNCTION генератор сначала вызывает GENERATOR_Object. Потом вы GENERATOR_Object можете уже с помощью next вызывать, получать следующее значение. Как происходит вызов next? Из генератора берется его фрейм, он запоминается в переменную F. И отправляется в основной цикл интерпретатора EvalFrameEx. У вас происходит выполнение, как в случае обычной функции. Мапкод YIELD_VALUE используется, чтобы вернуть, поставить на паузу выполнение генератора. Он запоминает весь контекст во фрейме и прекращает выполнение. Это была предпоследняя тема.
(. ) Кратко вспомним, что такое исключения и как они используются в Python.
Исключения

Исключения — способ обработки ошибочных ситуаций. У нас есть блок try. Мы можем в try записать те вещи, которые могут возбуждать исключения. Допустим, с помощью слова raise мы можем зарейзить ошибку. С помощью except можем ловить определенные типы исключений, в данном случае SomeError. С помощью except мы без выражения ловим все исключения вообще. Блок else используется реже, но он есть и выполнится, только если ни одного исключения не было возбуждено. Блок finally выполнится в любом случае.
Как работают исключения в CPython? Кроме стека выполнения, у каждого фрейма есть еще стек блоков. Лучше рассказать на примере.


Стек блоков — это стек, в котором пишутся блоки. У каждого блока есть тип, Handler, обработчик. Handler — это адрес байт-кода, на который надо перейти, чтобы обработать этот блок. Как все работает? Допустим, у нас есть некий код. Мы сделали блок try, у нас есть блок except, в котором мы ловим исключения RuntimeError, и блок finally, который должен быть в любом случае.
Это все вырождается вот в такой байт-код. В самом начале байт-кода на блоке try мы видим два два opcode SETUP_FINALLY с аргументами to 40 и to 12. Это адреса обработчиков. Когда выполняется SETUP_FINALLY, в стек блоков помещается блок, в котором написано: чтобы обработать меня, перейди в одном случае на 40-й адрес, в другом — на 12-й.
12 ниже по стеку — это except, строчка, где есть else RuntimeError. Значит, когда у нас будет исключение, мы будем смотреть стек блоков в поиске блока с типом SETUP_FINALLY. Найдем блок, в котором есть переход на адрес 12, перейдем туда. И там у нас происходит сравнение исключения с типом: мы проверяем, равен ли тип исключения RuntimeError или нет. Если равен — мы выполняем его, если нет — прыгаем куда-то в другое место.
FINALLY — следующий блок в стеке блоков. Он у нас выполнится, если у нас будет еще какой-то exception. Тогда дальше пойдет поиск по этому стеку блоков, и мы дойдем до следующего блока SETUP_FINALLY. Там будет обработчик, который сообщает нам, например, адрес 40. Мы прыгаем на адрес 40 — по коду видно, что это блок finally.

Возьмем такую врезку на C. Мы видим, как происходит деление. И есть проверка, что если B равно нулю, а делить на ноль не хочется, то мы запоминаем исключение и возвращаем NULL. Значит, произошла ошибка. Следовательно, все остальные функции, которые находятся выше по стеку вызовов, тоже должны будут выкинуть NULL. Мы это увидим в основном цикле интерпретатора и прыгнем сюда.

Это раскрутка стека. Тут всё, как я говорил: мы просматриваем весь стек блоков и проверяем, что его тип равен SETUP_FINALLY. Если это так — прыгаем по Handler, очень просто. На этом, собственно, и всё.



